Merci à M. Pierre-Luc Daoust pour l’édition du vidéo, M. Éric Bélanger pour la gestion des sites web et YouTube, et bien sûr l’inconparable M. Martial Bigras, d’avoir créé les conditions gagnantes afin que la présentation puisse prendre place! (Et un grand merci à M. Éric Cothenet pour son encouragement initial!)
Thanks are due to M. Pierre-Luc Daoust for processing the video, M. Éric Bélanger for the website and YouTube channel management, and of course the incomparable M. Martial Bigras, for having created and maintained such a great club where great presentations, as well as my humble presentation, could be made! (And of course a big thank you to M. Éric Cothenet for his initial support!)
I started using the internet in 1994, using a dial-up account that offered access through a telnet unix terminal using the command-line.
One of the commands / pieces of software I discovered was talk, a basic one-on-one chat programme:
talk programme
Besides amusing myself by using it to chat with my brother when he was online at the same time as I, it actually had a useful application.
I was involved in Rovers at the time, a young adults organization, and I had put up a web page describing the Rover Crew to which I belonged on my website. I was contacted by a Rover in Adelaide, Australia by email in the spring of 1995; he’d found my website, and he was temporarily moving to Montreal in Canada where I live, to work. He was looking for a few building blocks for life outside of his new job in a new country. We negotiated, by email, for a live chat; as I recall, he had suggested IRC, but I was not familiar with IRC at the time, so I suggested talk, to which he reluctantly but nonetheless agreed. (A minor hiccup was that I had suggested a time for the chat as a function of GMT; I was online at what I thought was the appointed hour, but he only showed up an hour later. I was fortunately still online; I figure that I hadn’t properly taken Daylight Savings Time into account when I suggested the hour.)
I live in Montreal (A tag, upper right) in eastern Canada; my friend was living in Adelaide (B tag, lower left) in southern Australia
After our little chat, we continued exchanging emails leading up to his arrival in Montreal. He came to Montreal, joined my Rover Crew, stayed for about three and a half years, and I adopted his cat when he moved back to Australia.
What this post is really about:
Fast forward to early 2026, and I wanted to contribute a short presentation at my Linux club. I looked at some of the recent short presentations on regular everyday linux commands, and I was inspired to install talk on a couple of my machines, document the process, and put together a short presentation in which I would replicate the installation live while inviting others to install talk at the same time as I, and then initiate a chat with someone in the room.
This led me down a rabbit hole towards apparent failure (with a surprise ending).
(Note:Most of the screencaps for this post were created ex-post facto, be they principally on one computer, or on a second computer.)
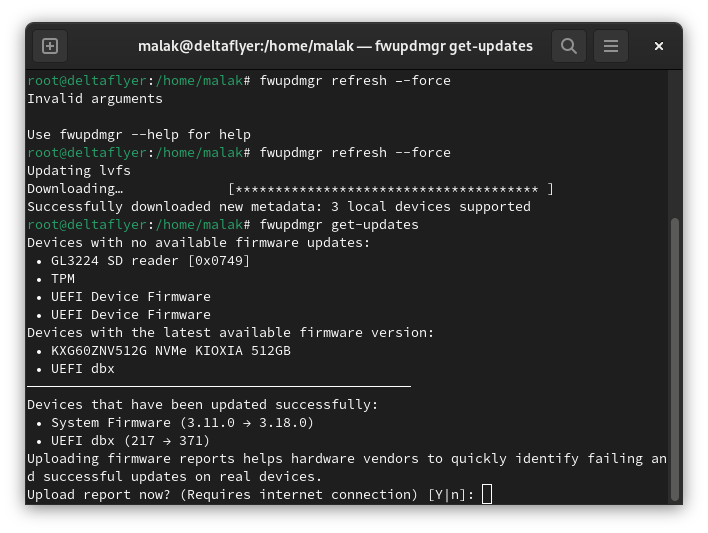
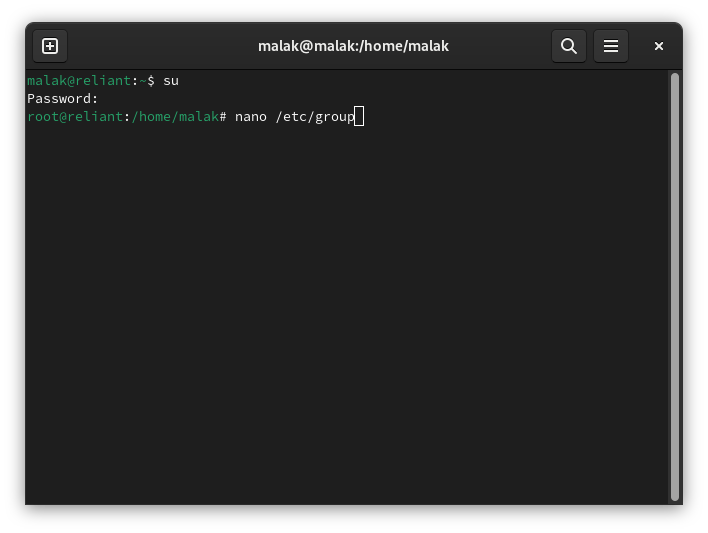
I did a quick web search on talk, and I found a page at the Geeks for Geeks website(here’s my archive) — critically, dated in July, 2025. This site was a great source of inspiration: It contended that installing talk could be done, using my Linux distribution (Fedora), the article was relatively current, and the procedure seemed quite simple.
The first hint that the Geeks for Geeks procedure wasn’t going to work should have been that for Fedora (and RHEL), the article invoked the yum command. Despite the fact that Fedora has been using dnf since Fedora 22 in 2015, and RHEL 8 in 2019 (DNF(software) on Wikipedia — here’s my archive), this didn’t faze me since other than noticing it, I knew of yum and its historic use — in fact, I was around using yum during a substantial period of said historic use — and in my mind the two are interchangeable. (Indeed they are to a nominal degree, since at least for RHEL, according to the Geeks for Geeks website, yum is aliased to dnf (here’s my archive.) Oh, no matter that the same website, despite knowing that yum is obsolete, is still using it in its articles as a current command. 🙂 )
note: for the rest of the article, whenever an instruction needs to be done with root privileges, I did so directly as root, instead of using the sudo command.
Installing talk and talk-server:
I began following the instructions for installing talk:
dnf installtalk from the Fedora repositories
… and for installing talk-server:
dnf install talk-server from the Fedora repositories
This seemed good. I figured that if the software was in the Fedora repositories and that it installed, it should work.
talk package page in the Fedora repositories
Invoking the xinetd daemon:
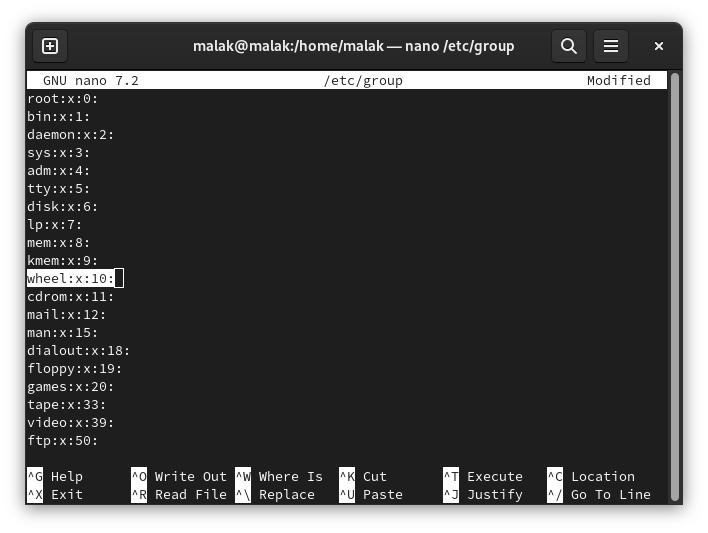
I then followed the instructions to create two files called talk and ntalk in the /etc/xinetd.d directory. Another hint that this exercise wouldn’t work was that the /xinetd.d directory didn’t exist on my system, and that I had to create it; but, I forged on. I created the directory, and then the specified files:
/etc/xinetd.d/talk file created
/etc/xinetd.d/ntalk file created
The next instruction was to restart the xinetd.d server:
Failed effort to restart the xinetd.d service
Receiving an error message that the xinetd.d.service was not found finally made me a bit suspicious, and I checked if and when the xinetd.d service had been deprecated in Fedora. The last reference in Fedora I could find was the xinetd.d package for Fedora 33 (here’s my archive), while a post in Reddit suggested, without apparent reference, that xinetd.d was deprecated in Fedora 34 — in April, 2020, about five full years before the Geeks for Geeks article describing how to install the talk command was written!
Reddit comment stating (without reference) that xinetd.d was deprecated in Fedora 34
So at this point, there were two prior points in time at which I should have figured that the Geeks for Geeks procedure lacked a solid basis for reliability, in addition to this last definitive hint.
ChatGPT consulted:
Despite being suspicious of AI given the current hype surrounding it, and widespread stories of its (sometimes more than) occasional invented results (here’s my archive), I consulted ChatGPT.
Consulting ChatGPT on the subject
So the underlying project objective appeared to have some merit … but at this point, I began diving into a rabbit hole: The obvious rabbit hole of installing legacy software on a modern OS, and perhaps less obviously, a rabbit hole involving placing a lot of faith in AI. (As in, despite using Linux for almost 20 years, and having been exposed to UNIX for over 10 years before that, I don’t think I know enough about Linux to fully evaluate the advice and instructions ChatGPT gave, and whether its apparent confidence in giving advice at each step, let alone its ultimate determination, were based in any merit.)
To wit: After ChatGPT suggested that I confirm the presence of the binaries I said I’d installed, it suggested that I create some socket files, as well as some service units, to enable the new services, and finally check on their status.
Setting up sockets:
Creating socket files
Enabling the socket files
Checking status
Checking status
Services were enabled:
Reloading and enabling the sockets
Firewall changes:
Ports 517/udp and 518/udp were activated in my firewalls (error messages betray the fact that the screenshot is a recreation ex post facto 🙂 ):
Adding the ports to the firewall
I tried start up talk again at this point … and it didn’t work. Apparently, the “Unit talk socket has a bad unit file setting” and the “Unit ntalk.socket has a bad unit file setting”.
Correcting the sockets files for systemd:
The socket and service files were corrected:
Sockets units settings to be corrected
Service units file to be corrected
Daemons were reloaded, and enabled with:
# systemctl enable –now talk.socket ntalk.socket
However, a status check:
#systemctl status talk.socket ntalk.socket
revealed:
Errors after performing a systemd status check
ChatGPT diagnosed this as my having previously incorrectly created a talk.service file.
Correcting the talk.service and ntalk.service files
Daemons were reloaded, and the status checked; this time, with the above fix, the setup seemed to work properly.
Instructions restated, and installing on a second machine (my laptop):
At this point, with ChatGPT’s blessing and a restatement of the updated instructions …
Midway summarized instructions so that I could install talk on a second computer
… I repeated the process on a second laptop, connected to the same network.
Once the installation was complete on the second laptop, I typed in:
$talk malak@malak.local
at the command line from my laptop:
Trying to initiate the talk command from my laptop, toward my desktop
No route to host:
This failed with a “no route to host” error message from each machine. I reported back to ChatGPT:
ChatGPT went on to say how to get the local ip address for each computer on the network, because the firewalls on each machine were rejecting access to UDP addresses, recommending that I therefore use the individual computers’ IP address instead of the local computer names.
Using IP addresses instead of hostnames:
On each computer, at the command line (as a regular user) I used:
$ip addrshow
Determinging the IP address on my desktop, an exercise repeated on my laptop
… and to try running:
$talk user@192.168.X.Y on one machine, and:
$talk user@192.168.X.Z on the other machine,
such that I substitute in my username and the respective addresses from above.
This again failed.
Limiting to IPv4:
ChatGPT suggested that if that were to fail, that I should modify the following files:
/etc/systemd/system/talk.socket
/etc/systemd/system/ntalk.socket
to listen on either port 517 (talk — client) or 518 (ntalk — server), then reload and restart the services:
Checking if SELinux is in play:
ChatGPT also suggested that I run:
# ausearch -m AVC -ts recent
to check if SELinux was the issue. It wasn’t.
Checking to see if SELinux was blocking the connections
So I ran the talk command again. This time, I got a different error message with the talk client:
the other machine does not recognize us
So once again, I consulted ChatGPT.
Modifying the /etc/hosts files:
The /etc/hosts files on each computer were edited with the respective information for each computer:
/etc/hosts file on both systems modified to specify the local IP of each
I tried again, as per ChatGPT’s directions, to try from each computer, and my connection was refused, in the following case, my laptop:
Connection refused by my desktop
Note that I finally realized later that this might relegate the use of the talk command on these machines, on my home network — meaning, that it would likely not be a useful fix for general use, at least not without either a script that integrates all the above (and probably more), including a way to include other computers in a range of IP addresses, or a rewrite of the software. (No doubt a dubious effort, given the number of chat programmes that have been written, reworked, and so on, since talk was commonly in use, decades ago.)
Correcting to allow receiving messages:
ChatGPT suggested a fix in the mesg command:
Invoking the mesg command
As well, ChatGPT recommended to modify the /etc/profile file to include the mesg y command:
Adding “mesg y” to /etc/profile
I still couldn’t get talk to work. “Your party is refusing messages”.
Messages refused:
ChatGPT said to make sure that the terminal on both systems was writable with:
chmod g+w $(tty)
Changing permissions for the terminal
Trying two terminals on one machine:
At this point I think that I was losing track of ChatGPT’s suggestions and not properly implementing them all.
Nonetheless, in skipping a few steps, I thought I was following the suggestions when I chose one machine — in this case, my desktop — and opened up two terminals, and tried to initiate a chat on the same machine between both terminals:
Two terminals on the same machine, with one instance of talk already active (but having seen what comes up on the next screenshot)
Once set up, and ready to try, I had the command line command set up:
Connection refused between two terminals on the same machine
Messages were still being refused, even when coming from within the same computer.
Waving the white flag of surrender:
At this point, I decided that it was time to raise the white flag of surrender, on the basis that the talk command, despite being present in the repositories for Fedora 43 and nominally packaged for Fedora 43, is a legacy package no longer intended for current general use.
But wait! There’s more!
Rereading ChatGPT’s instructions later — during the construction of this post and then tested during one of the many re-reads and edits of this post — I realized that ChatGPT’s instructions included trying to use a “real” tty console as part of the test, not simply two Gnome graphical environment terminals.
Missed suggestion to use the console (tty)
Whaddya know: It worked there!
Looking around revealed four such terminals on my desktop, labelled tty3, tty4, tt5, and tt6, respectively accessed by Ctrl-Alt-F3, Ctrl-Alt-F4, Ctrl-Alt-F5, and Ctrl-Alt-F6. (Reminder to myself: To get out of the consoles, use Ctrl-Alt-F2.)
So first, I opened up a console at tty3 on my desktop, and I typed:
$talk malak
Which opened up the talk interface, and in which I typed a message:
Message typed on my desktop’s tty3 “hello / this is a test”
Then I opened up a console at tty4, and I was able to launch talk, finding the “hello” and “this is a test” messages from tty3 appearing in the lower section:
Message received on my desktop’s tty4 “hello / this is a test”
So this was an aha! moment.
Then, after entering a console on my laptop:
Logging into a console on my laptop
I initiated a talk session with my username on my laptop (assuming that I still needed to use IP addresses):
$talk malak@192.168.2.19
Starting a talk session on my laptop, calling a user on my desktop
… and on one of the console terminals on my desktop, I received the following message:
Message received on my desktop, originating from my laptop
This gave me new information: I could also use the computer names in addition to the IP addresses.
On the desktop, I therefore entered:
$talk malak@deltaflyer
… and I had the two machines, uhm, talk-ing to each other.
Message initiated on my laptop in the upper section: “hello this is a test from my laptop”, appearing in the lower section on my desktop
Final Thoughts:
First, to my eventual surprise, I learned that talk still works on Fedora — albeit only in “real” tty consoles. I haven’t checked how much of the above is required to make it work, but I have a few ideas about which are necessary, and which are not (for instance, use of computer names instead of requiring IP addresses is possible, although I’m not sure whether having modified the /etc/hosts file helped with that.)
Next, I may still have a presentation somewhere, perhaps characterized as a bit of an amusing cautionary tale regarding trying to install several decades-old, obsolete, legacy software on modern systems.
Perhaps, it might be an amusing tongue-in-cheek cautionary tale with a side of self-deprecation about trusting AI on subjects about which one doesn’t know enough; fortunately, it seems that ultimately, I was not led astray.
Perhaps, it could be presented as an amusing counterpoint to another presentation lauding the value of AI in a similar situation, being used by someone who knows more about the subject at hand (in this case, Linux) and how to better interpret the provided results — instead of simply trusting the AI blindly.
Or, perhaps, while I generally was not led astray and ChatGPT indeed did help me fulfill my goal … could the exercise act as an inspiration to learn about maintaining critical — and possibly migrating away from — legacy software on modern software and hardware? COBOL, anyone? And, perhaps in the process, learn how to ask the right questions of the likes of ChatGPT in order to get what I really wanted — not just what amounted to a proof of concept (which to be fair, that which I wanted amounted to a proof of concept, even if it took a while for me to realize it), but an actual, useful, running piece of software?
20260602 update: I made a presentation to my linux group in March, 2026, and the video is finally available on our YouTube channel, as well as on malak.ca. There is a blog post announcement about it here. I presented the over all concepts, using some of the screencaps from this post, and praised those who work with legacy software. ChatGPT was merely an incidental character in my story, along the lines of “I consulted ChatGPT, sometimes relied a bit too much on it but only so much because — I don’t think, anyway — I’m not a complete idiot”. Of course, no coordination was made with anyone showcasing either real-life legacy software maintenance, or ChatGPT.
Since about 2018 or 2019, I have been using the Fedora upgrade tool (here’s a link to my backup) to upgrade my fleet of computers to new versions of Fedora, normally skipping a version at a time, and having settled on odd numbered versions (as a matter of convenience to take advantage of Fedora’s roughly year long life cycle) since about Fedora 15.
In December 2023, I blogged about upgrading my fleet of five computers — all of which I still have and are still running — from Fedora 37 and 38 to Fedora 39. This included two baremetal installs, which proved to be the most difficult. So, despite the title above, I want to underline that the upgrade tool makes upgrading a breeze, even when there are issues, which are usually trivial, and, usually not difficult to resolve … admittedly, if one has a bit of experience! 🙁
As I recall, the upgrade cycle at the end of 2024 from Fedora 39 to Fedora 41 was rather unremarkable. Meaning, I have no recollection of the experience beyond that it happened, especially given the evidence of having just spent the last year using Fedora 41!
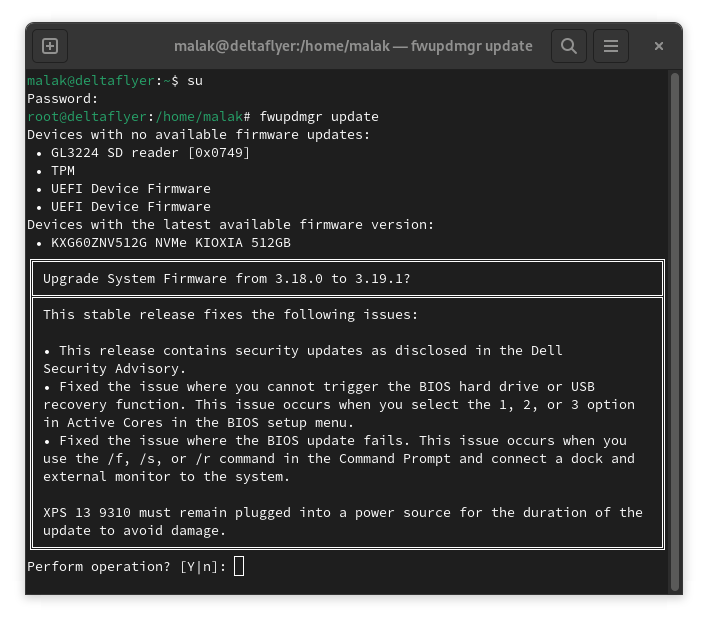
The release of Fedora 43 came around a few weeks ago, and I embarked on the upgrades on a sunday afternoon at the very beginning of November, 2025, and was finished and writing up this blog post by the Tuesday evening a couple of days later.
To begin, I looked up my post from December 2023 as a reference throughout the process, and was constantly referring to the following commands, performed as root:
Despite the experience largely being a breeze and relatively unremarkable, I had three distinct problems of note over three systems on the upgrades.
Problem #1: Download of new version blocked by existing packages
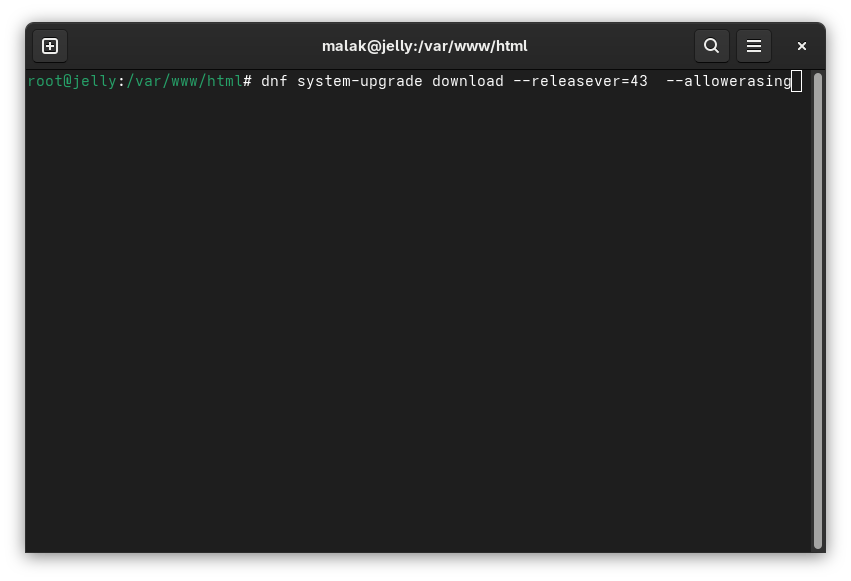
On my desktop and later on one of my laptops, I received what was to me cryptic errors about some packages on my systems, which were listed, which somehow blocked the upgrade. Looking around on the internet but before even finding a solution, I recalled that I could add “—allowerasing” to the end of the
dnf system-upgrade download –releasever=43
command to start downloading the packages; this allowed the system upgrades themselves to proceed “like a breeze”. Well, sort of, but not quite.
And here is a screenshot from my desktop post-upgrade, but before I started dealing with Problem #2:
Desktop on my desktop computer, with new Fedora 43 artwork, and my IP address shaded out
Problem #2: Gnome Extensions causing system to freeze:
According to my recollection, which of course is subjective at this point, one of the points highlighted as a positive in the transition from Gnome 2 to Gnome 3 — in the Fedora world, beginning with Fedora 15 in May, 2011 — was that Gnome 3 was designed to be extensible. (Looking back, this may well have been a concession on the part of the Gnome developers since the code, being open source, naturally lends itself to such, at least in the short term.) This way it allowed both the Gnome developers to present the desktop environment according to their vision, and allow users to modify it to behave as they pleased. From this, for instance, the Cinnamon Desktop, initially really just a heavily extended variant of Gnome 3, was born.
Unfortunately, what has really occurred in my experience — including during this upgrade cycle — is that with just about every upgrade comes breakage of many Gnome 3 extensions; and from this, for instance, the Cinnamon Desktop finally forking itself away from Gnome 3 due to the extensive work they had to do with each release to maintain their extensions and their functionality. As such, I have had many Gnome extensions over the years — which I have gotten directly from extensions.gnome.org to boot! — that have come and gone simply because maintainers could not devote the time to update them for each release. This is doubly frustrating, because:
on the one hand, I would love Gnome to have some kind of pathway such as stable APIs or whatnot that would keep extensions alive instead of having to be (sometimes massively) rewritten with every release of Gnome, and,
on the other hand, you get what you pay for, which in my case, is a wonderful operating system for which I paid nothing more than the internet connection to download it, and if I don’t like what I get, I can always change desktop environments — there are several!
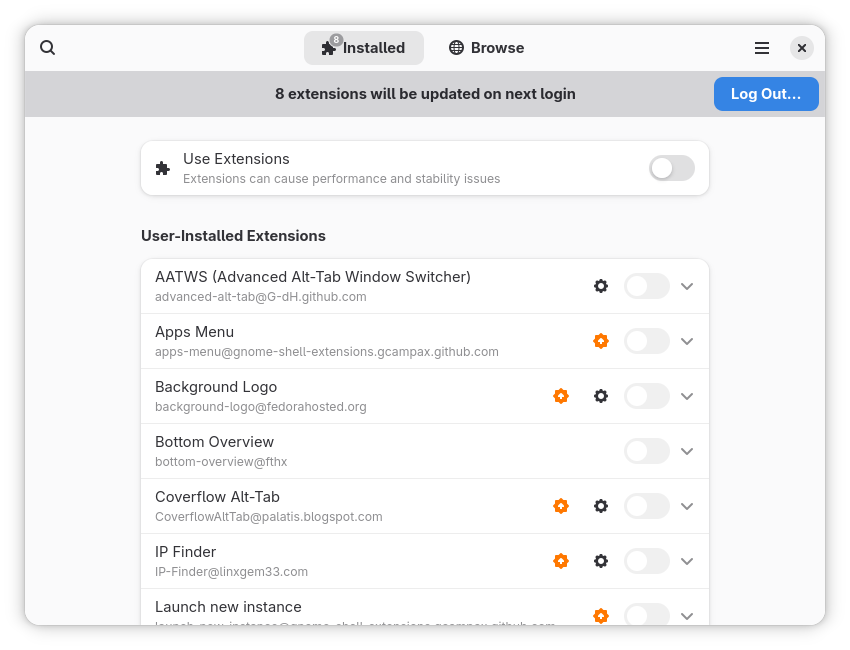
To wit, on my desktop, existing and active extensions made the system freeze, usually within roughly 15 minutes or thereabouts: The mouse would not work, they keyboard would not work, the screen would freeze, the time and date display would freeze, and I could not ssh into the machine from another machine. After the third or fourth hard reboot requiring powering down with the power button and after about a day, I noticed a notification window come up after a reboot, saying that there were extensions that needed to be updated; I proceeded with this, and the problem was solved.
Popup window indicating extensions to be updated (window taken from a laptop system, not my desktop)
The “Log Out” button was pressed, and I logged back in; all seemed to be solved.
Problem #3: Deprecation of X11 would cause systems to not boot into a graphical desktop
On my webserver — the host of this blog! (and which is in my bedroom, not colocated in some datacenter or some virtual machine in a cloud service — I use Fedora Workstation (graphical) instead of the server edition. This is simply because at its core, both editions are essentially the same operating system, and at the time that I installed the current instance, I hadn’t ever used the server edition. Of course, each has different subsets of packages and different settings in their default installations, but at their core, they are the same OS, a few “dnf install” commands and settings away from each other. And, while I indeed normally treat it and administer it as a headless server, there have been a small handful of occasions over the years during which my significantly-less-than-expert abilities have allowed me to do things with it using the graphical desktop that I would have had more difficulty doing on the command line.
At this point I should say that usually, one should do backups before proceeding with the upgrades, a practice that with one exception I don’t normally do.
However, I did do so with my webserver, which is also a passive backup for my data from my other computers … which is a bit out of date, although I expect / hope not substantially.
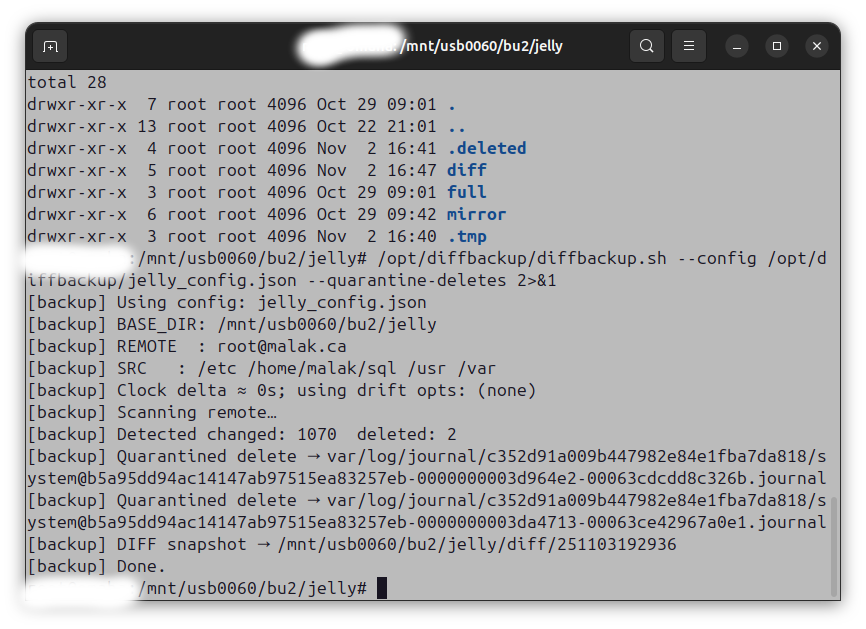
So I asked my brother to do a backup to his network, which just required a manual differential update, since we had already set up cron jobs to do so:
Backing up my server data
Backing up my server data
Backing up my server data
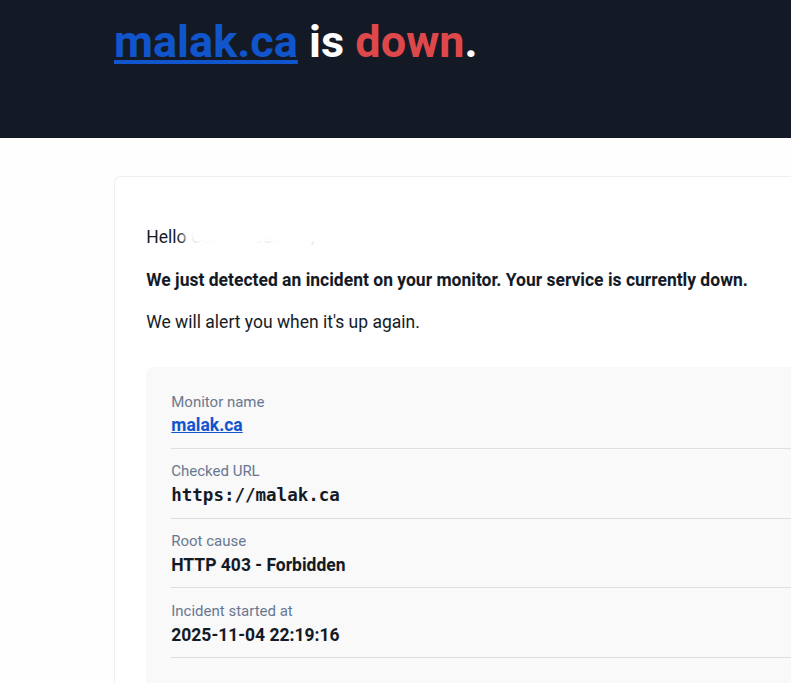
The next day, I started doing things like dnf updates and then the upgrade. Whaddya know, I got a couple of messages from my brother while I was upgrading. He sent me some screenshots:
Warning from my brother that my website was down
My brother has an alert on my website to detect downtime. I told him that I was aware, because I had manually disconnected the external hard drive with the static parts of my website.
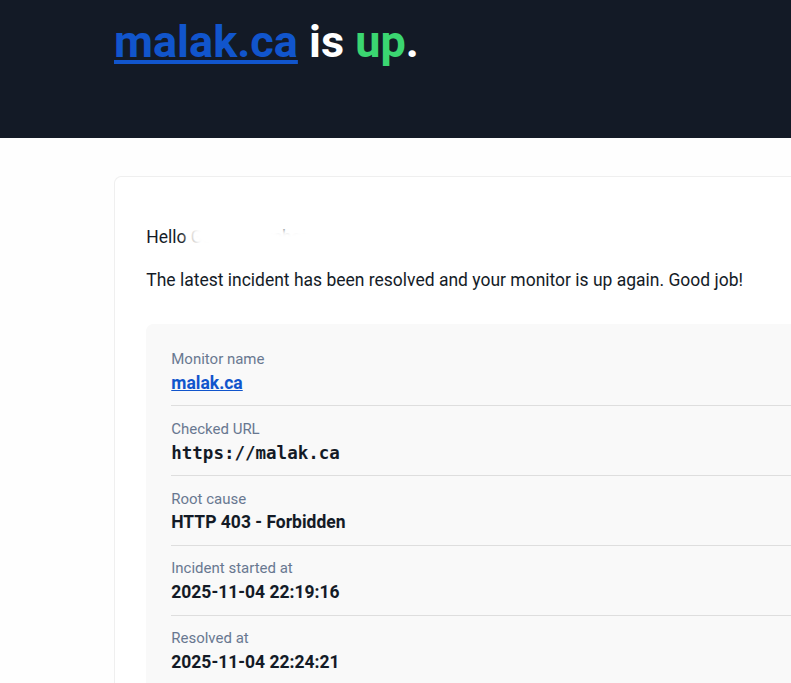
Then a few minutes later, I got another message from him:
Warning from my brother that the site was back up
I responded to him again saying well of course, but I’m still in the process of doing the upgrades!
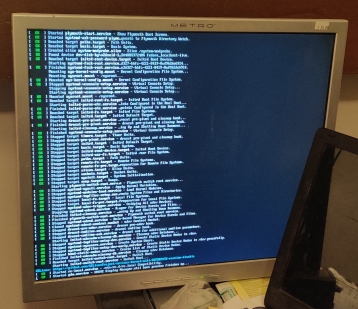
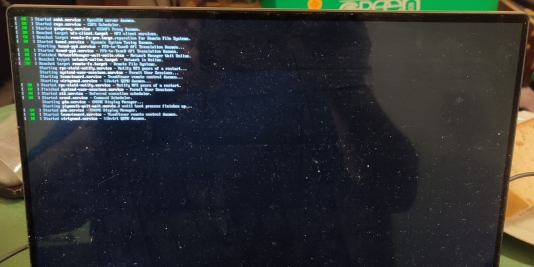
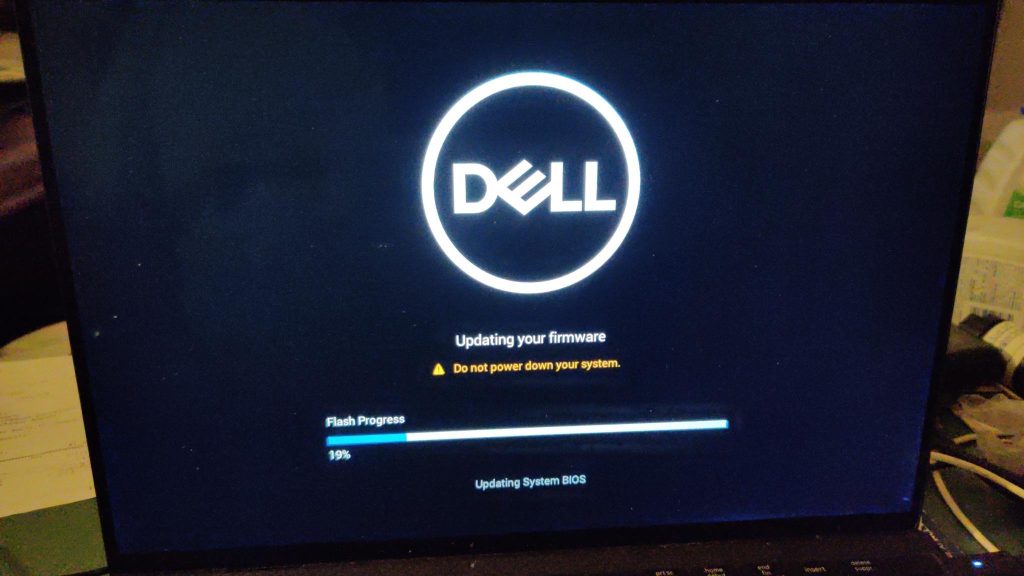
I went through the upgrade, which seemed to work. Yet, upon the reboot after the upgrade, I got the following screen:
Server bootup stalled
Oddly, it stopped during the reboot. However, I managed to ssh into the machine, as well as check to see if it was able to serve web pages. Both worked.
In the meantime, I also got ambitious and started upgrading one of my laptops. Again, once I’d done the “–allowerasing” addition to the download command (above), and the system went through with the upgrade, I got the following screen:
Laptop bootup stalled
Fortunately, I was able to ssh into the laptop.
But I was wondering what was going on, especially since both machines appeared to stop at different times — although, I suppose, the webserver had a few other services to start, but that’s beyond what I actually checked.
So I tried to ask on the internet, and the first suggestion I found was on the Fedora discussion boards (somehow I can’t seem to create a proper PDF of it …) suggesting that I modify a shadow file:
This did not work for me.
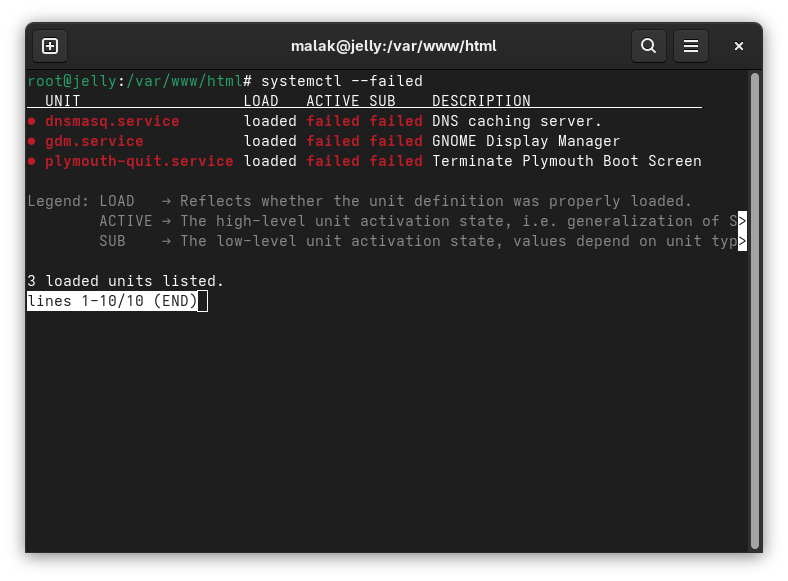
Another suggestion I found elsewhere was to check what failed, so as root on my server I entered:
systemctl –failed (that’s two dashes, wordpress decided to combine them!)
and I got the following information:
systemctl –failed results
This seemed to tell me that there were issues with starting up the graphical display. I suspected that this could be the same problem I was having on my laptop.
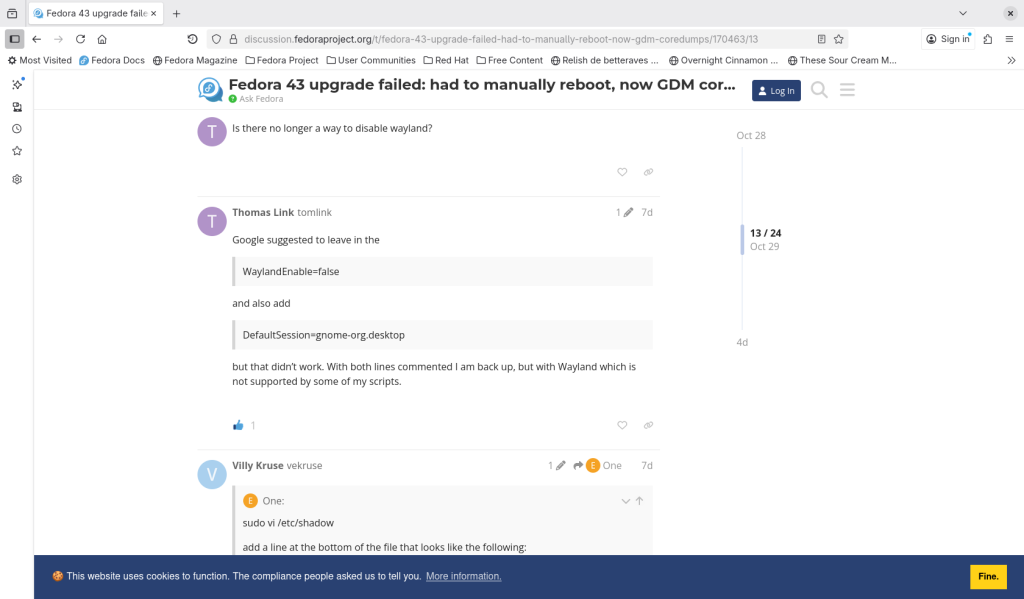
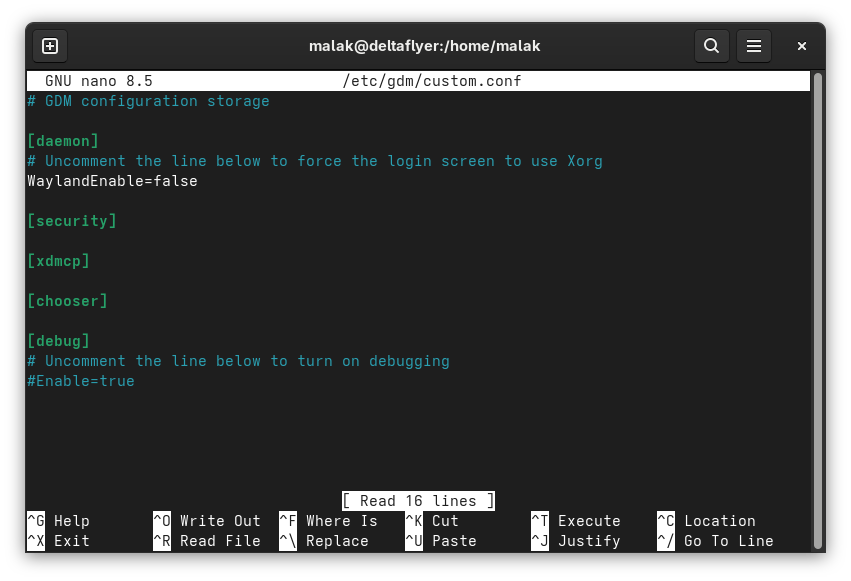
The advice was to edit the /etc/gdm/custom.conf file by commenting the line “WaylandEnable=false”
With this I remembered that on my webserver and one of my laptops, the windowing system was X.org for historical reasons related to my brother helping me a lot with these systems, and, until recently, X.org was easier for him to remotely help administer those systems if he needed to use the desktop. Alas, X.org has been deprecated in Fedora Workstation Edition using Gnome (here’s my archive), although one can still use it elsewhere in other editions and spins.
WaylandEnable=false uncommented, telling my system to not use Wayland, therefore making my system hang
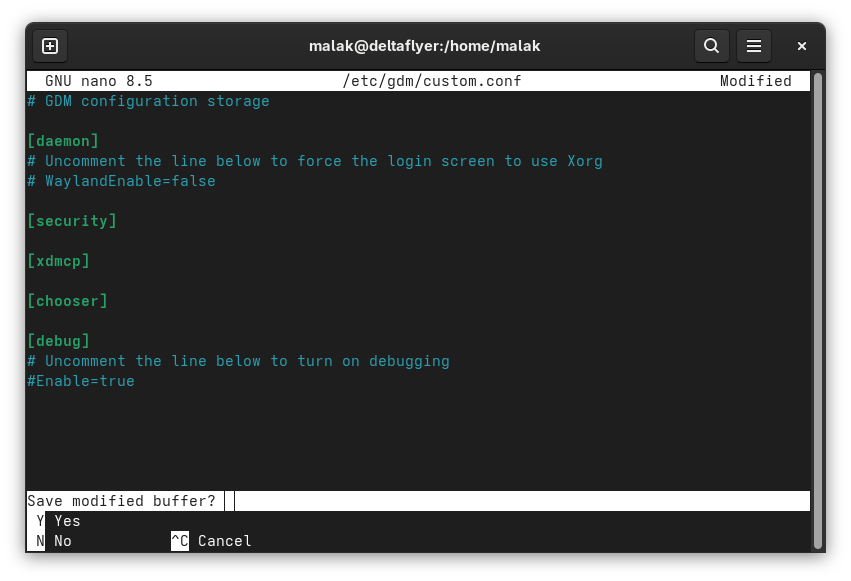
WaylandEnable=false commented out, allowing my computer to reboot properly and get to a GUI
Well once the WaylandEnable=false line was commented out, that solved my problem easily on both my webserver, and on the laptop that was affected.
Note about desktop on abovementioned laptop:
Curiously, the laptop’s wallpaper wasn’t changed. In fact, it still has the wallpaper from its original install of Fedora 36 when it was new!
Wallpaper on one of my laptops, from Fedora 36, its original image when new
(Maybe I should check the settings to see if something was set to permanent on the wallpapers when it was initially formatted when purchased new. Maybe.)
And yes, on my desktop, my other laptop, and my webserver, which all have the Workstation Edition, the wallpapers upgraded to the Space Shuttle design for Fedora 43. Only the VPN server, which is the Server Edition, doesn’t have any wallpaper at all.
The “Breezy” systems:
And the other two systems I have? Upgrading them was a breeze — an old PIII 3.4 something or other I found in a building slated to be demolished in 2016, now running Fedora Server edition, and currently used as a VPN gate and soon as a backup server, and a 2015 laptop that I still use regularly, including for teleconferencing and videos. Both upgraded like a breeze and without saying boo.
Using your computer of course requires some software beyond the base operating system; fortunately, most desktop linux distributions not only have repositories of freely installable software, often more common software as decided by the distro’s maintainers are pre-installed on the system at the same time as system installation.
This post is concentrating on the popular office suite LibreOffice which includes a drawing program, a word processor, a spreadsheet application, and a database application. While this post will show a few functions of each part, it is in no way intended to be a tutorial, but rather a cursory demonstration of each, leaving the exploration of each to you, the reader.
In this post I occasionally refer to operating systems beyond Linux. Also, contrary to my usual habit of not editorializing in this series, I offer the following: Many Linux software suites are largely, although importantly, not completely compatible with other known equivalents on other systems. They will often be able to open and edit files created by them; however, the compatibility and drop-in replacement value of each piece of software for the other (regardless of in which order) is often variable, sometimes quite substantially.
Note that occasionally, some screenshots were taken at different times for the sake of completeness, but presented in the order seen here, for the sake of the narrative.
Pinning Apps to the Dock:
Start from the Activities (hot corner in the upper left hand corner (the horizontal bar; either just quickly move the mouse there, or if necessary, click on the the horizontal bar):
Activites screen
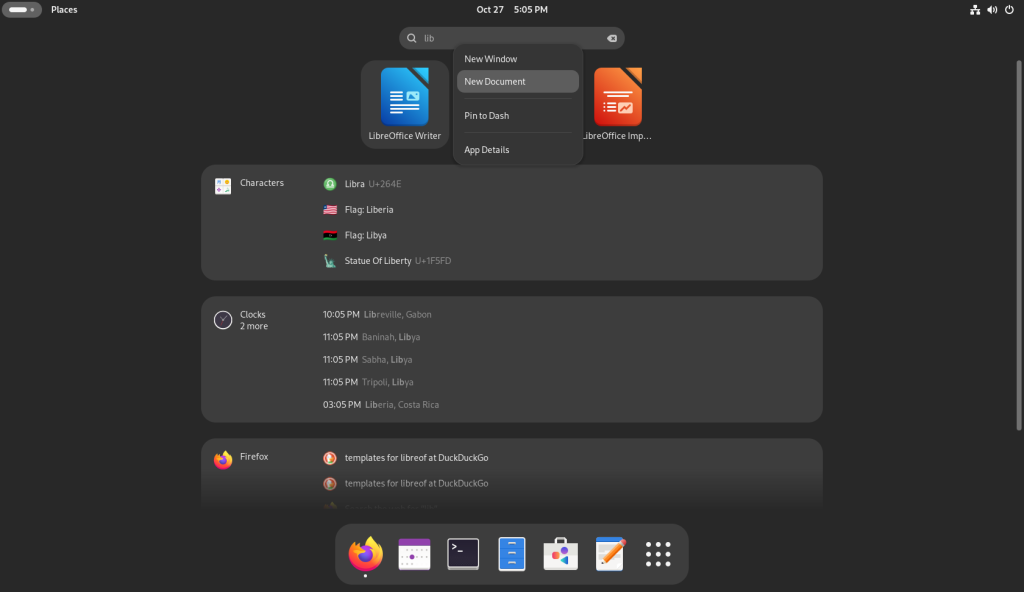
I searched for “Lib” which brought up three of LibreOffice’s apps: Writer, Calc, and Impress, and I right clicked each one …
Searching for installed LibreOffice components
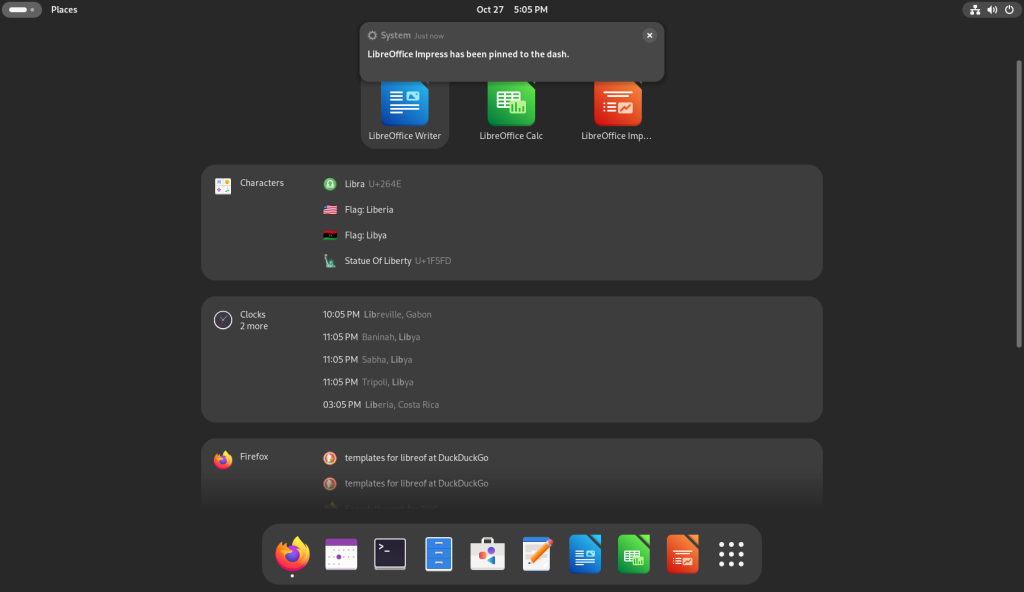
… each of which I pinned to the dock at the bottom, one at a time:
Pinning icons to the dock
Templates:
Note: In this post, the use of existing document templates found on the internet will be generously relied upon in order to demonstrate in a cursory fashion some of the resources available to desktop users — both of free software packages and other systems as well — as well as to simplify the mounting and development of the narrative using said existing documents. The site www.freedesktop.org, by happenstance, is frequently used, as is the templates section of www.libreoffice.org. Of note, especially on the former site, there are a number of templates which are in languages other than English, and some which have been on the site for several years, using older formats. Hopefully, the language barriers as the cases may be will not be too difficult to surmount given online translation services, while the older file formats are normally seamlessly supported by current software suites, with the ability to save in modern formats.
Users are of course free to create documents from scratch as they would on any system.
Going back to the activities screen, choose the Firefox icon (orange and blue, on the left at the bottom):
Firefox launched
In the address bar, enter the address of a search engine, such as www.duckduckgo.com:
Navigating to a search engine
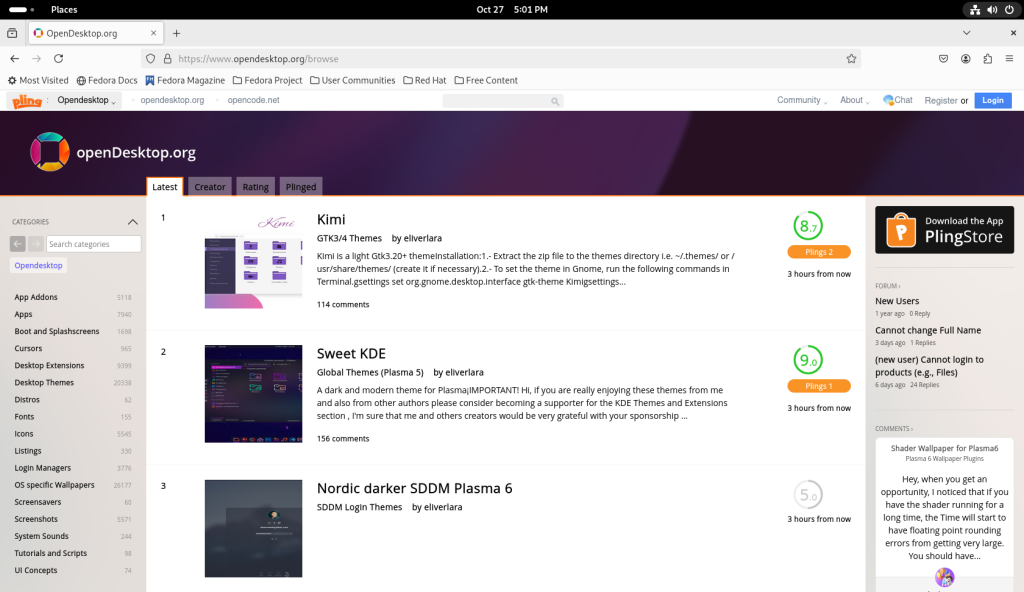
Search for templates. In this case, I specifically asked for templates appropriate for LibreOffice, which brought me to www.opendesktop.org:
Navigating to opendesktop.com
In the search bar, I searched for LibreOffice, which gave me the following options:
Searching for LibreOffice templates
… and chose for ODF Text Templates (for word processessing):
Sorting for odf files
Sorting for odf files
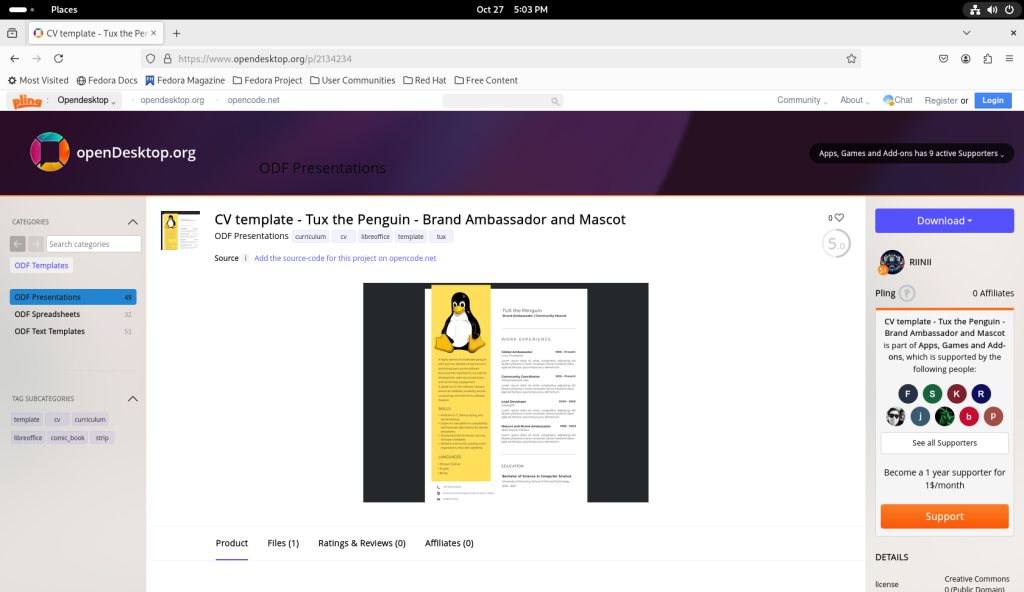
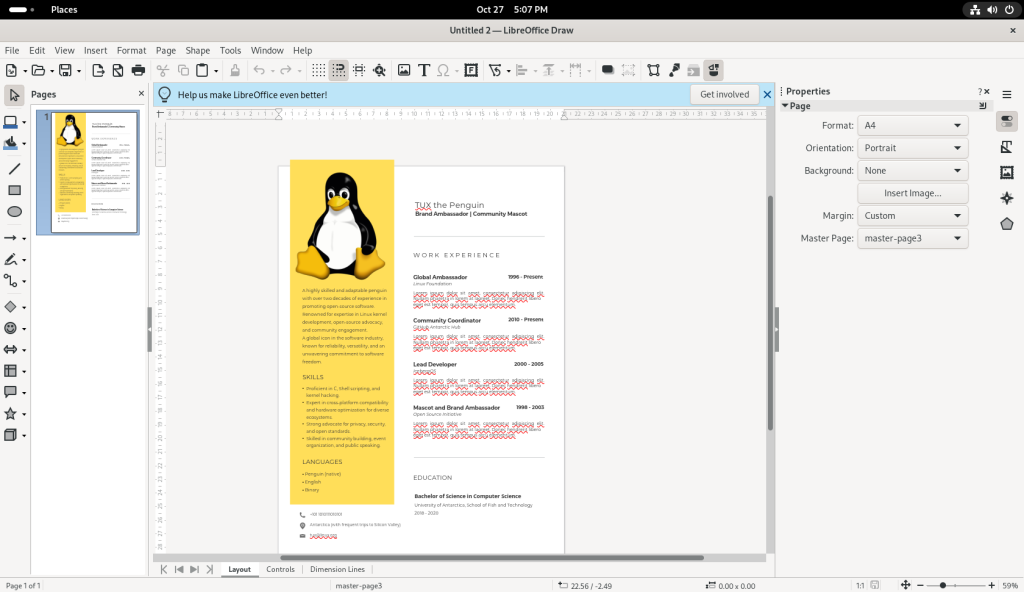
Browsing through the templates, I chose a CV template, for “Tux the Penguin — Brand Ambassador and Mascot”:
CV template chosen
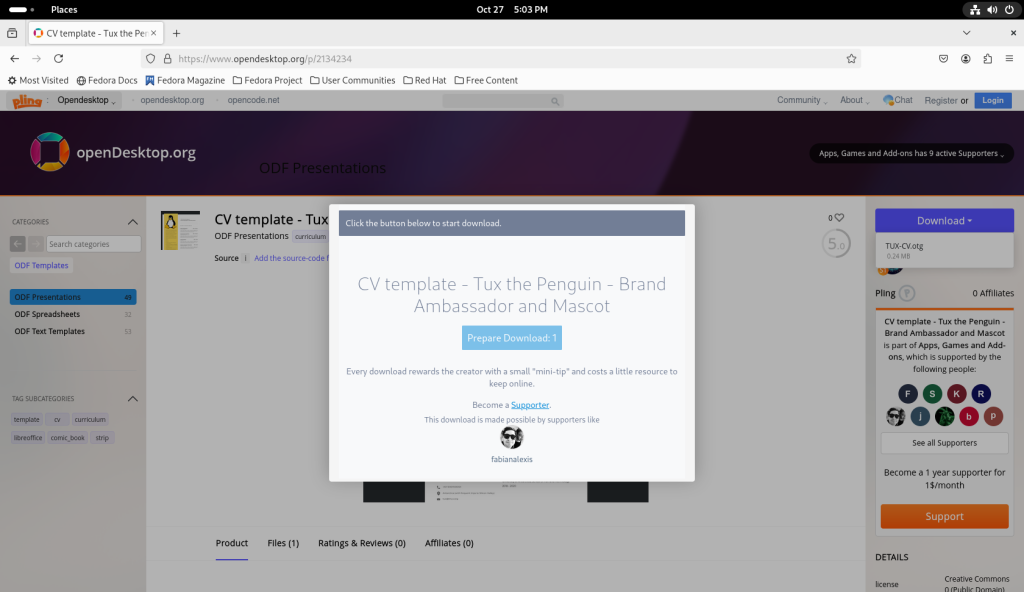
… which I downloaded:
Downloading the CV template
On the activities screen, I opened up the Files application:
Files program launched
Drawing:
… and this is where I learned that the downloaded CV template was not what it seemed. 🙂
Much like other popular desktops, Fedora Linux has several fully functional and fully featured drawing software. One such piece is LibreOffice Draw, which functions similarly to Microsoft Visio, allowing for some basic-to-not-so basic graphical manipulations, editing, basic draughting, and inserting texts.
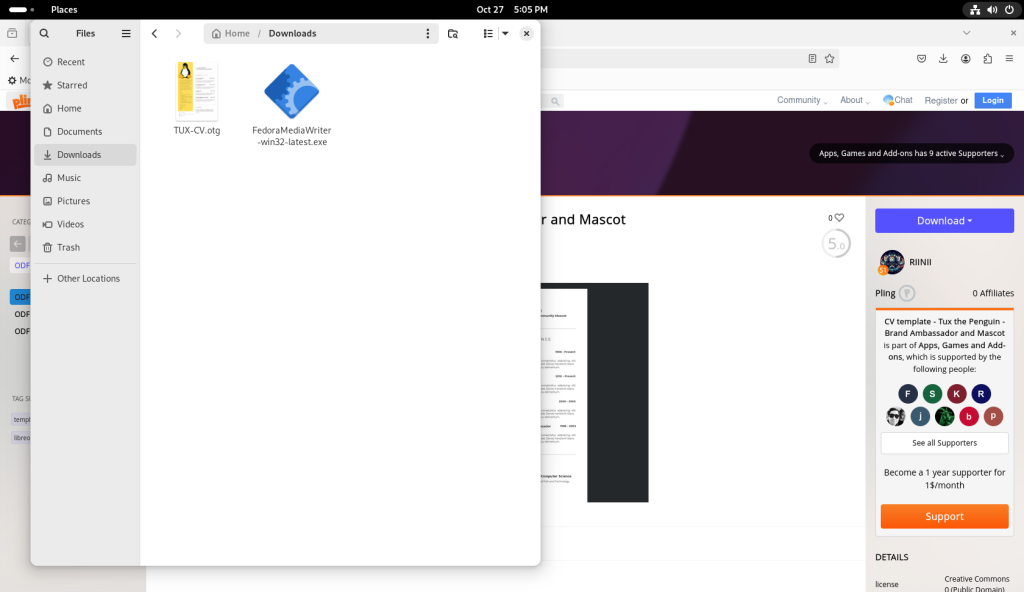
From the Files program just opened, I navigated to the Downloads directory, where the CV was located after downloading, and despite having believed that the CV I had downloaded was a text document, the file format in fact proved to be a drawing format:
Downloads directory inspected
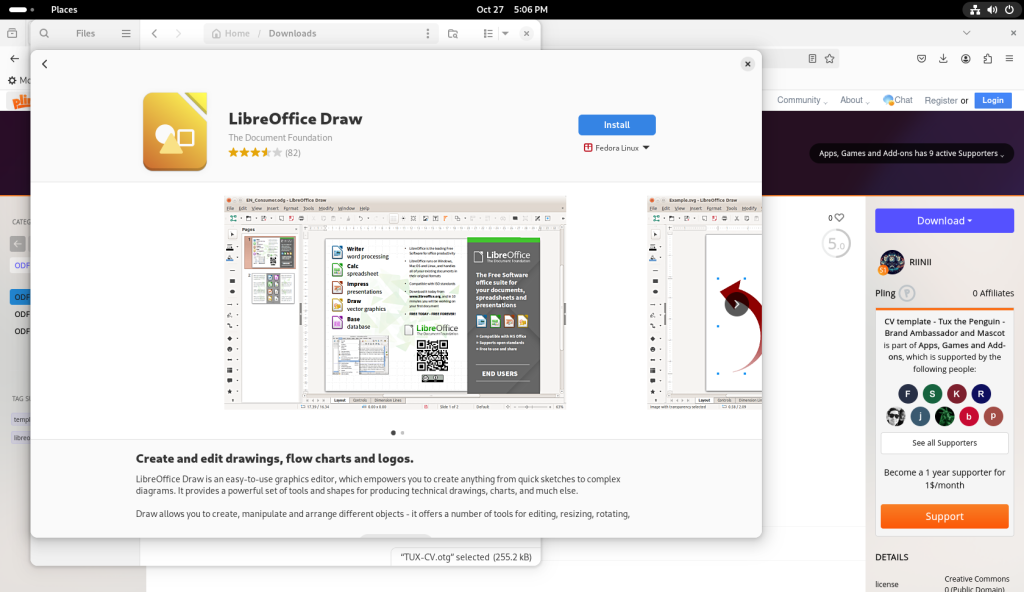
I double-clicked on the CV file, which, since LibreOffice Draw isn’t always a part of a Fedora base installation, launched the software store, and having found LibreOffice Draw in the Fedora repositories, offered to install it, which I accepted:
CV file double-clicked, launching the software store in order to install required software
Once LibreOffice Draw had been installed, I asked that it be launched:
LibreOffice Draw installed
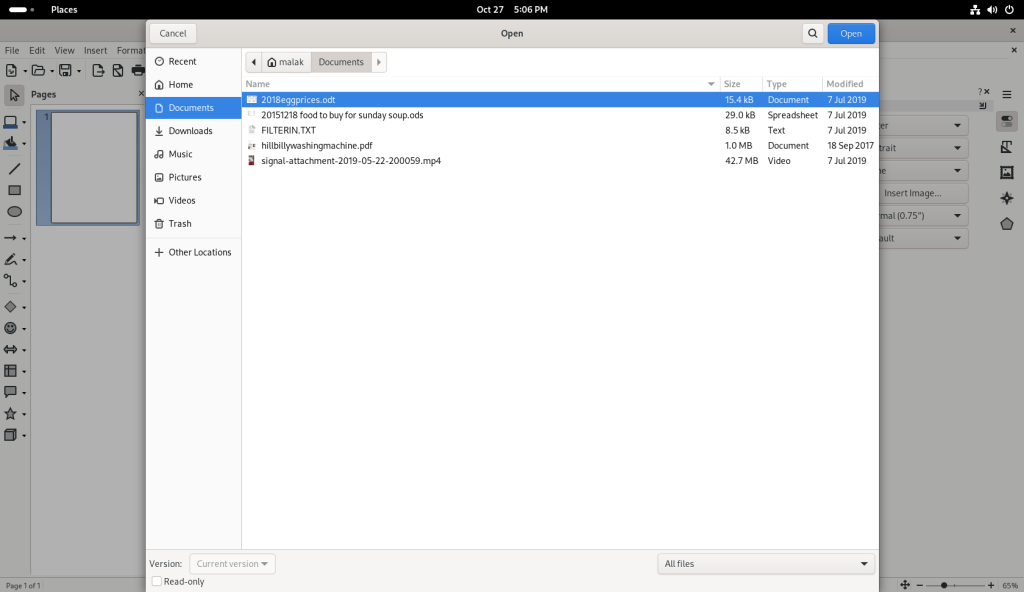
After closing the offer to see the “What’s New” notes, I went to the File dropdown menu to open the file:
Opening the CV template
… and navigated over to the Downloads directory, where the CV was located.
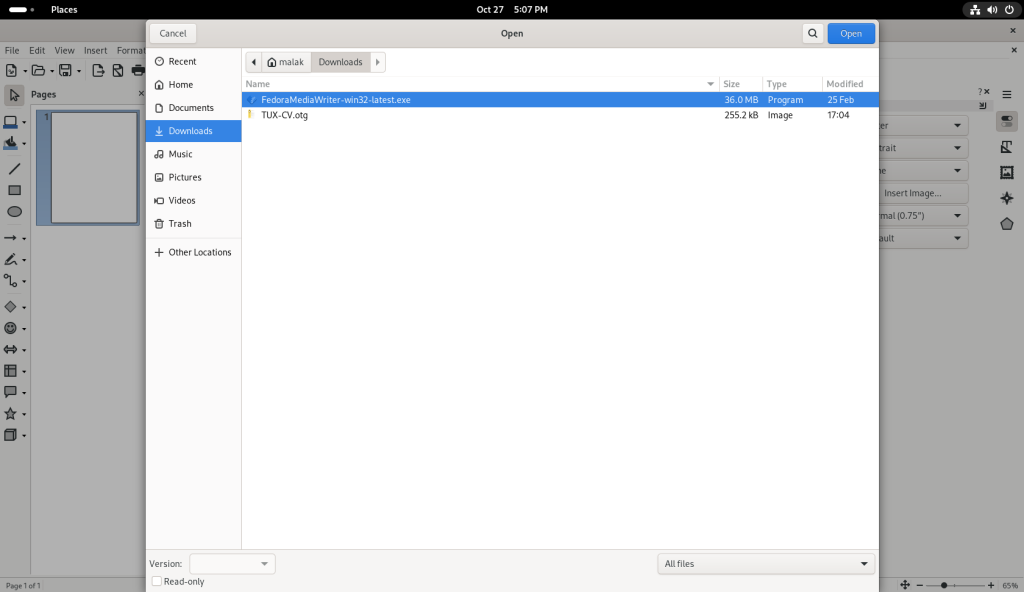
Navigating to the downloads directory
I clicked on the CV file to open it:
CV file opened
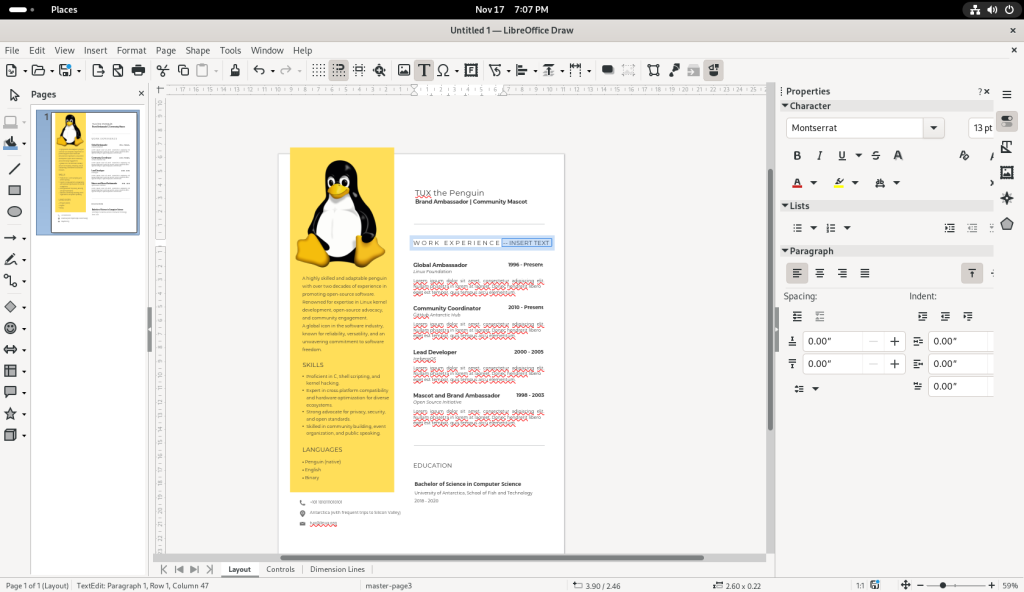
In Draw — depending on the nature of the input file — various existing texts can be modified, as well as many basic-to-not-so-basic graphical manipulations. In the case of this file, the file was designed such that the text could be modified:
Editing the text of the CV
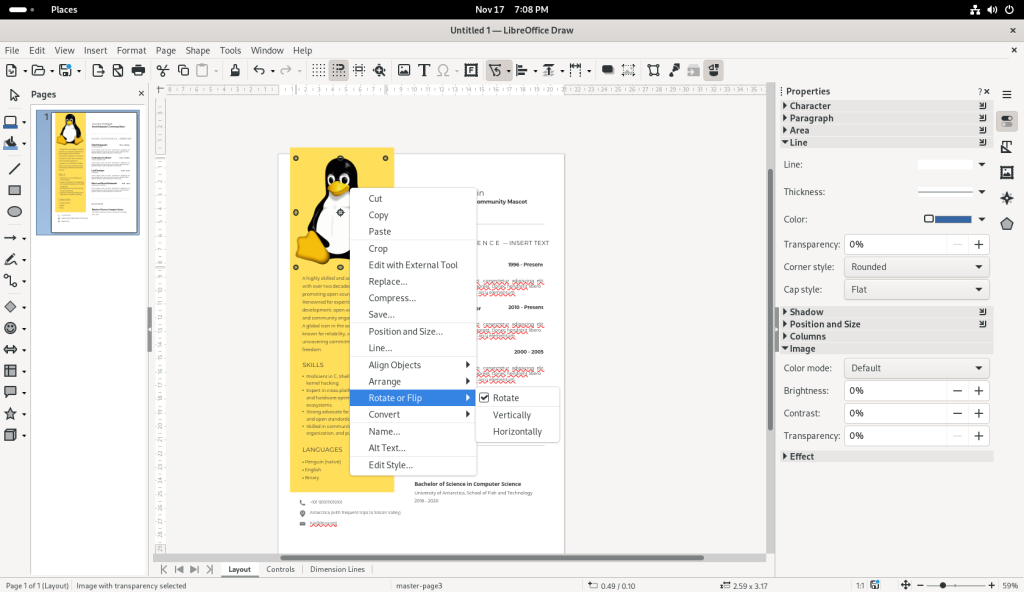
To manipulate images, the picture of Tux (the penguin) was double-clicked to select it, the right mouse button was clicked, and the “Rotate or Flip” option was selected:
Manipulating the penguin image
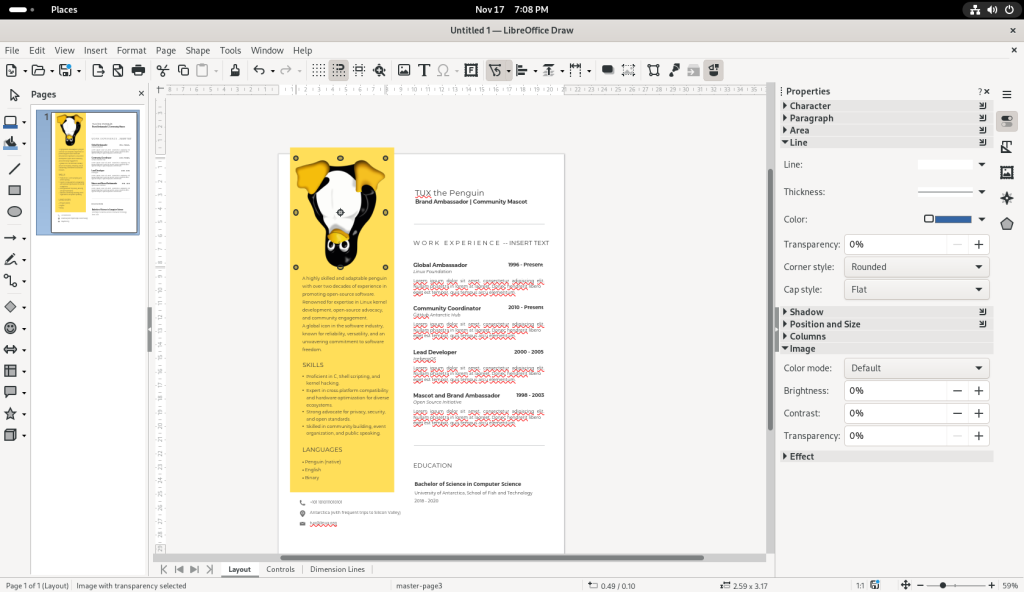
… and I chose to flip the picture of Tux upside-down:
Penguin image flipped upside down
Some modestly — or more complex — drawings, including multimedia documents such as the CV shown above, can be created and / or modified, which I leave to the reader to explore.
Word Processor:
Much like other popular desktops, Fedora Linux has several fully functional and fully featured word processing software suites. One of the more popular such pieces is LibreOffice Writer.
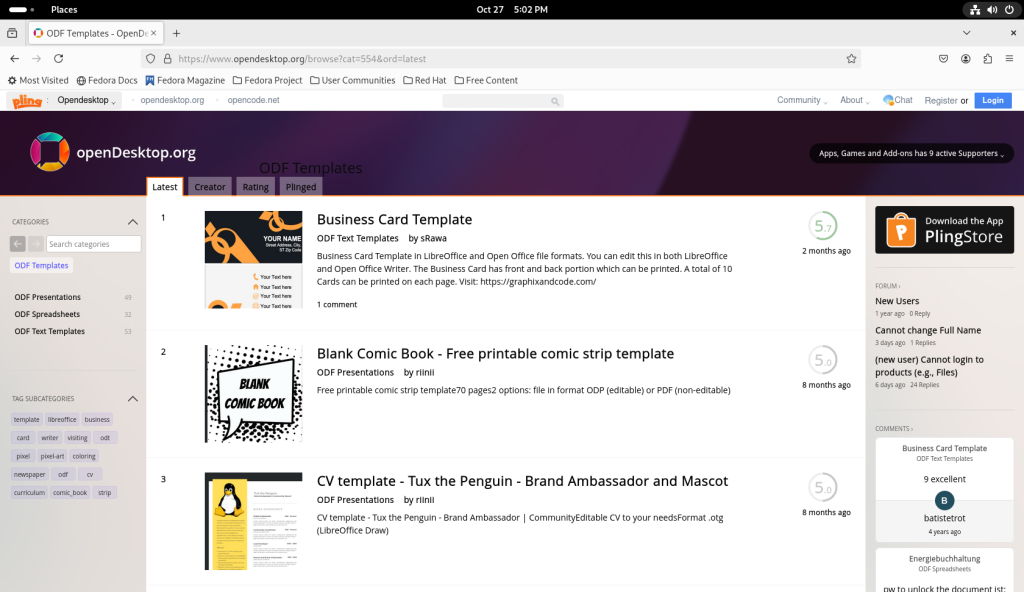
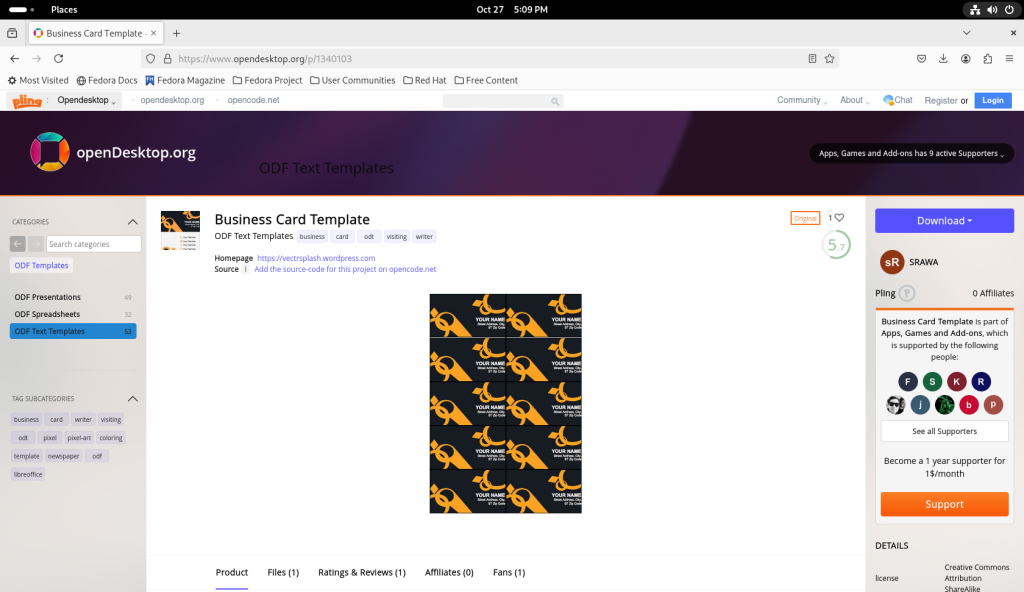
I returned to the opendesktop.org website, and chose a business card template to open in a word processor — LibreOffice Writer.
I navigated to find a business card template:
opendesktop.org template for business cards
… and downloaded the file:
Business card template downloaded
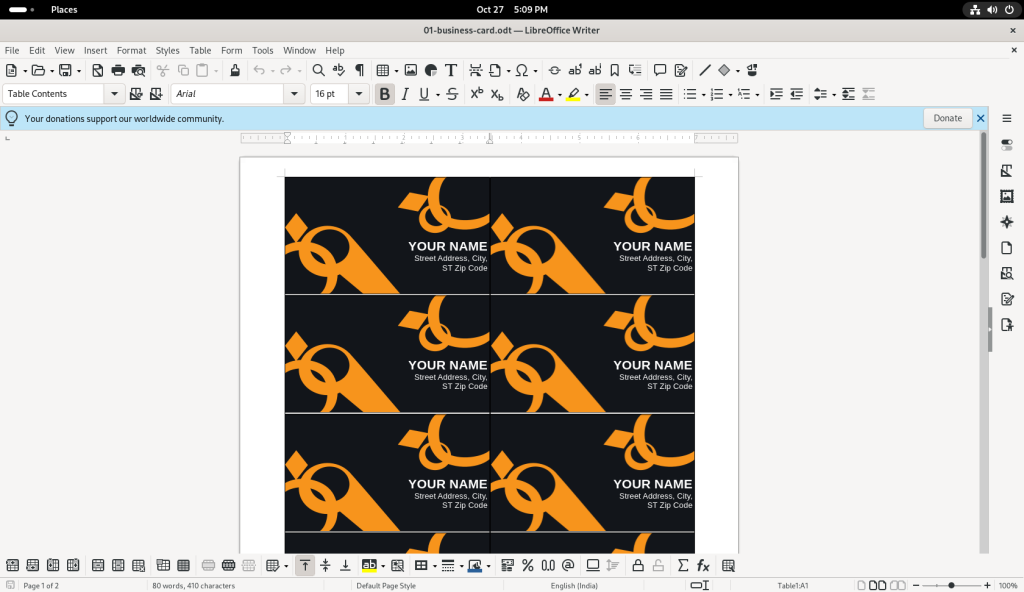
Similar to how the CV above was opened, the business card template was opened, without having to go through the installation of LibreOffice Writer:
Business card template opened in LibreOffice Writer
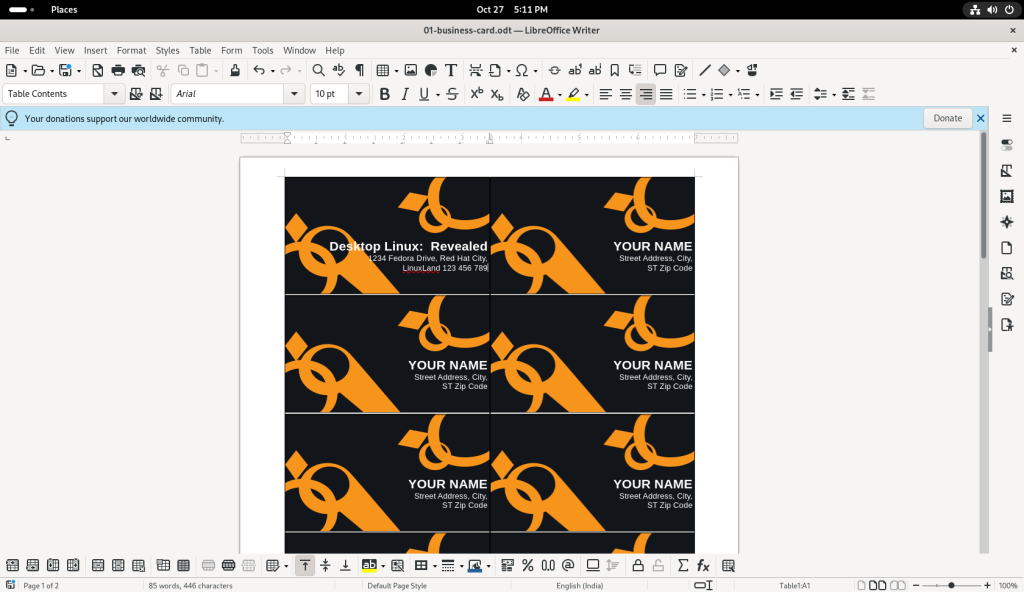
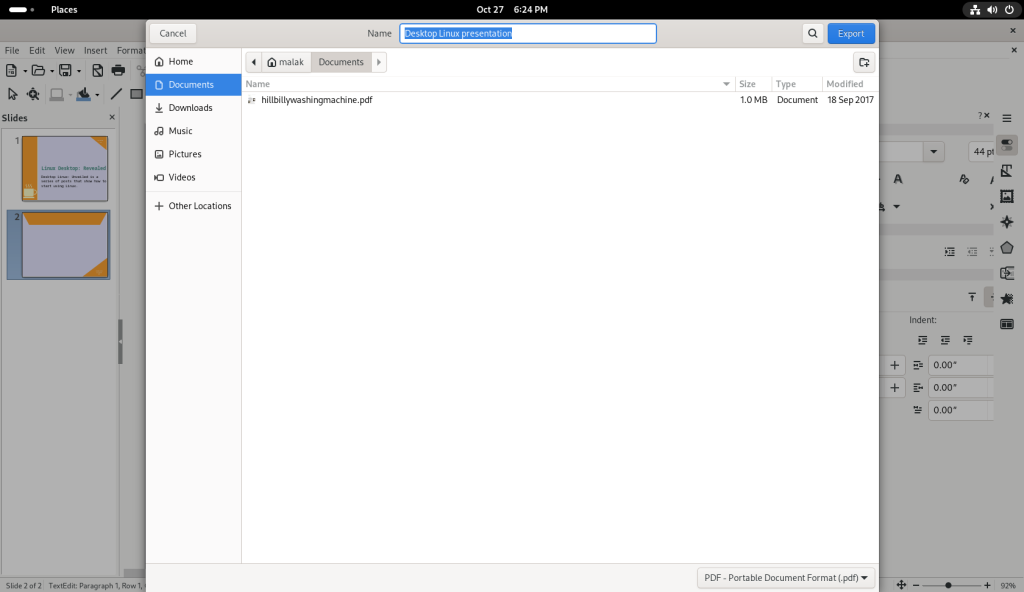
The text of the first card was changed to a “Desktop Linux: Revealed” theme:
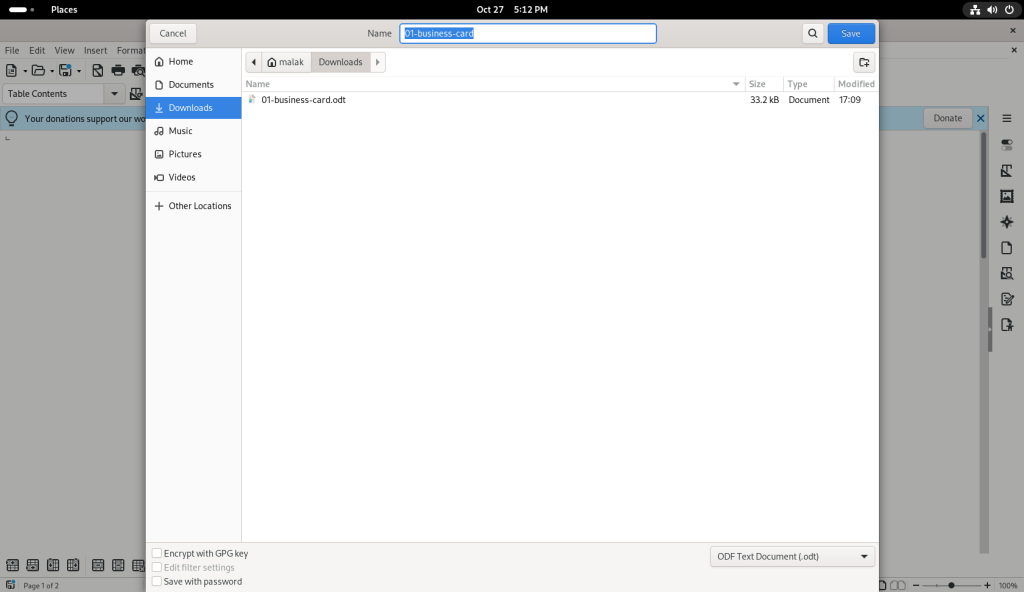
Name and contact details on first card changed
The modifications were also saved:
Saving modified business card file
Saving modified business card file
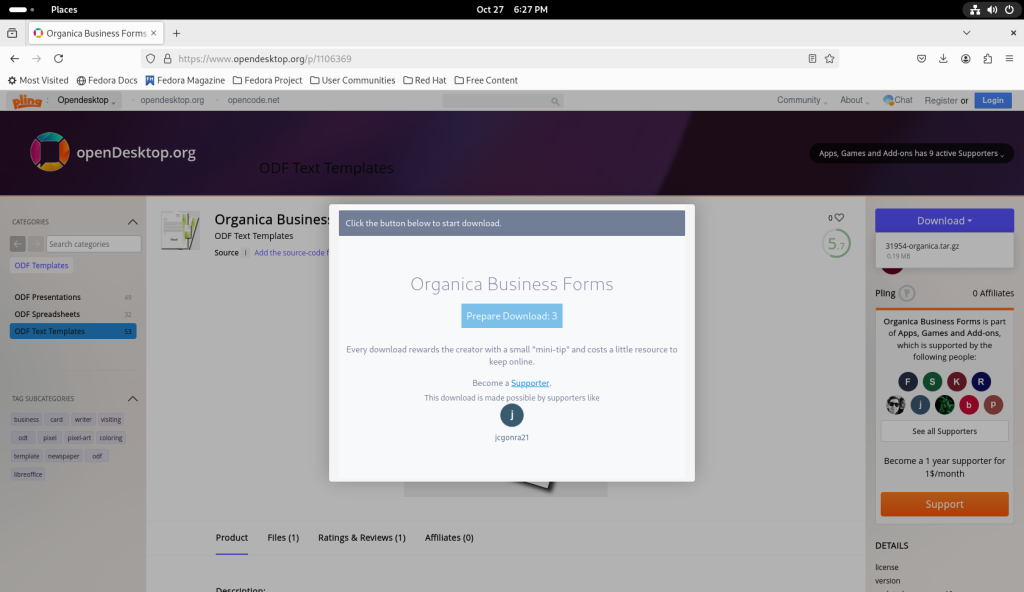
Returning to the opendesktop.org templates, I chose the “Organica Business Forms” to download:
More Writer templates viewed
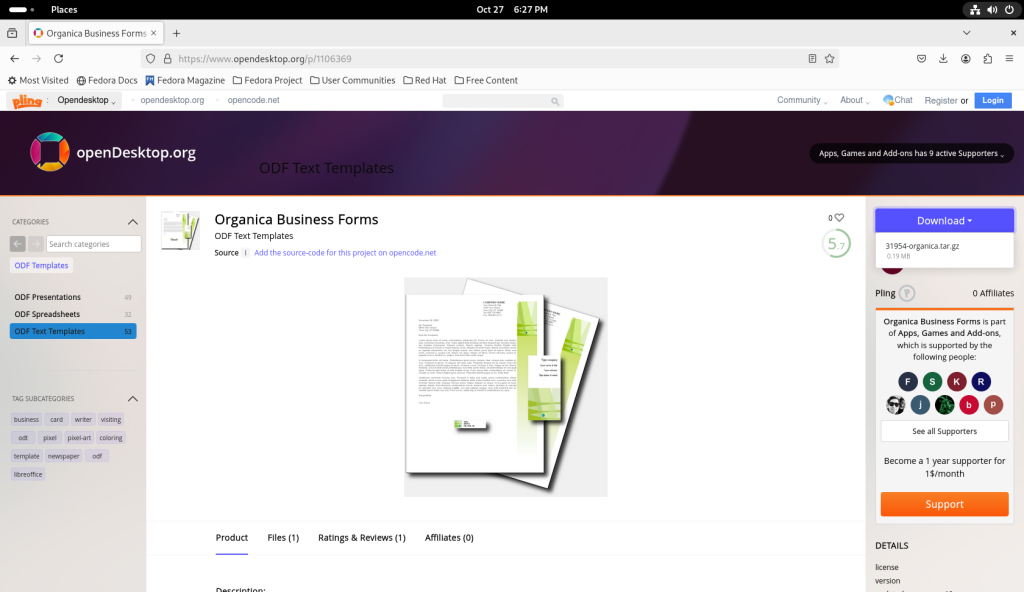
The page for the Organica Business Forms was opened:
Business Forms template page
… and the file downloaded:
Downloading template
Template downloaded and directory opened
The business forms were compressed in the .tar format, analogous to .zip files:
Directory with downloaded file, which was double clicked
The archive was double-clicked, revealing a directory contained within:
.tar file double clicked, opening up the archive
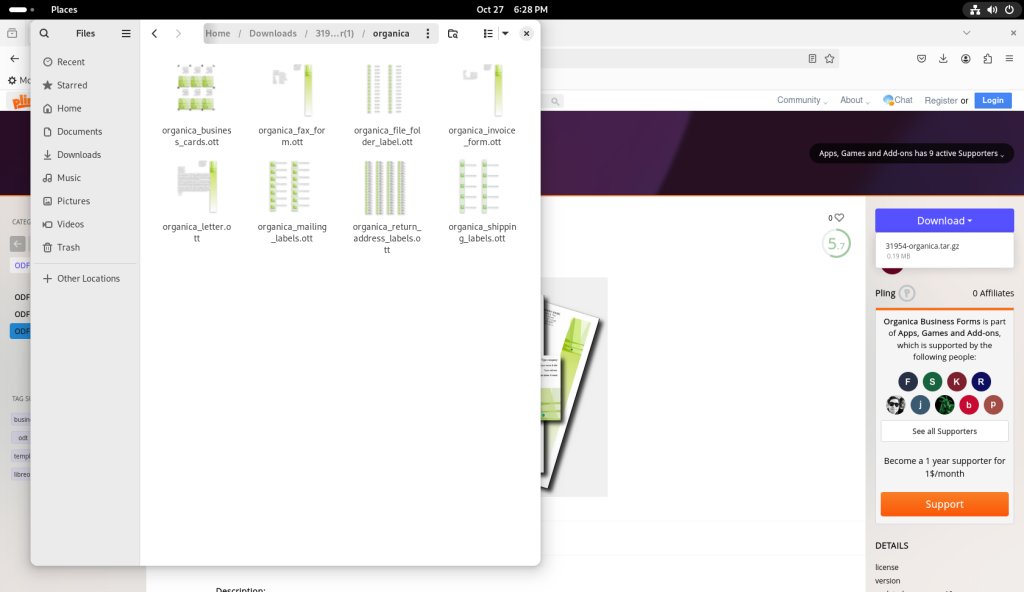
The directory was double-clicked, revealing several templates: Business cards (different from above), a fax cover sheet, four different kinds and sizes of labels, an invoice, and a letter:
Various files in archive revealed
Going back to Writer, the letter file was double-clicked, which again opened the file in LibreOffice Writer:
Letter file opened
A space was added between two paragraphs:
Spaced added between paragraphs
The “Table” drop down menu was opened:
Table drop-down menu opened
… and the “Insert Table” option was chosen:
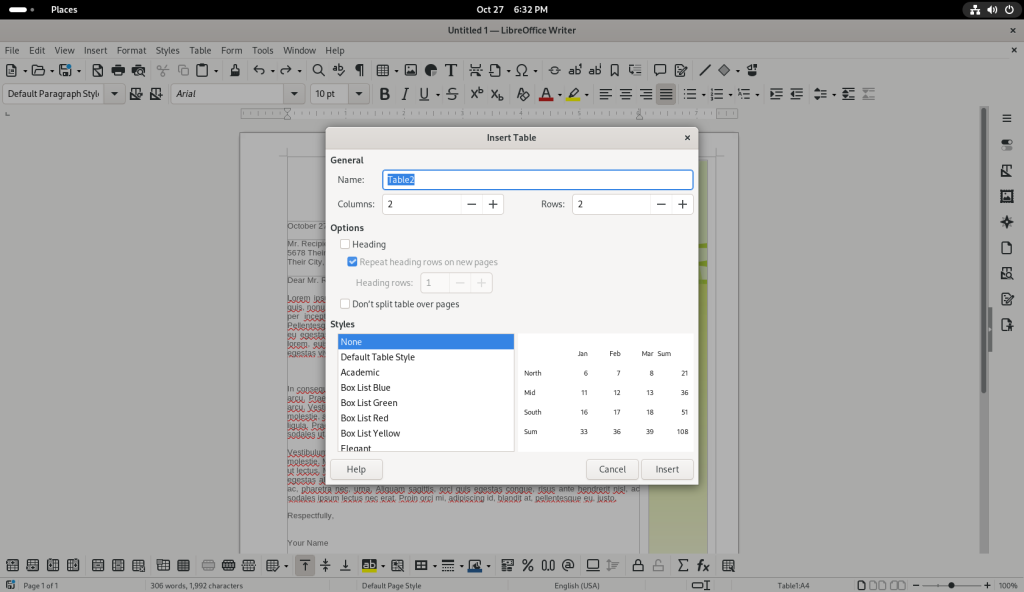
Insert Table option chosen
… which opened up a window to determine some settings for the table to be inserted:
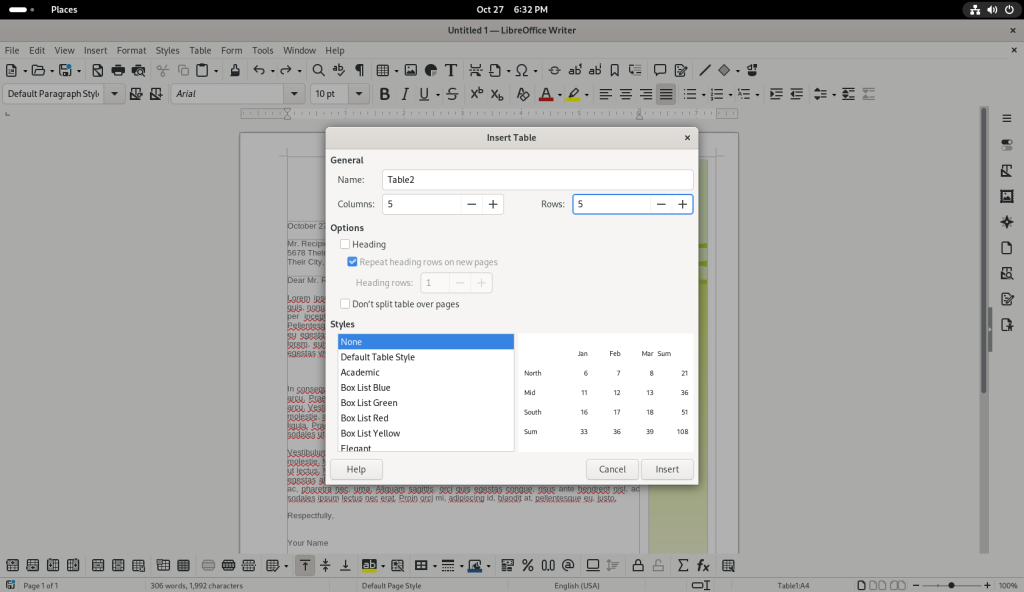
Window opened to set table characteristics
A table with five columns and five rows was selected:
Table settings changed
The table was selected, and the right mouse button was clicked, revealing a contextual menu:
Contextual menu opened
The option “Table Properties” was selected, bringing up a window:
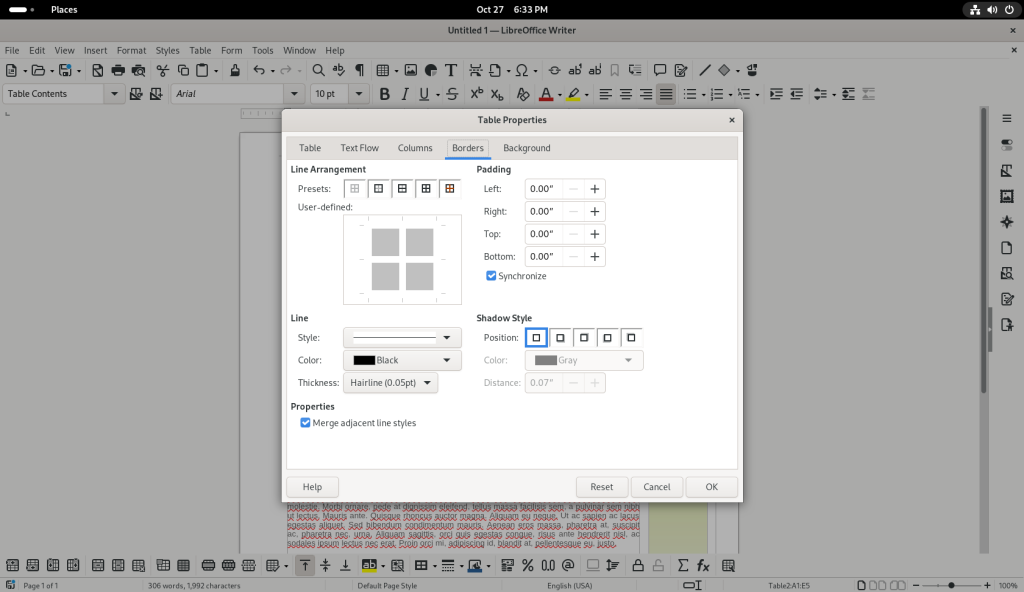
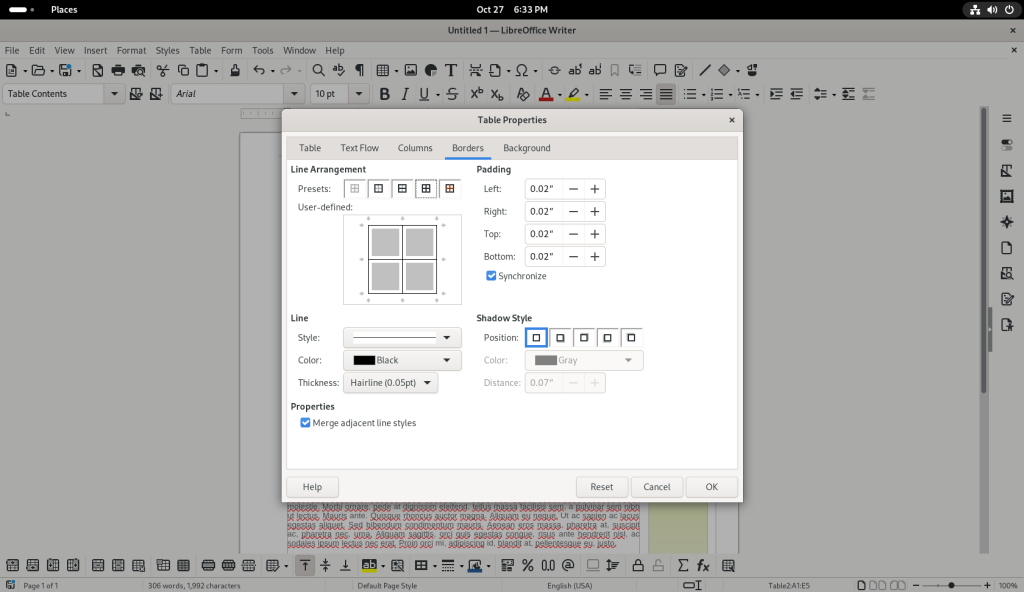
Table properties window opened
The button for all lines under “Line Arrangement” was chosen in the Borders tab, in order to insert borders around all the cells of the table:
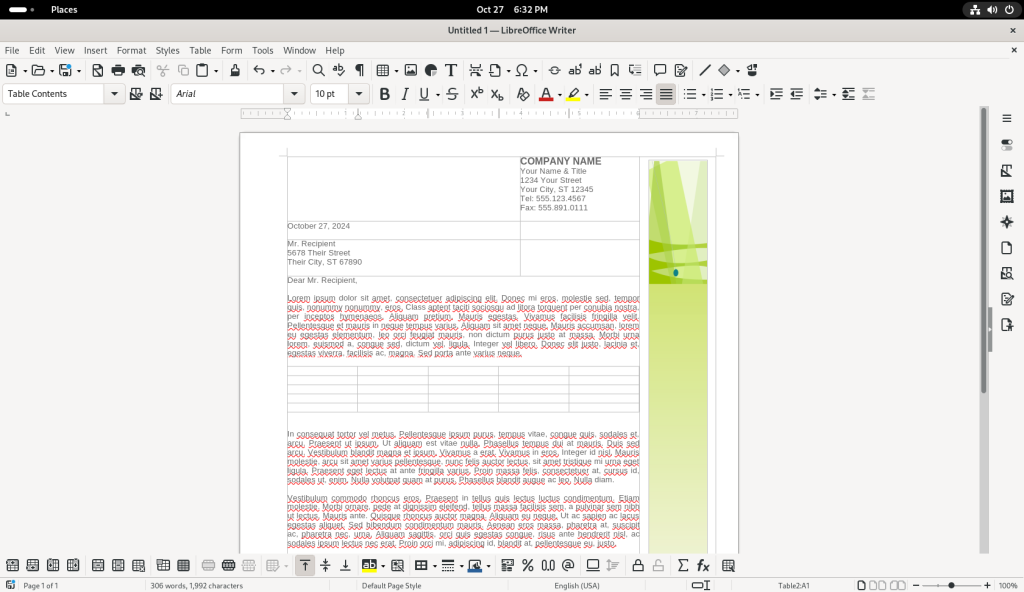
Table borders changed
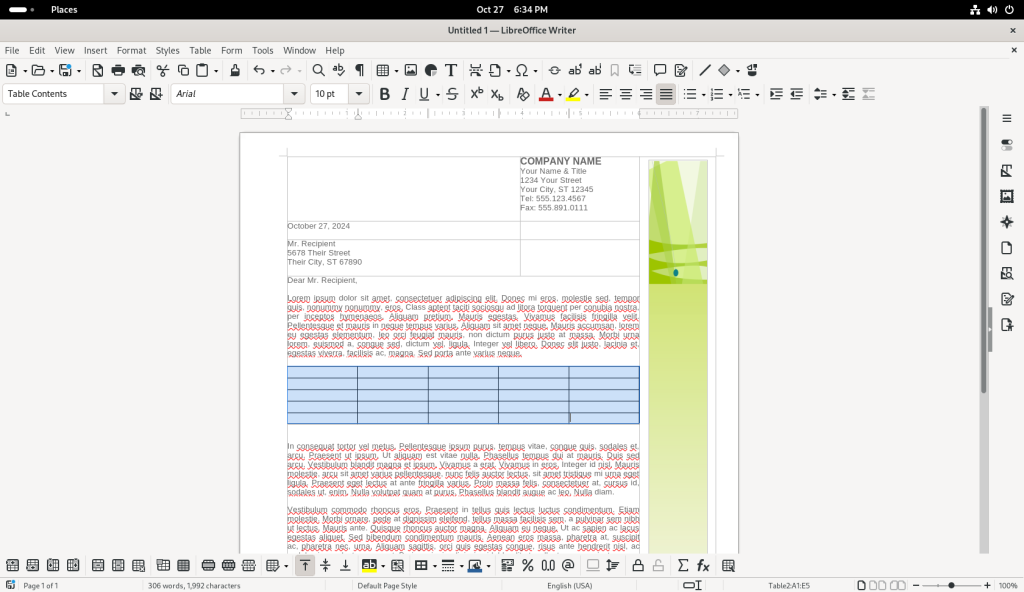
The “Ok” button was pressed, returning me to the document, showing now all the cells of the table with borders:
Table added to letter
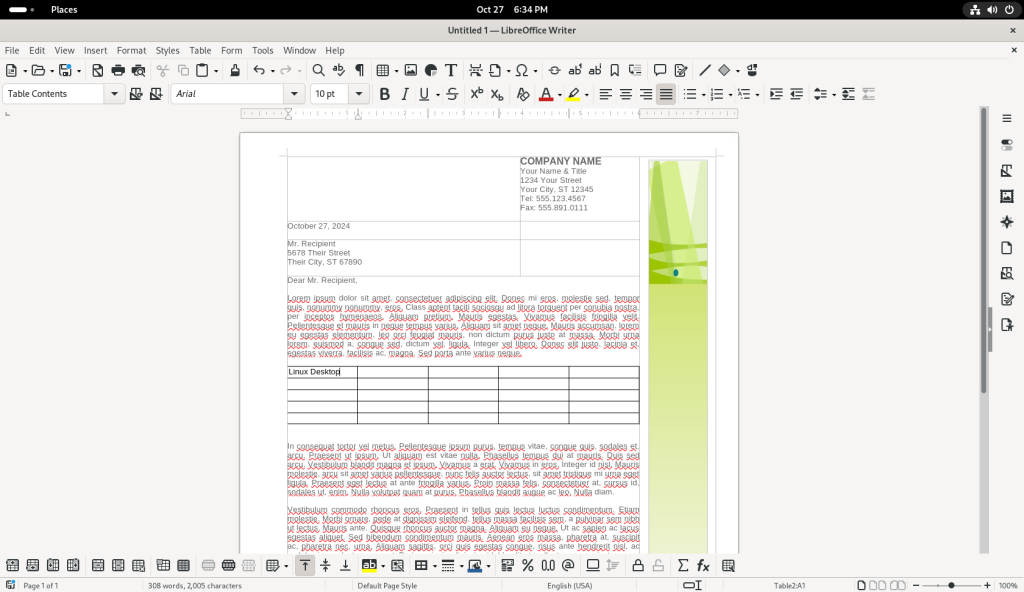
Text was added to a cell in the upper left hand corner (“Linux Desktop”):
Text added to table cells
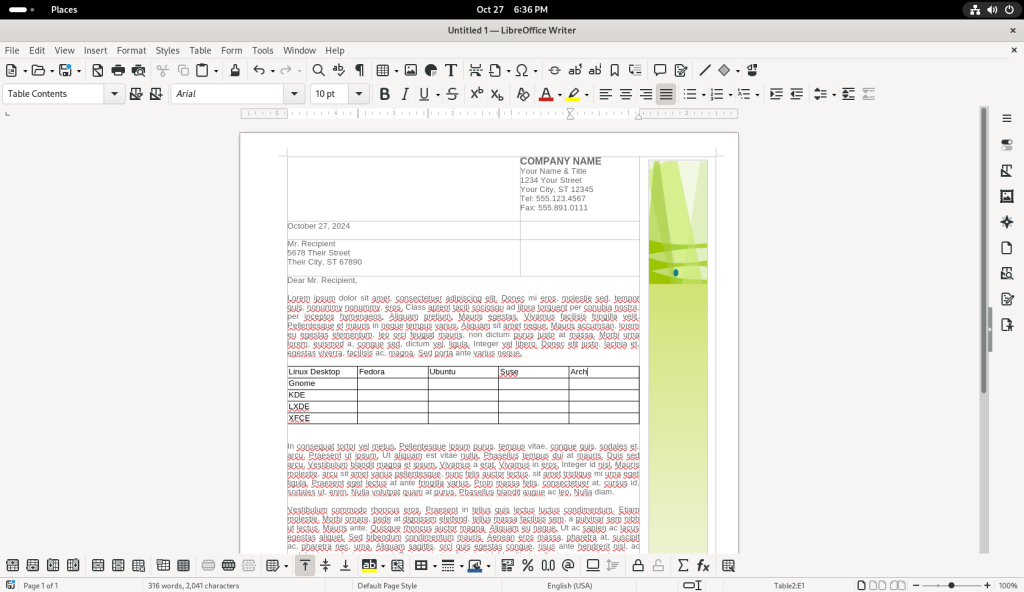
A number of other cells were filled in:
Text added to table cells
The “File” drop down menu was opened:
File menu opened
… and the file was saved:
File saved
As with the previous section, I leave it to the reader to further explore LibreOffice Writer to see the various options in the various menus, and the various kinds of text documents that can be created.
Spreadsheets:
Much like other popular desktops, Fedora Linux has several fully functional and fully featured spreadsheet software. One of the most popular such pieces is LibreOffice Calc.
After saving the business cards, I returned to the freedesktop.org website, browsing the spreadsheet templates:
opendesktop.org page sorting for spreadsheets
opendesktop.org page sorting for spreadsheets
opendesktop.org page sorting for spreadsheets
opendesktop.org page sorting for spreadsheets
I chose the Amortization Schedule:
opendesktop.org page with amortization schedule
The amortization Schedule was downloaded:
Amortization schedule downloaded
Amortization schedule downloaded
Similarly to previous files, the Amortization Schedule was opened (file double clicked in the file download directory).
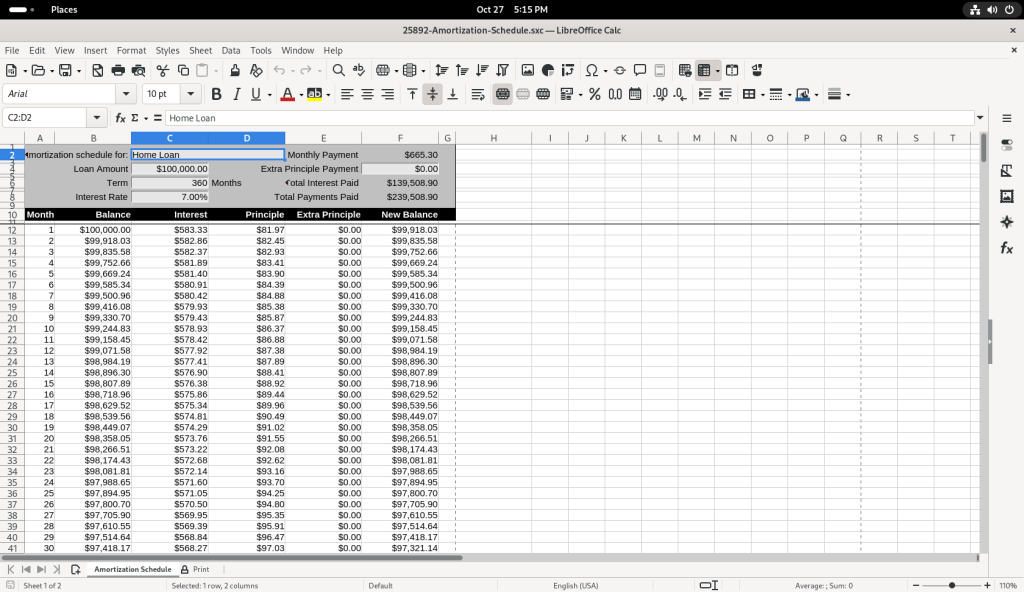
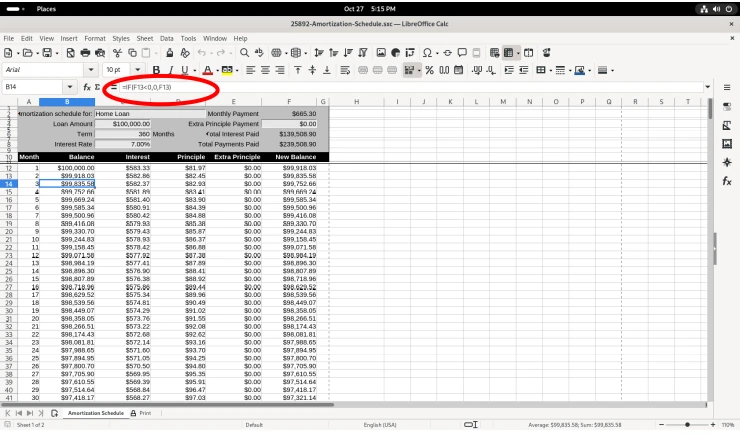
Amortization schedule opened in LibreOffice Calc
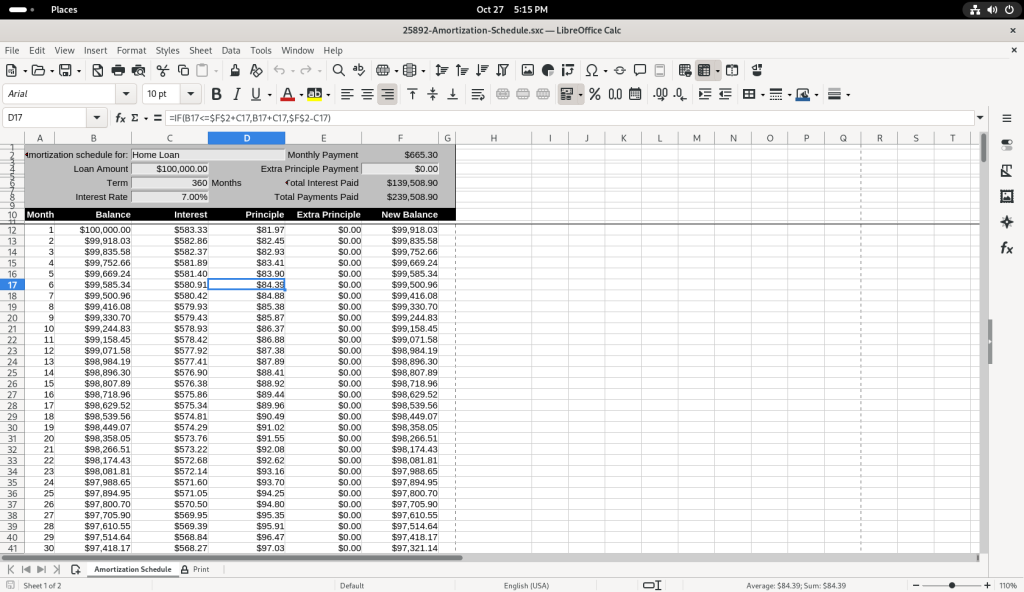
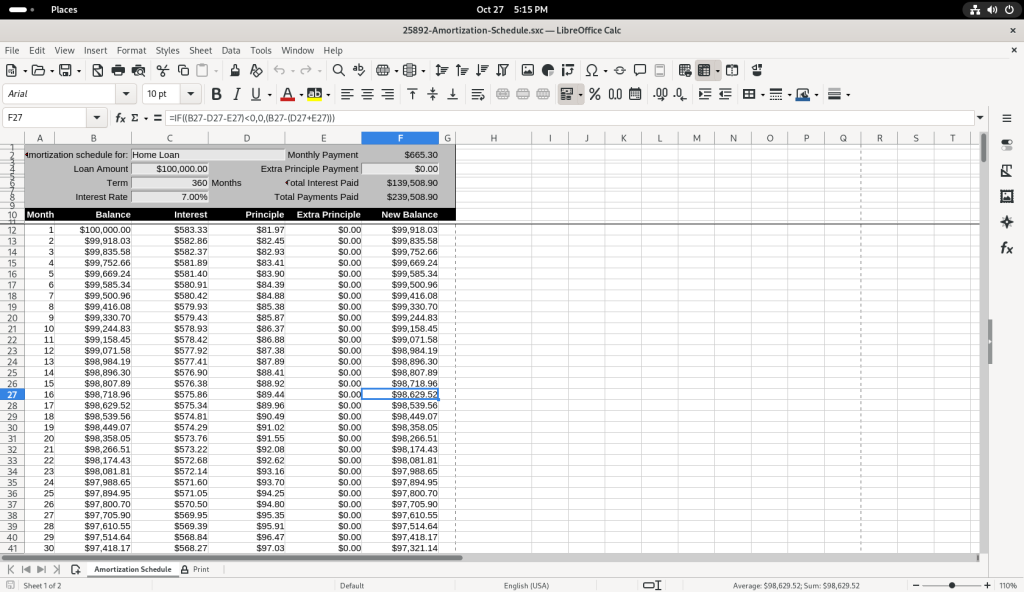
Several of the balance figures was selected, revealing how the value us calculated in the formula bar:
Amortization schedule, cell calculation revealed
Amortization schedule, cell calculation revealed
Amortization schedule, cell calculation revealed
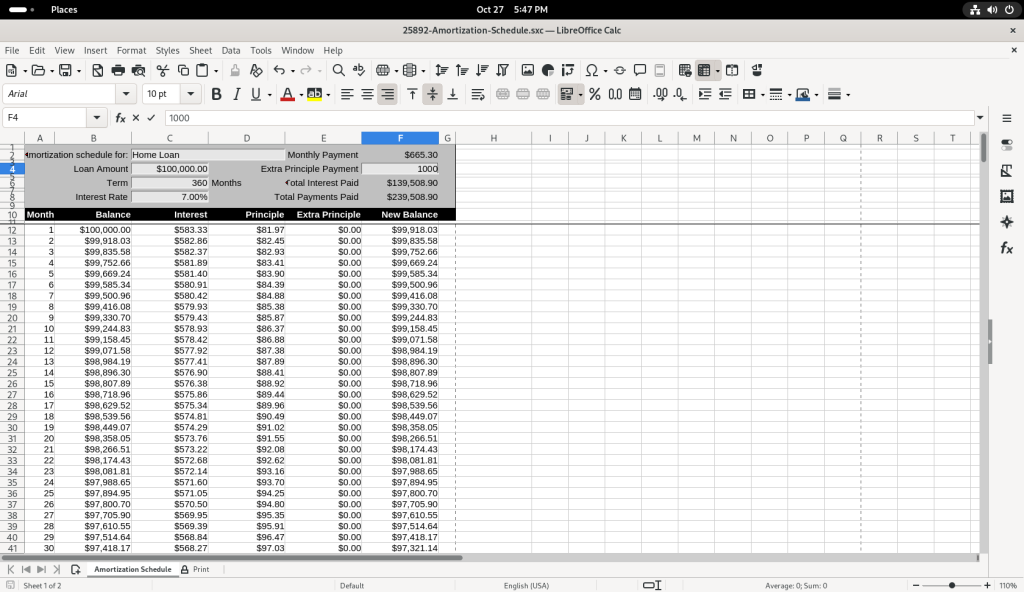
I chose to modify the table, by adding a value of 1000 in the “Extra Principle Payment”, to change the values of “New Balance” …
Value changed to 1000
… and then I changed the value to 500 to see how it affected the values of “New Balance”.
Again I leave it to the reader to further explore mounting spreadsheets of their own using their own data.
Slide Shows / Presentations
At the opendesktop.org collection of templates, I chose a slide show template to download:
opendesktop.org page sorting for a presentation template
I chose a template to download …
Presentation template downloaded
… and downloaded it:
Presentation template downloaded
Presentation template downloaded
Again through the files directory, I double-clicked on the downloaded file:
File in download directory double clicked
… which opened up the file in LibreOffice Impress:
Presentation opened in LibreOffice Impress
I began editing the title line — in the process, using the wrong branding for this series!
Text modified
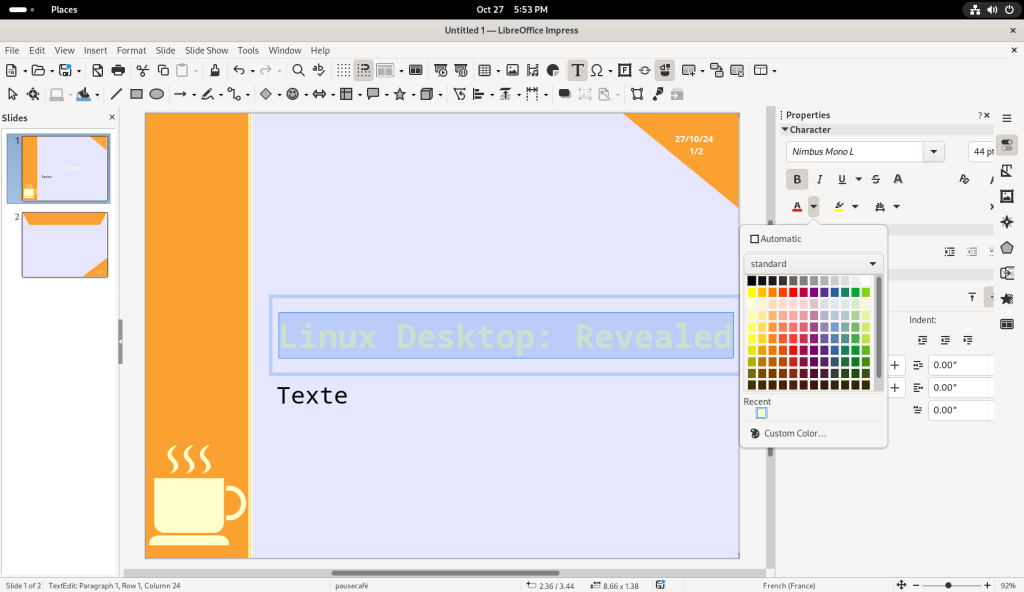
The text colour, white, didn’t have enough contrast for my taste, so I selected the text …
Text colour modified
… and went into the options area on the right to by clicking on the letter “A” with a red underline, to change the font colour:
Text colour changed through menu icons on the right
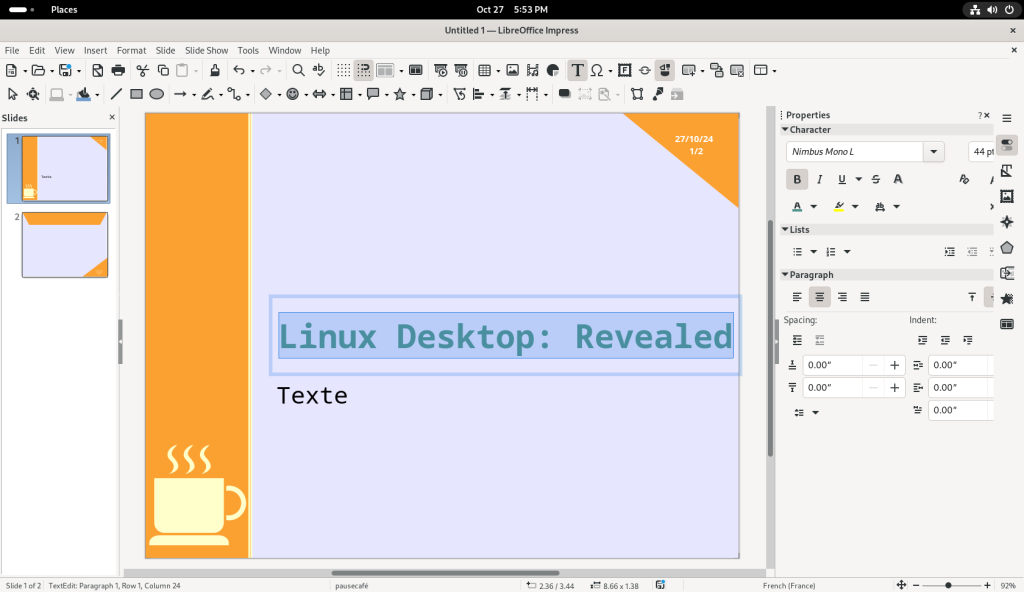
The font colour was changed to a greenish-blue colour:
Text colour changed to a greenish-blue
Text colour changed to a greenish-blue
Other text was changed and added:
Text added below title
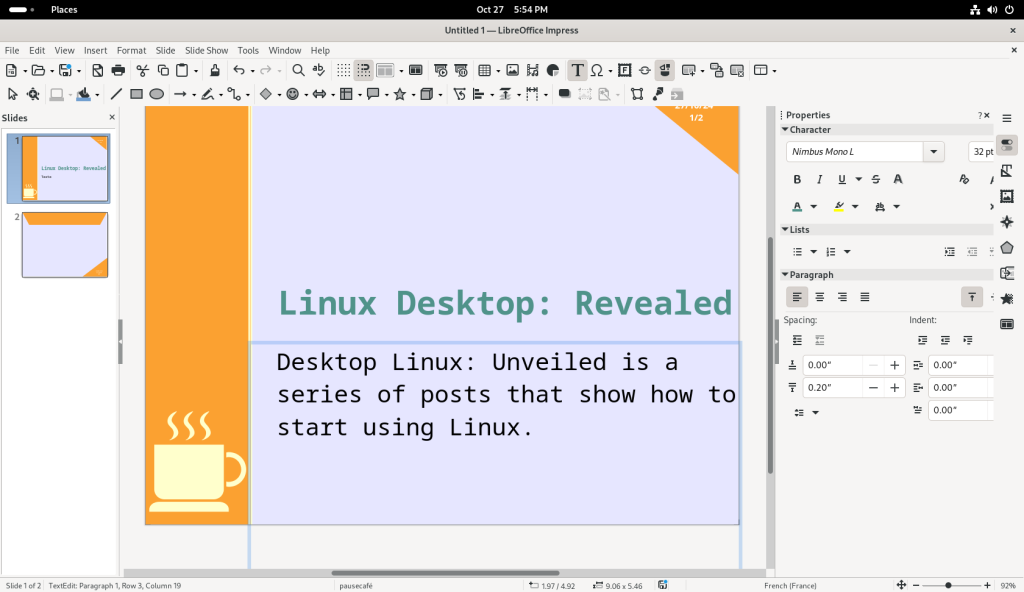
I changed to the second page, and similarly started to change the text:
Navigating to second page
Text can be changed as per your needs, as well as pages added through copy / paste or other wizards available.
The drop-down file menu was chosen, so that I could save the file:
File drop down menu to save the file
File saved
Once the file was saved, I opened up the drop-down file menu again, and chose “Export As” so that I could export the file as a PDF. (Editorial note: As mentioned earlier, while there is a good amount of compatibility between LibreOffice and other office suites, it can be disappointingly incomplete, which I have particularly seen and experienced with — but not only — slide shows. For more of a discussion of such from the perspective of the usefulness of PDFs, please see my post on the subject.)
The file drop-down menu was clicked again, and the option “Export As” was clicked:
File menu opened to export the file as a PDF
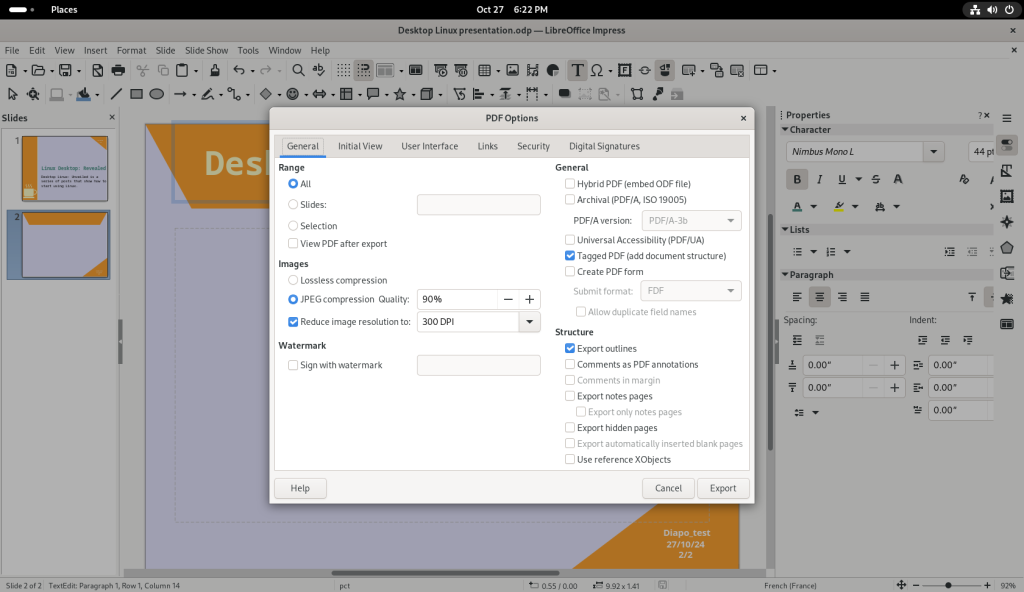
Exporting to PDFs can be rather easy and direct, or, as I am going to show a little bit here, allows for a large amount of choices …
Options window for PDF options
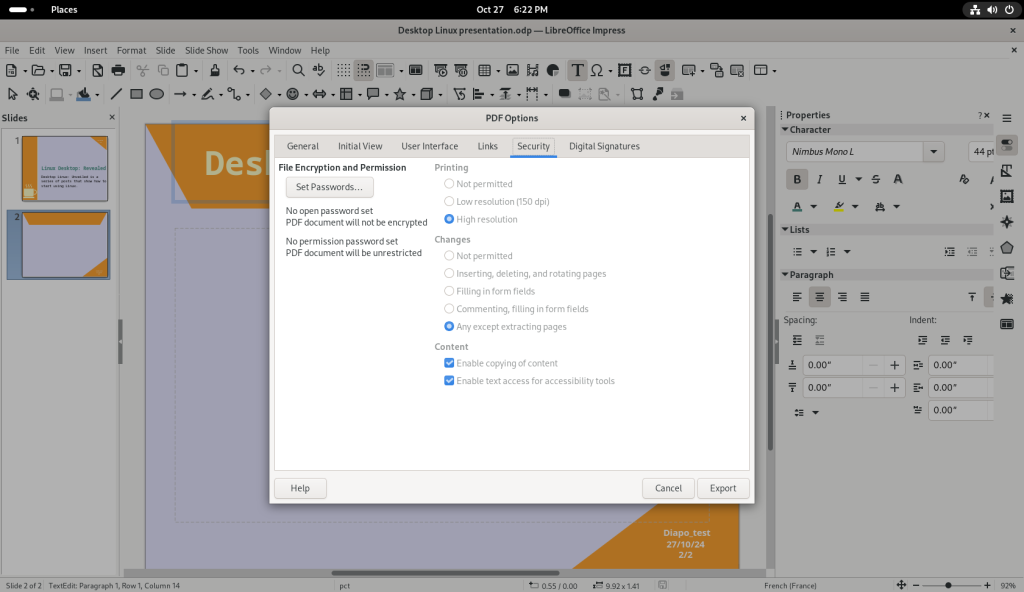
… including protecting PDFs with passwords for opening:
Tab with options for password setting for opening PDFs
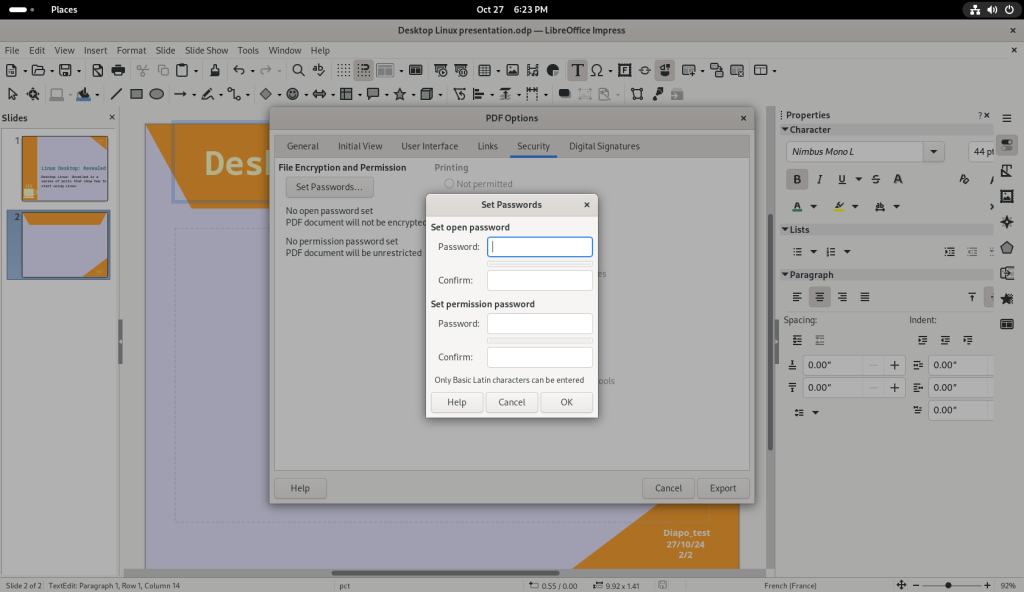
Setting passwords for PDFs
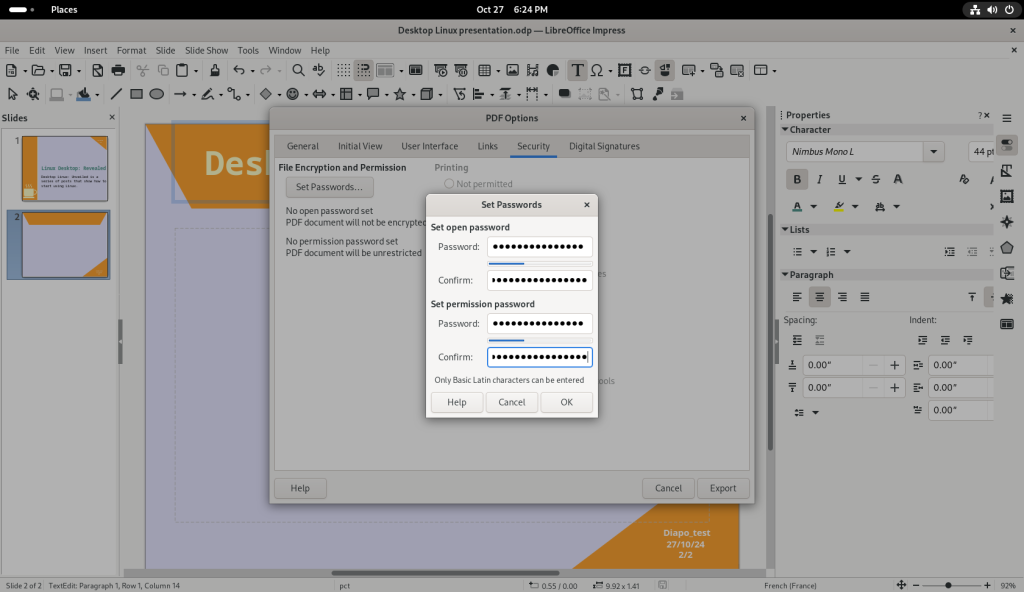
Passwords were set for both opening as well as for “permission” which means to allow editing of the PDF (see my post on the subject), and the slide show was exported as a PDF:
Setting passwords for PDFs
… and the OK button was clicked:
Presentation exported to PDF
As usual, I leave to the reader to explore further. Also, within LibreOffice itself it has a wizard to help the user create a number of presentations with various backgrounds and layouts.
Database:
LibreOffice also includes a database module, called “Base”, which is similar to Microsoft Access; it is essentially a front end manager — a gui interface — for the actual database software behind it that it leverages.
Before I show a properly mounted database, I will show some screenshots about how to start.
Starting from the home screen, the activities corner (hot corner) in the upper left was clicked:
Desktop screen
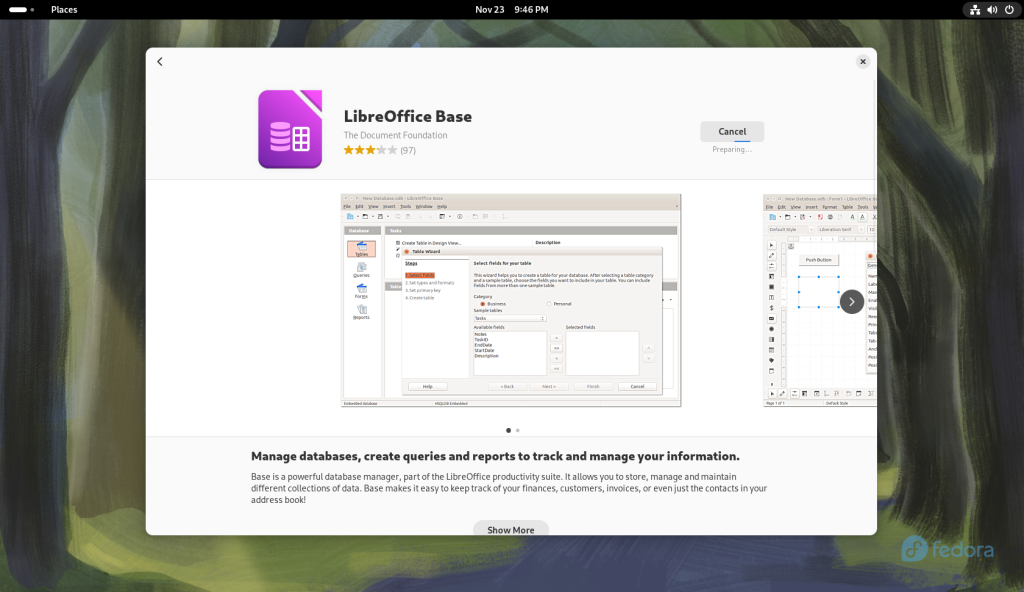
On the Activies screen, “libreoffice base” was typed into the search bar, and the option to install LibreOffice Base, which is not always installed in a base install, was offered:
Activities screen accessed, and “libreoffice base” searched for; the option to install Base was offered
The option was double-clicked, which brought up the “software store” with the choice of LibreOffice Base …
Software store opened to allow for installation of Base
I double-clicked on the option, bringing up the information page on the package and the offer to install it:
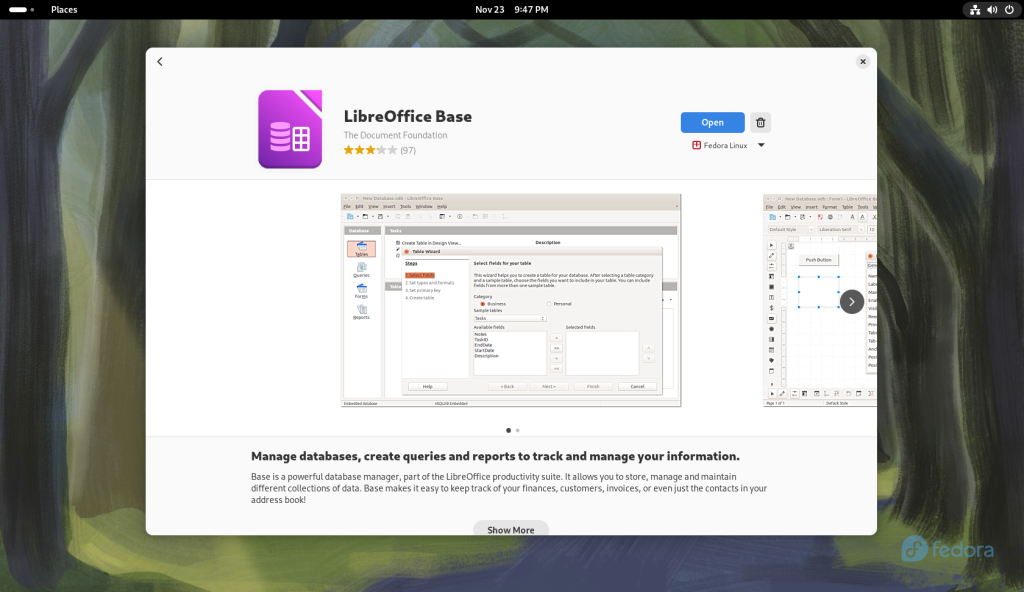
Description page for Base
I clicked the “Install” button:
Base installing
Once LibreOffice Base was installed, an “Open” button presented itself:
Base opened
The “Open” button was clicked, lauching LibreOffice:
Base opened
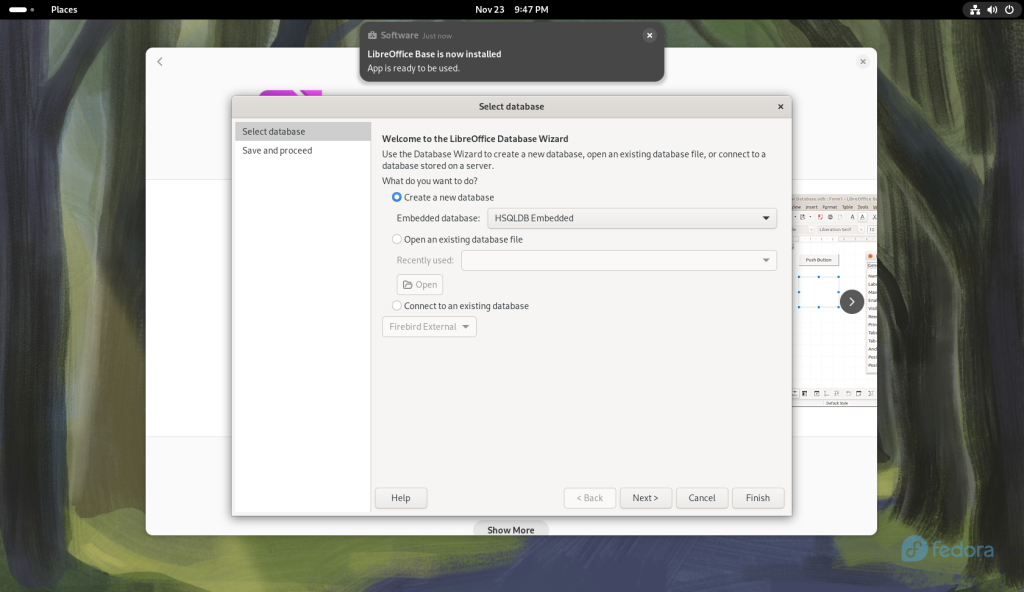
A wizard came up to select a database:
Wizard opened to allow choice to launch Base
The presented option was accepted, and the “Next>” button was clicked, bringing up a “Save and proceed” window:
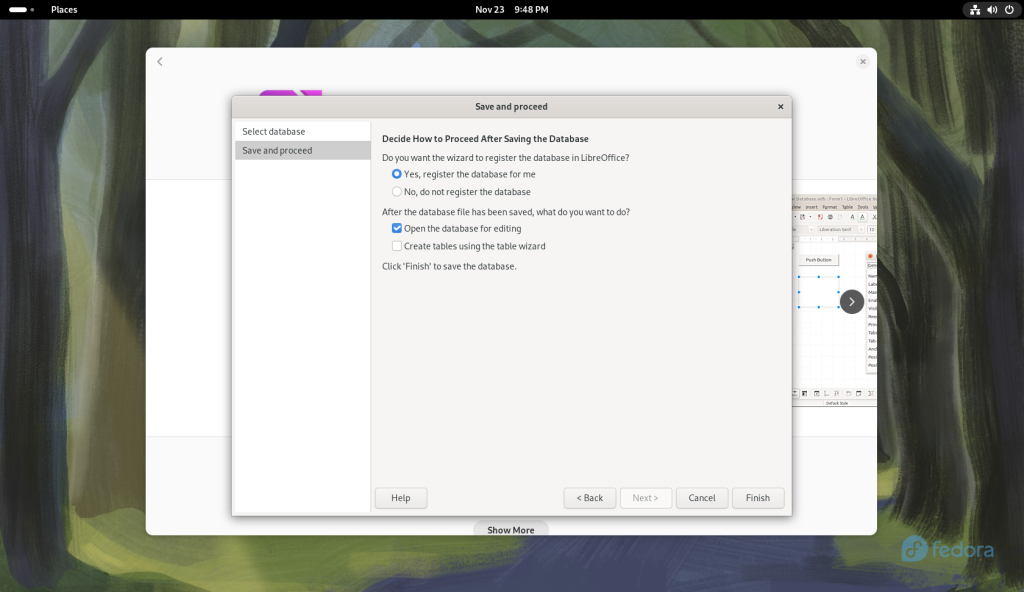
Save and proceed window
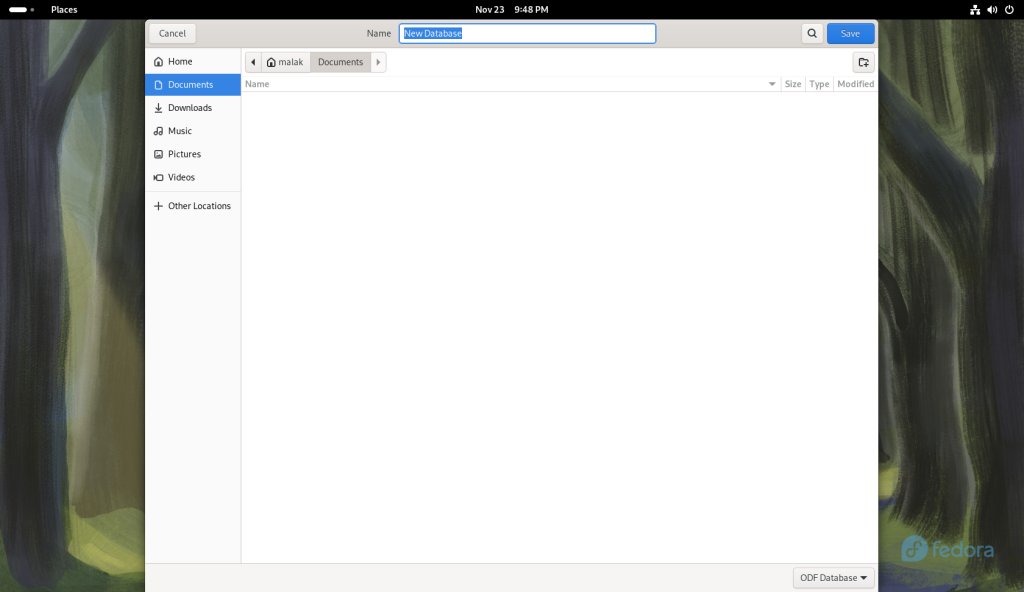
The “Finish” button was clicked, opening a Save window:
Finish button clicked, allowing for the creation of a database
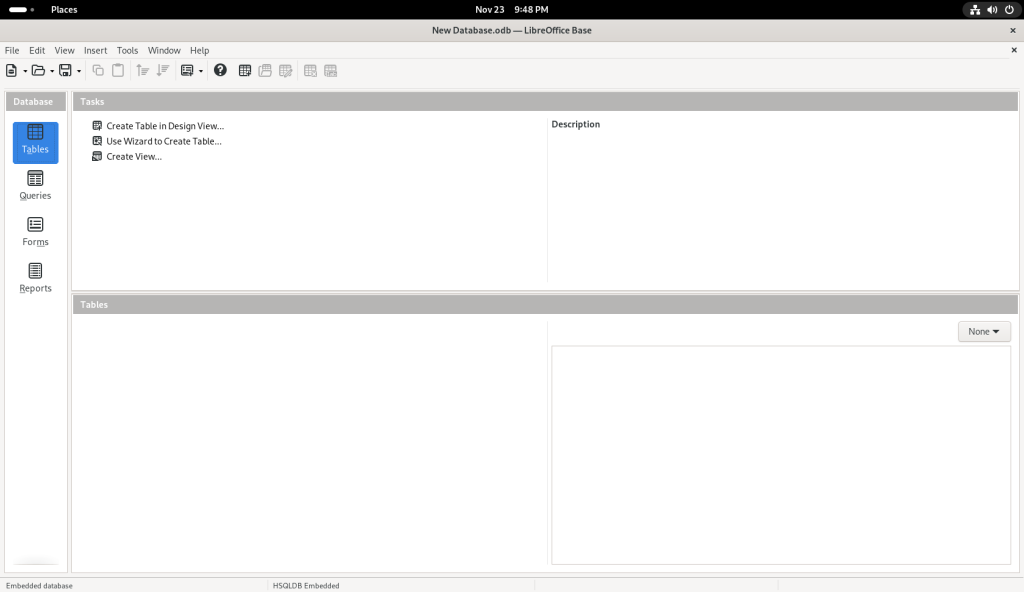
Once that was done, the following screen came up, in order to start creating a database:
Initial screen for creating a database
Note that from this point on, I am showing some very basic things, and I will soon recommend a tutorial, which will better show how to use the software than I could ever present.
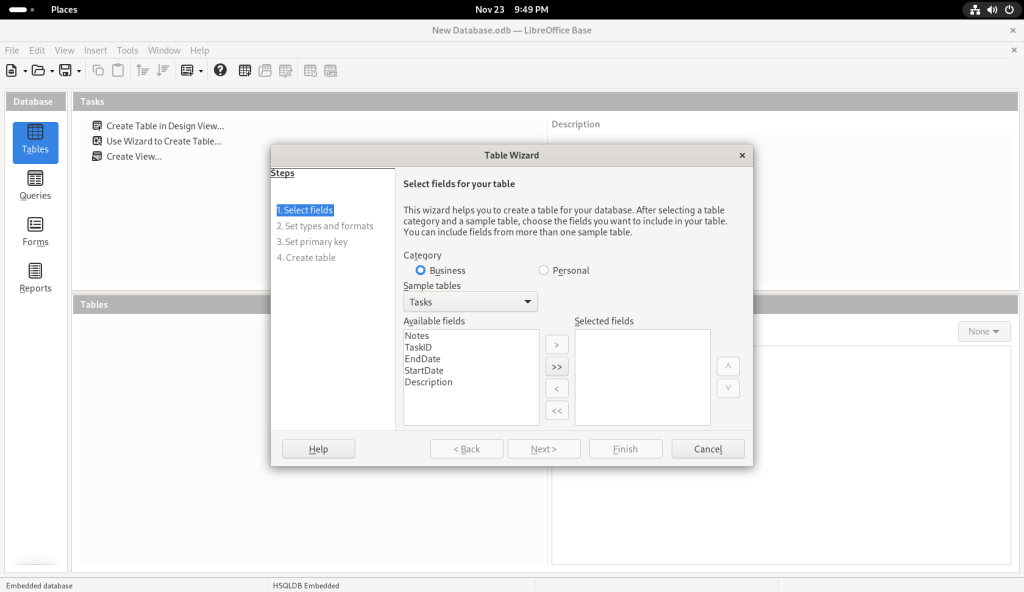
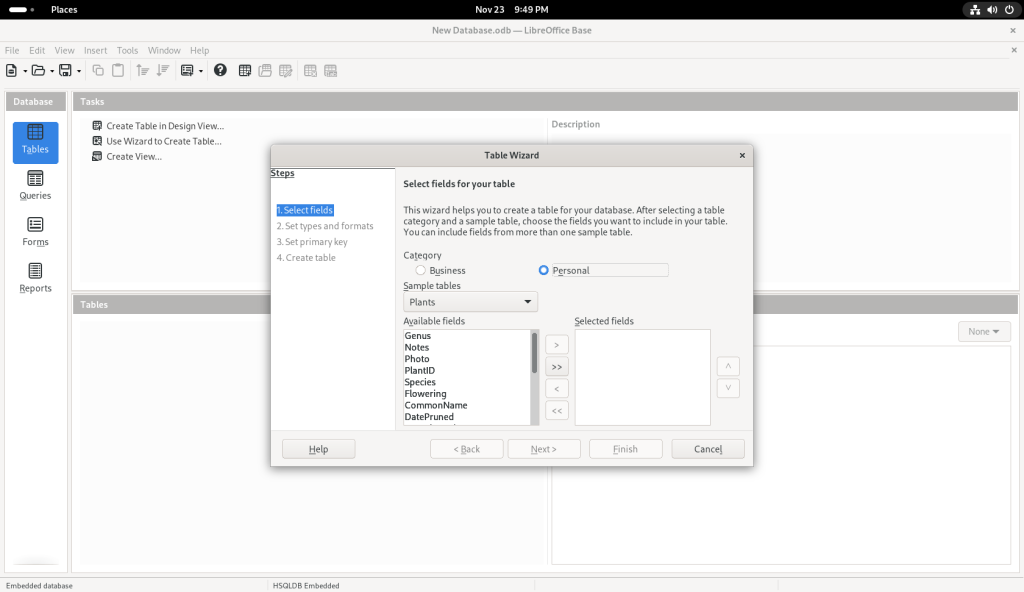
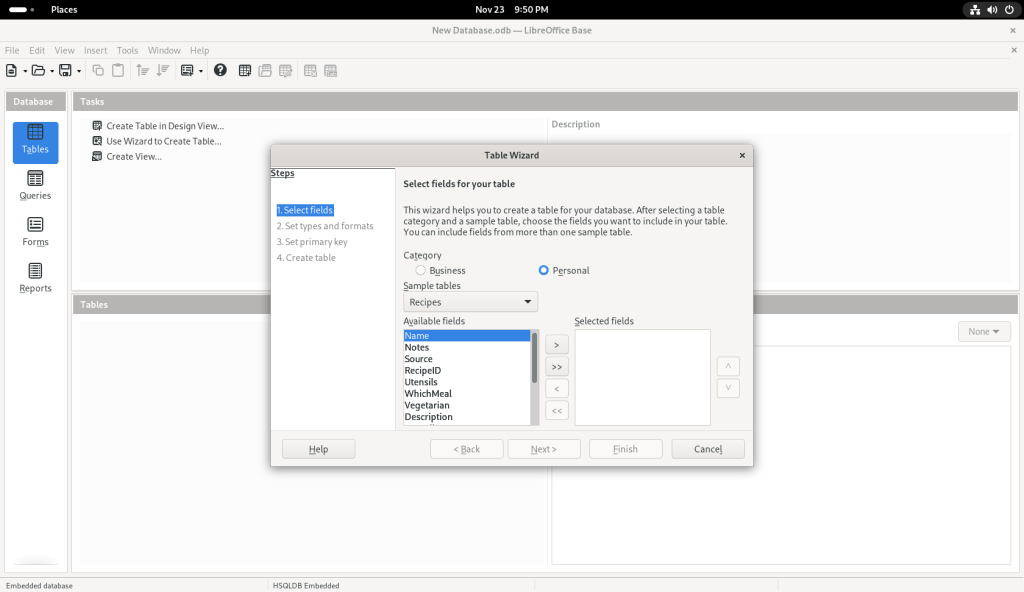
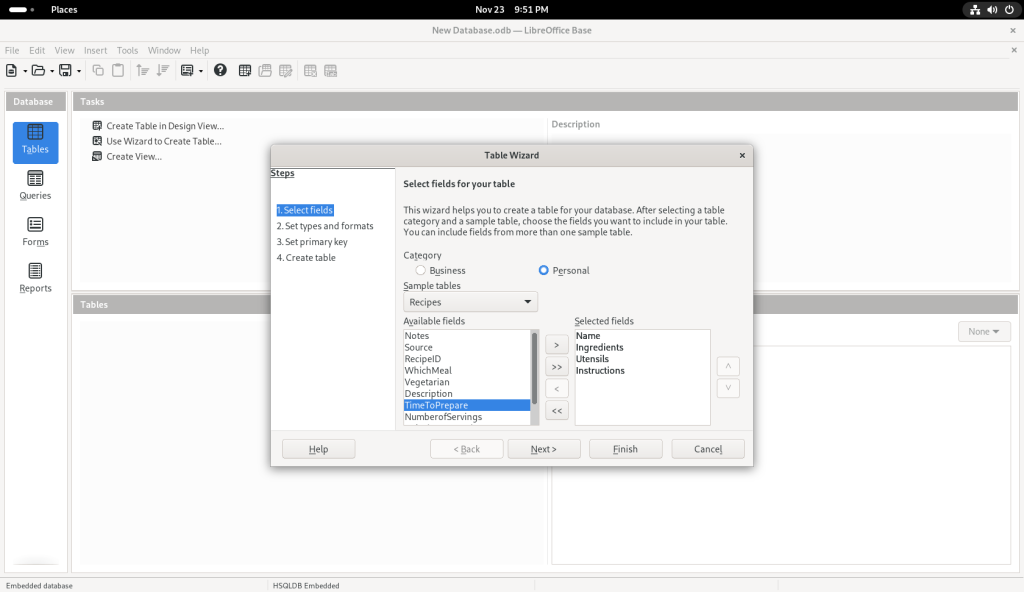
I clicked on the “Table” icon, which brought up a Table Wizard:
Table Wizard launched
I chose the “Personal” category, on the premise — in the context of this post, anyway which presumes that many readers may be seeking to use linux at home and not just at the office, and that a database might not as easily appear to be a personal piece of software.
Personal category chosen
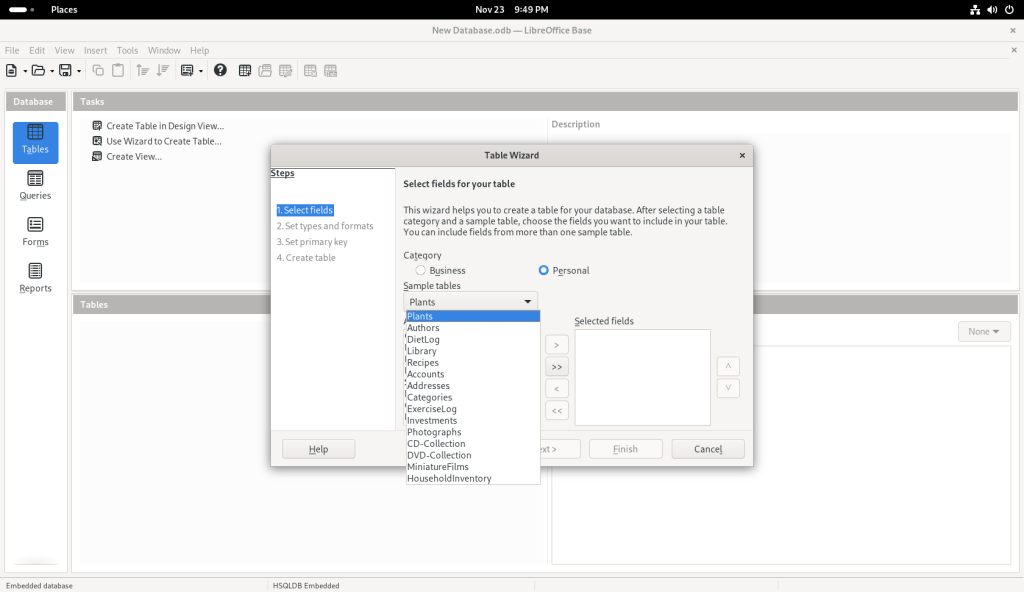
I pulled down the suggested list of topics:
Suggested list of topics
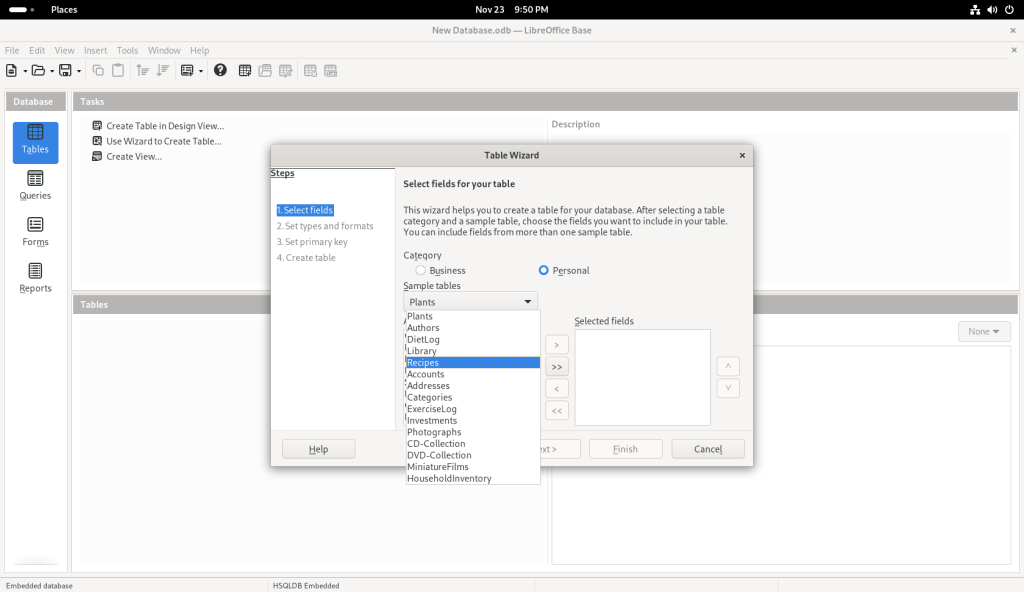
… and chose “Recipes” for what I presume are obvious reasons — we all eat, and presumably many people have a personal collection of varying sizes (here’s my collection of recipes, incidentally NOT in a database format, at https://www.malak.ca/food).
Recipe option chosen
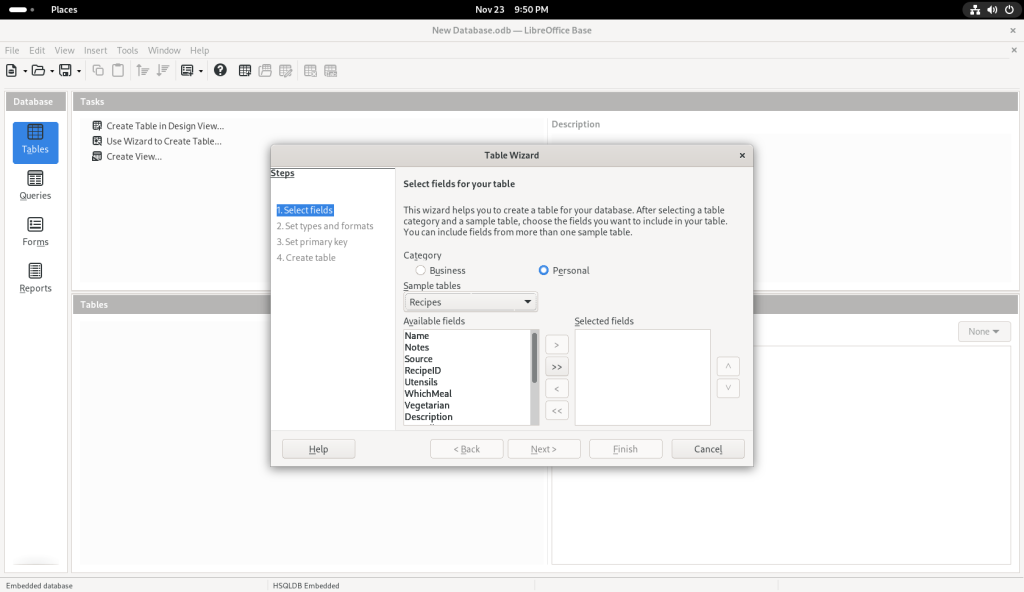
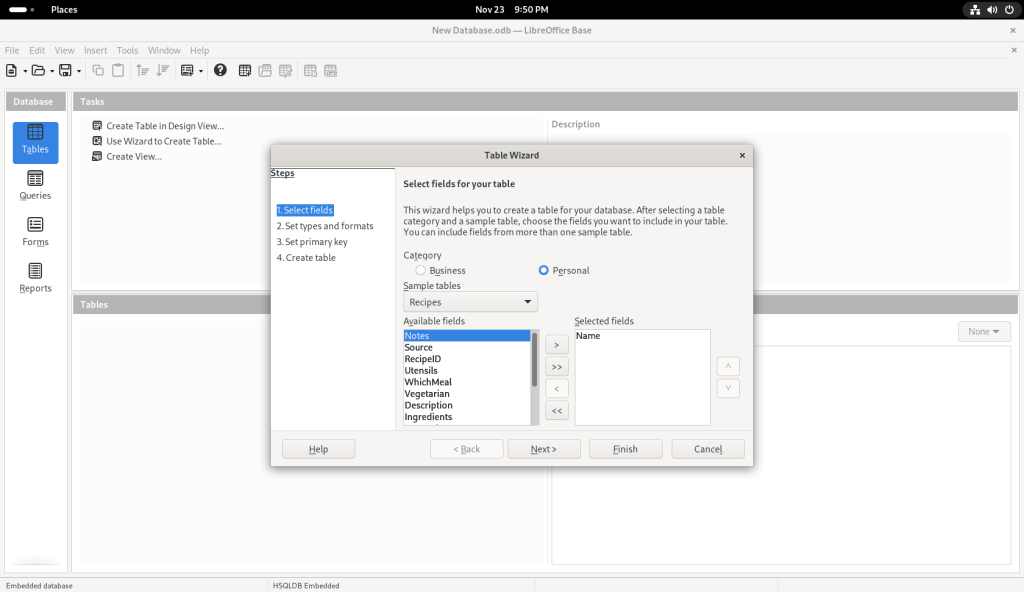
Some field names were suggested:
Field names suggested
I clicked on “Name”:
Name selected
… which moved it over to the column on the right:
Name field moved to right window
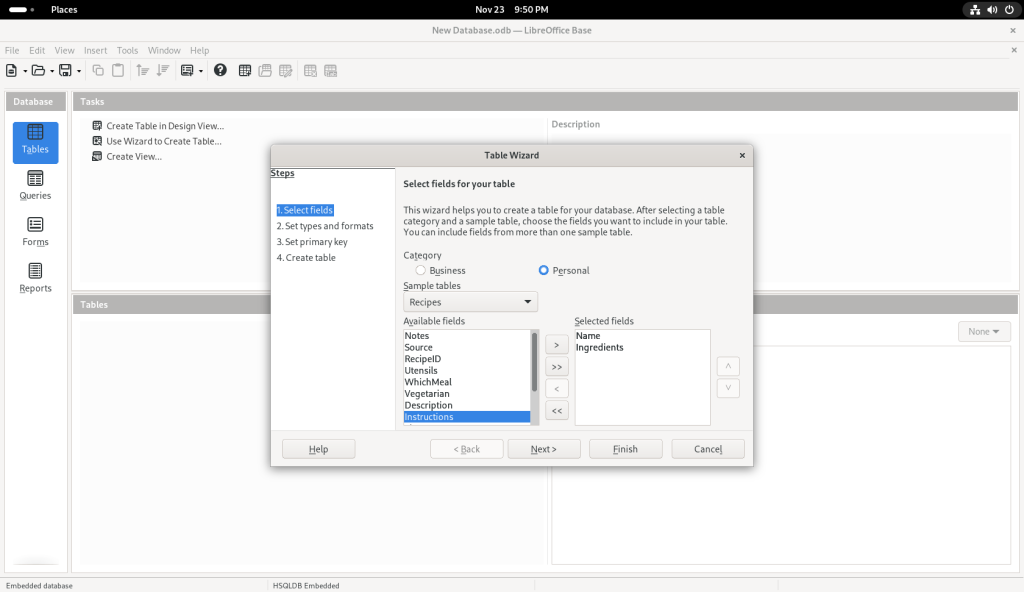
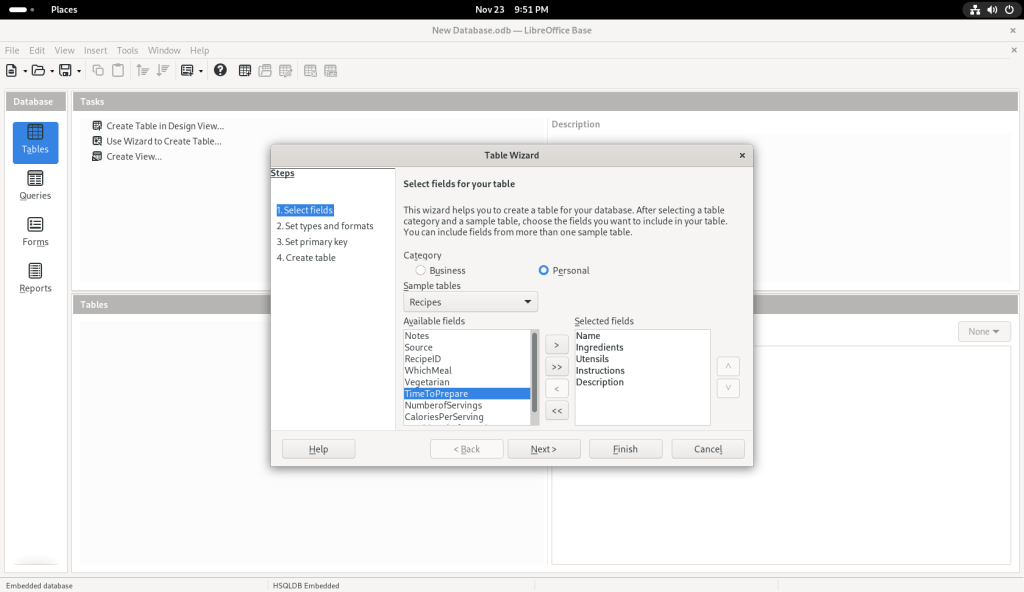
I also chose other sample tables:
Ingredients field chosen
Utensils field chosen
Instructions field chosen
Description field chosen
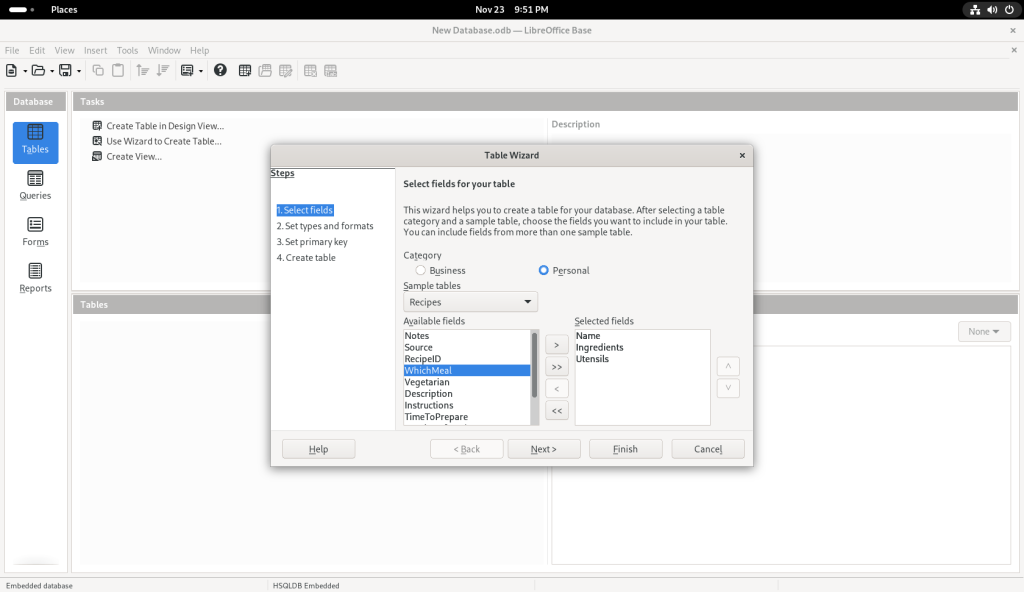
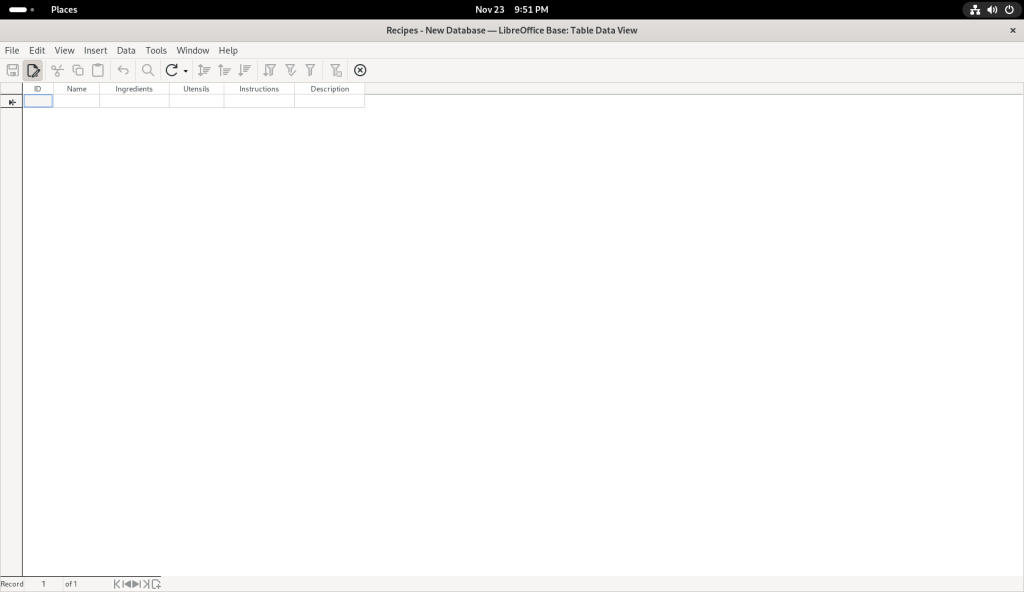
… at which point, I clicked on the “Finish” button, leading to the following screen:
Finish button clicked, leading to a data entry page
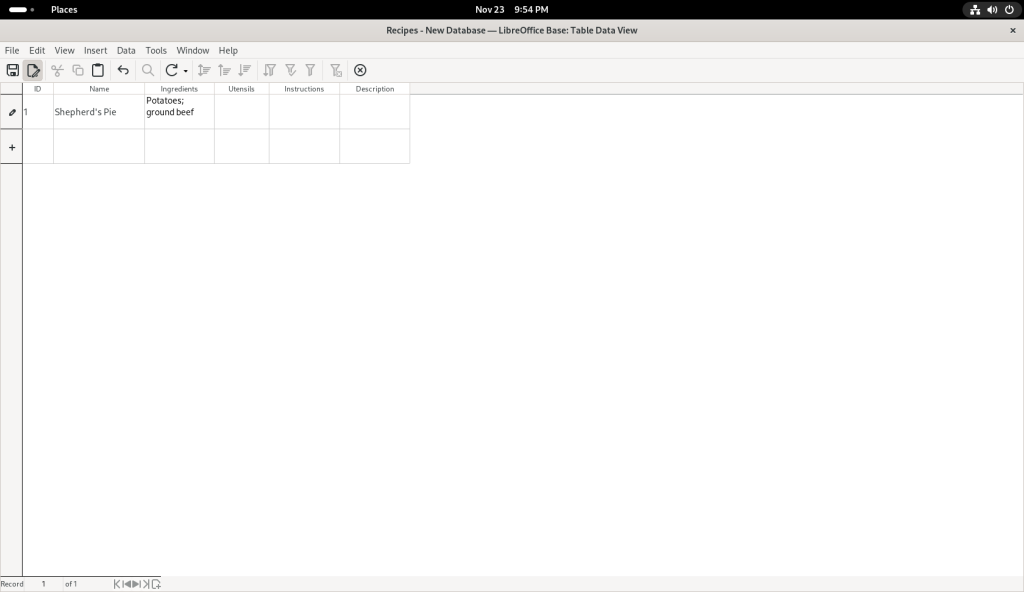
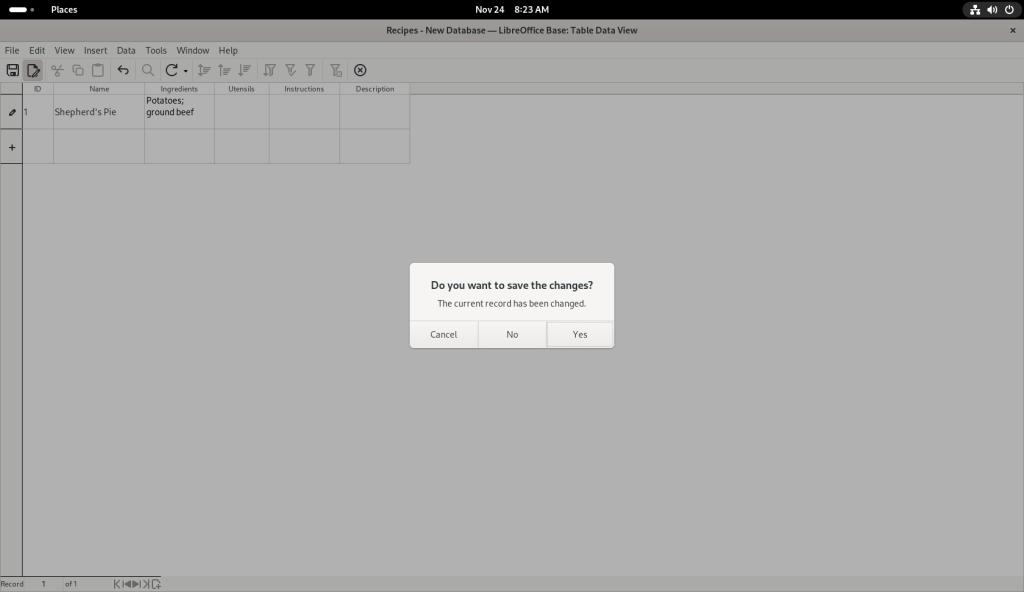
I started entering data:
Data entered
I chose to save my changes:
Database saved
At this point, I am going to direct you to a far better tutorial than I could ever present, even in the most cursory of fashions:
As of the writing of this post, a rather complete tutorial on using Base can be found at thefrugalcomputerguy.com/seriespg.php?ser=15/ (no doubt amongst countless other similarly excellent resources):
TheFrugalComputerGuy.com LibreOffice Base tutorial page
TheFrugalComputerGuy.com LibreOffice Base tutorial page
Although I think it best to leave the tutorial to TheFrugalComputerGuy, I will show a small database in action:
Starting again at the desktop screen:
Desktop
The activities screen was accessed through the upper left hand hot corner with the mouse:
Activities screen with the dock
The Firefox icon (orange, on the left on the dock at the bottom) was clicked:
Firefox web browser launched
I went to my favourite search engine, duckduckgo.com:
Search engine opened (in this case www.duckduckgo.com)
… and I searched for “libreoffice base templates”:
Searching for Base templates
Searching for Base templates
I chose the “Templates & Extensions” link, the second link above, at the LibreOffice.org site itself:
Templates at libreoffice.org
I clicked on the green “plus” sign to the right of “Boost your creativity with templates”:
Template link clicked
… which led to the following page:
Templates page
On the left, there are a number of filters under “Add tag filters:”, and clicked on “Base”, bringing up the following page:
Page with templates for Base
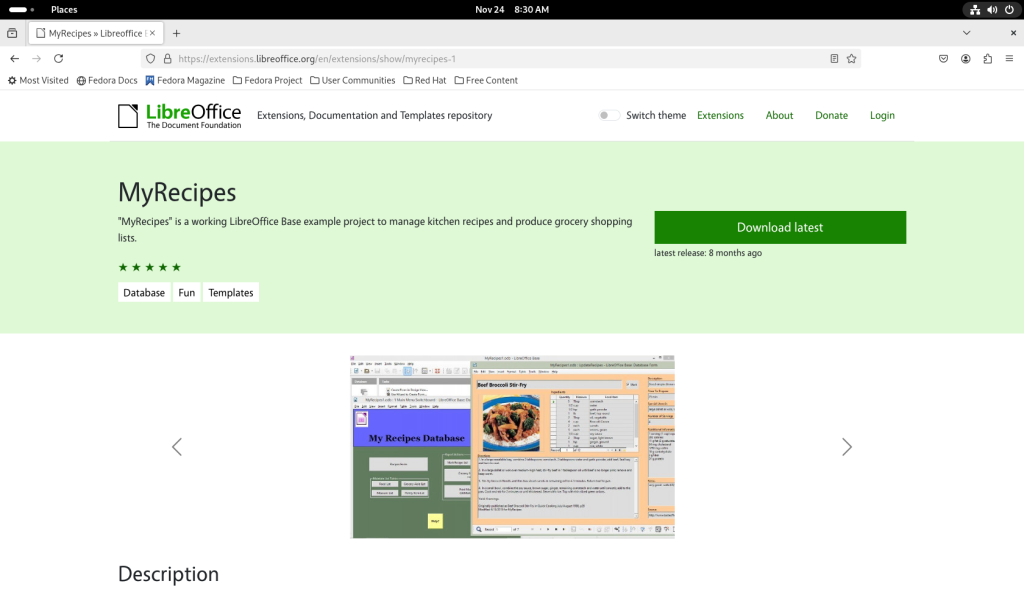
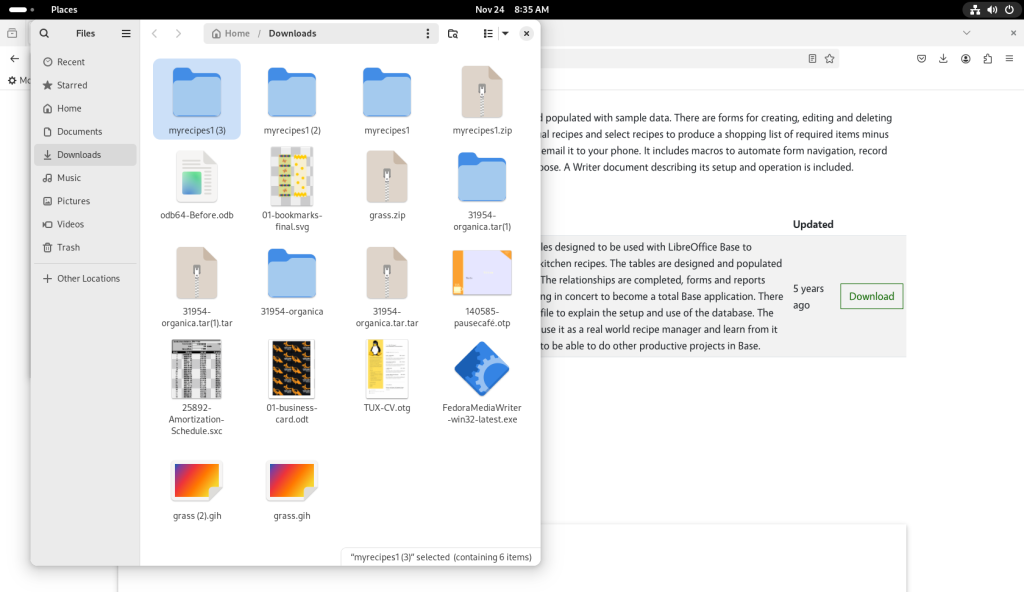
I chose the “MyRecipes” template for LibreOffice Base:
Page for a recipes database
I scrolled down to quickly assess the files, finding them eminently interesting for the task at hand:
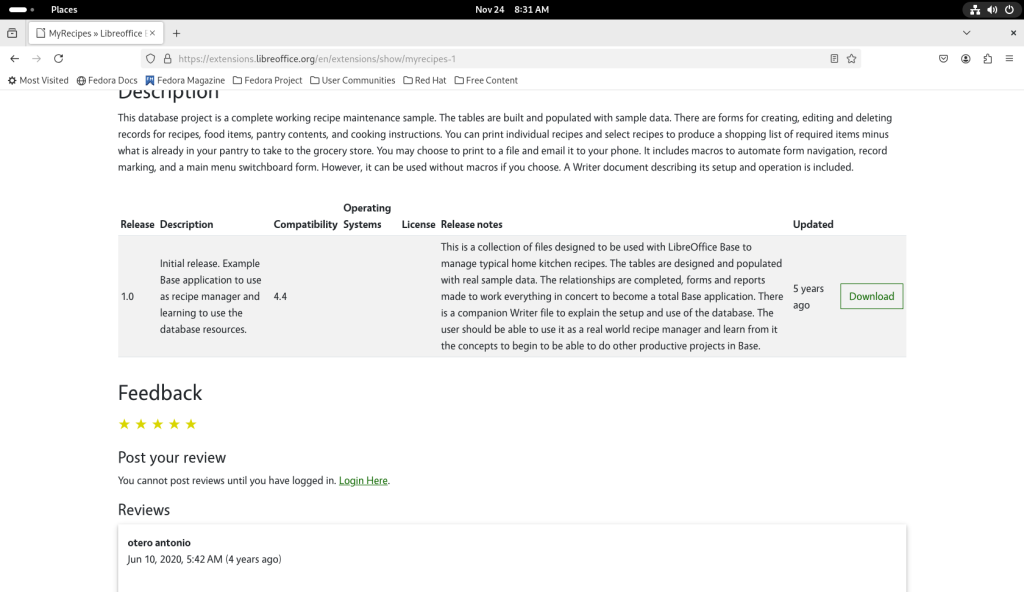
Template description
The download button was clicked, and the file downloaded:
Template downloaded
The files program was opened, and the newly downloaded file was highlighted:
Downloads directory opened
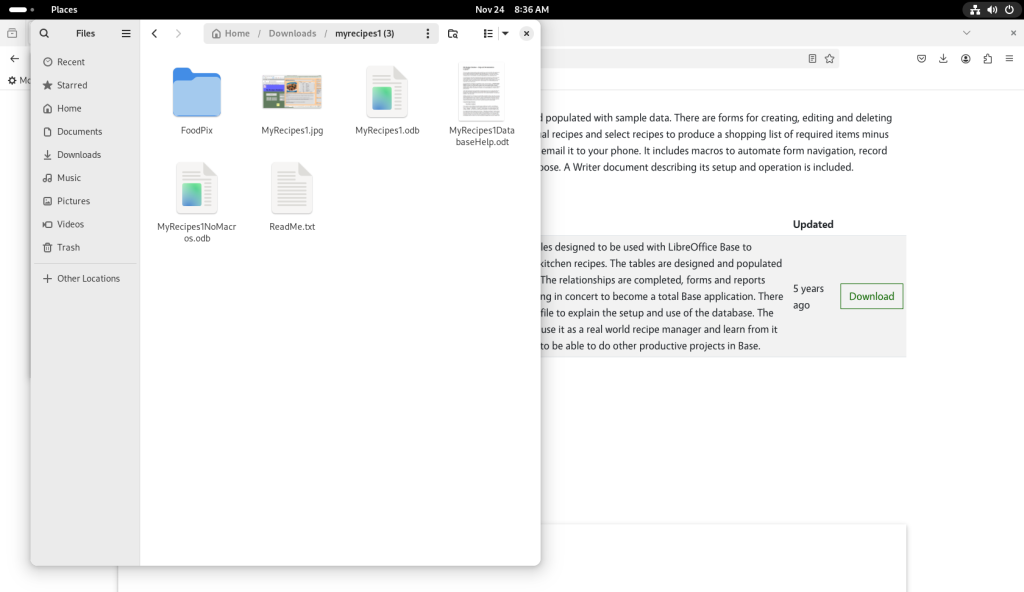
The .zip file was double-clicked, creating a directory of the files (ok I accidentally created the directory three times!)
.zip archive opened
One of the directories was double-clicked and opened:
Archive consulted
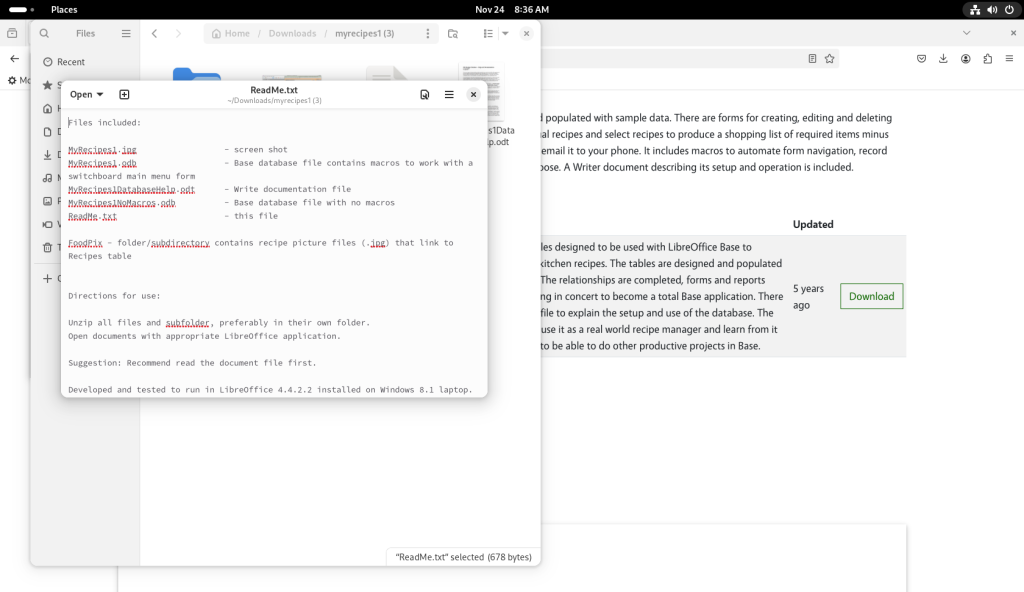
The “ReadMe.txt” file was double-clicked and opened:
readme file consulted
The .odt file was opened as well:
Instructions and general description file checked
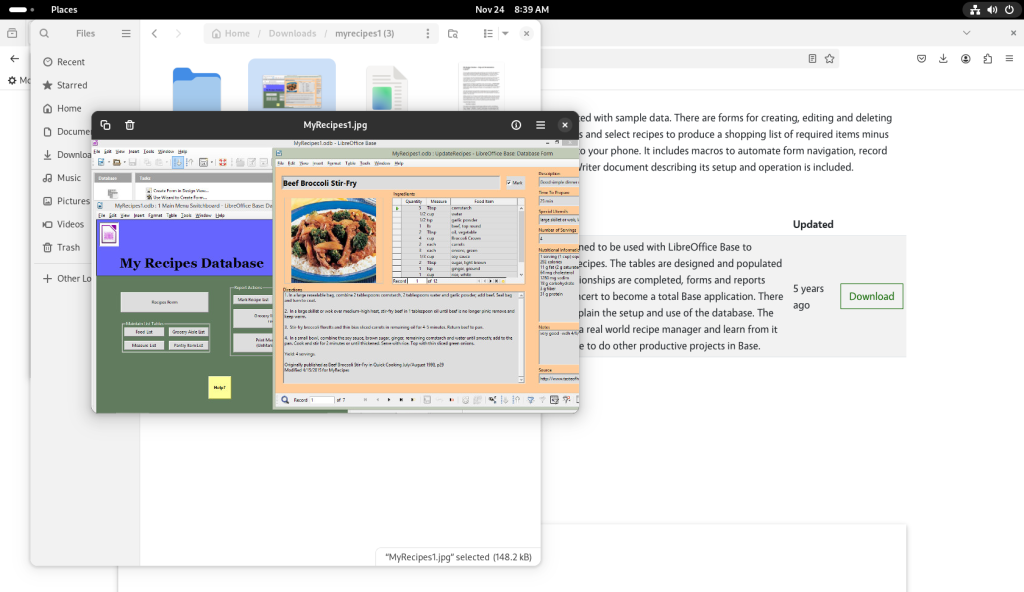
The “MyRecipes1.jpg” file was double-clicked, opening a screenshot:
Screenshot of database operating consulted
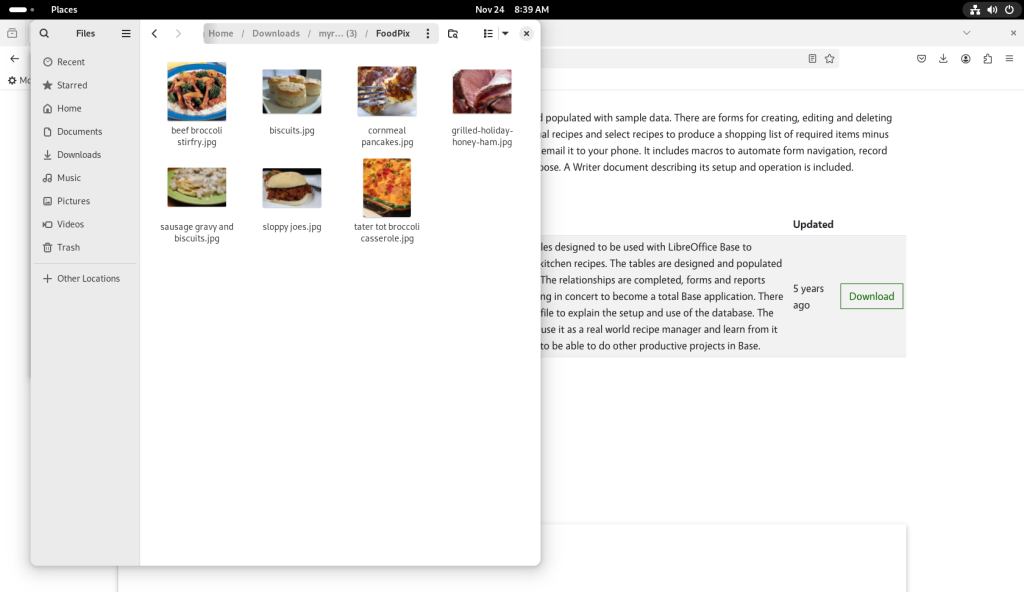
The FoodPix directory was opened, showing pictures of the recipes in the database:
Pictures included in the archive viewed
From the database’s main directory, the database was opened:
Database opened
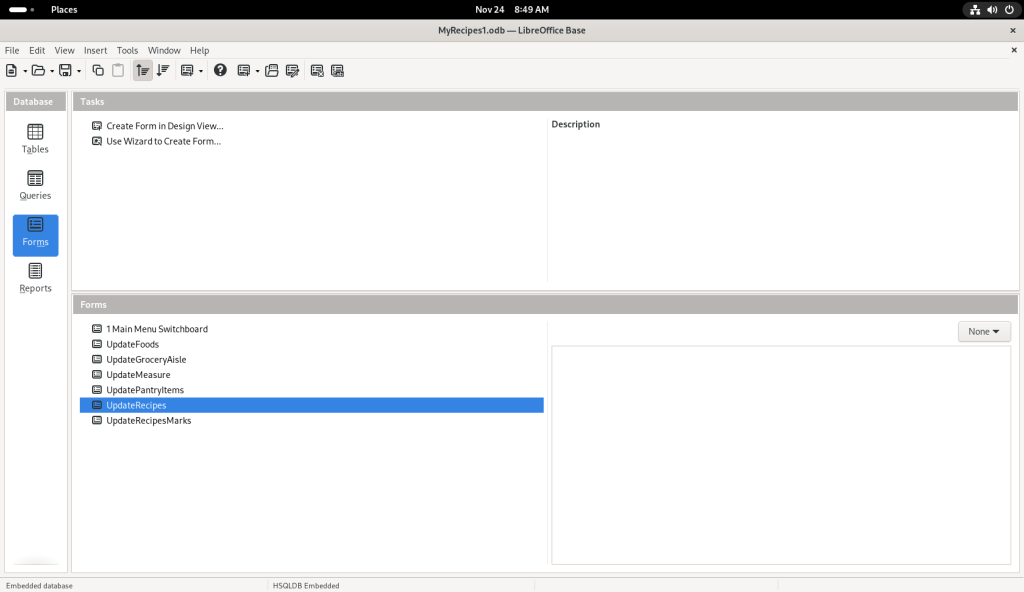
After looking about, the “UpdateRecipes” option was selected:
One of the options selected
Which opened up one of the recipes:
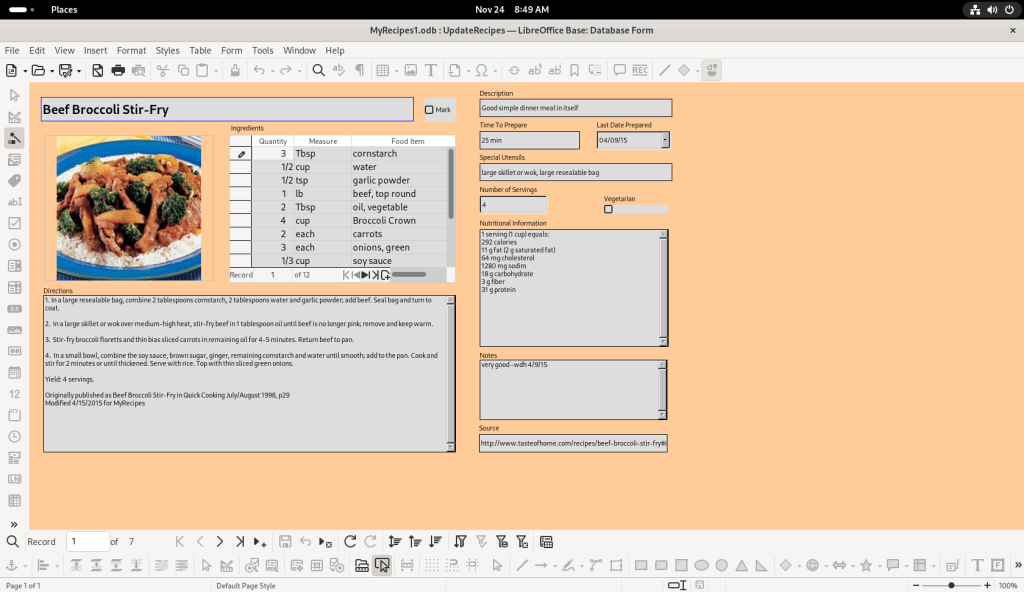
One of the recipes in the database
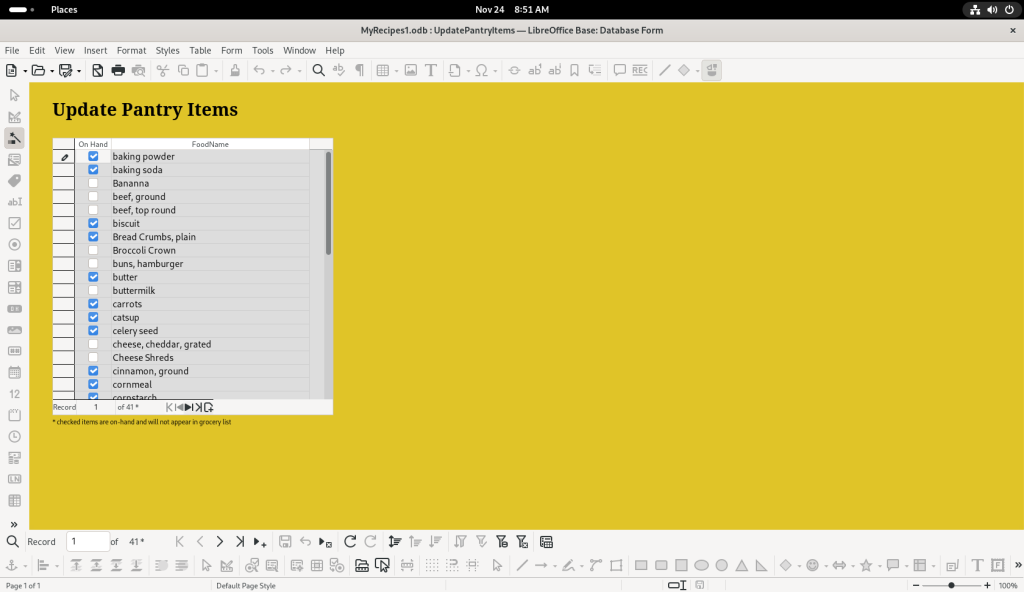
The database author chose to have an active Pantry list with checkable items, no doubt based at least partly on their recipes; by having it dynamic, when asked to create purchasing lists, the database can exclude pantry items already on hand:
Pantry list
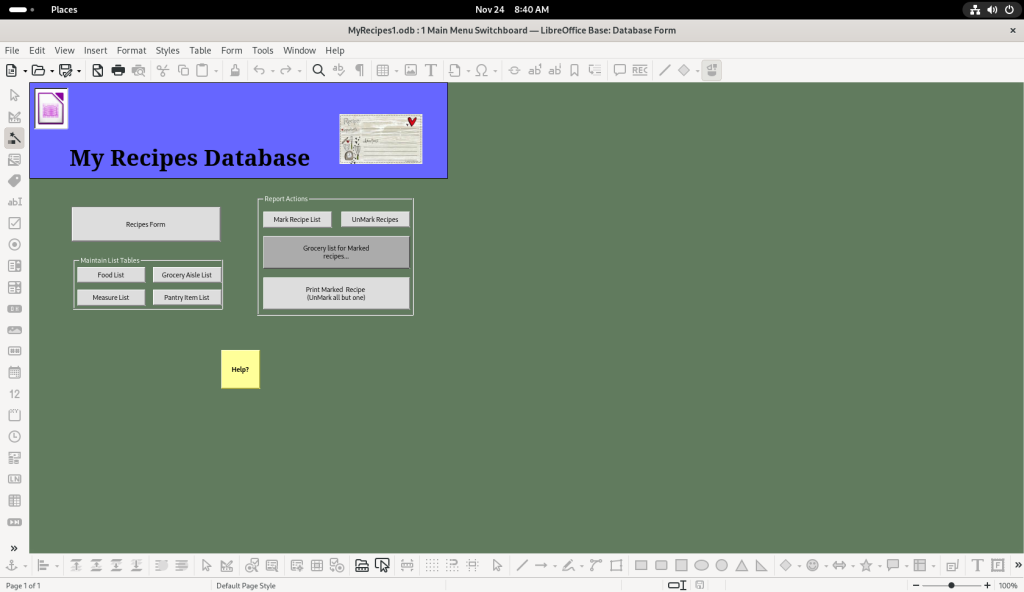
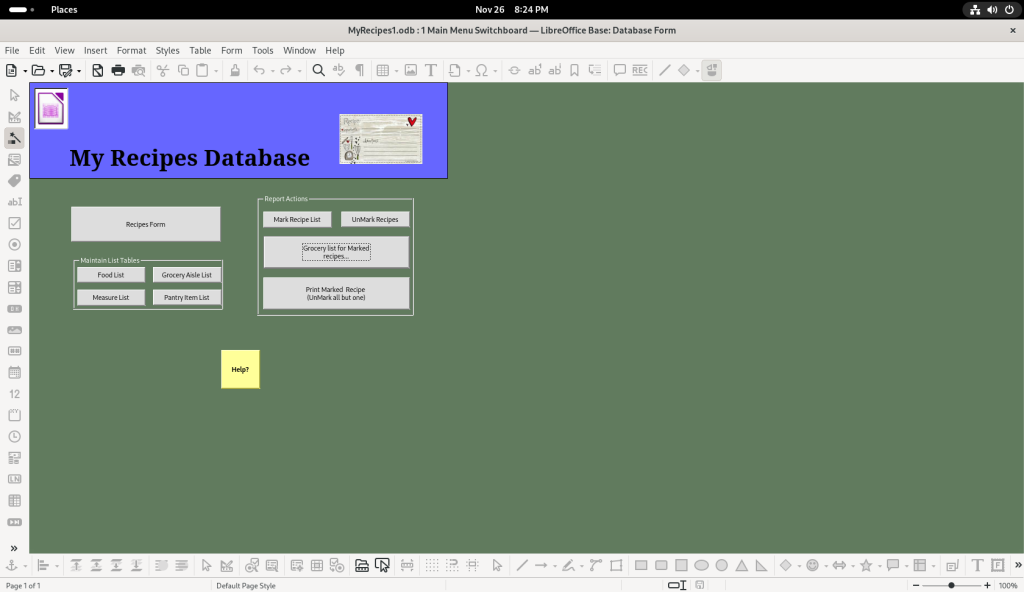
Said shopping lists can be generated from the “1MainMenuSwitchboard” option:
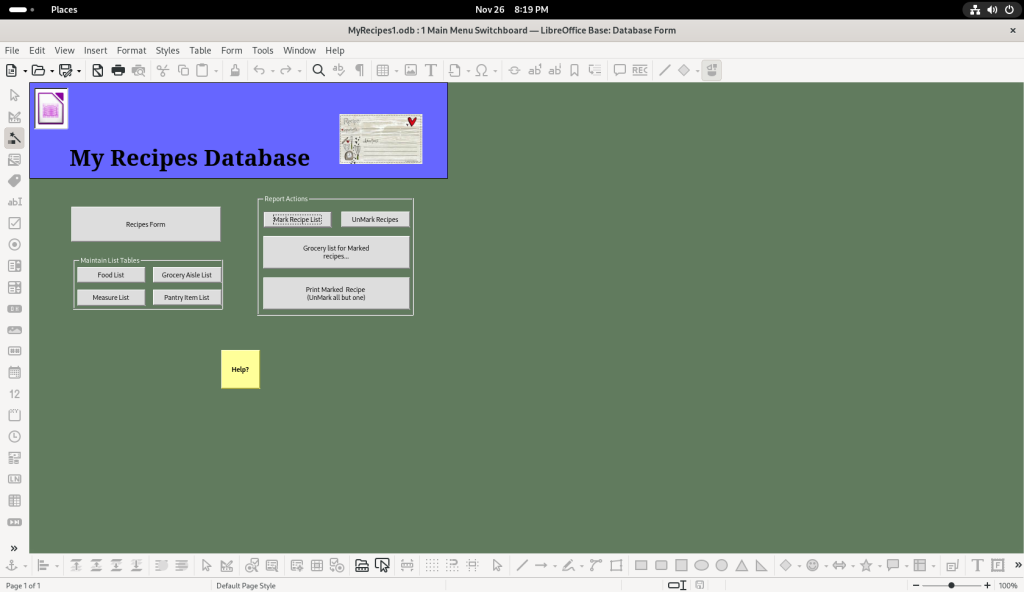
Main menu switchboard created by the author to navigate through their recipes and other functions they programmed
Given that the “switchboard” is based on macros, the Tools pull down menu was opened::
Tools menu opened
… and the “Options” option was clicked:
“Options” option clicked, opening an options window
The Security option was chosen:
Security option chosen
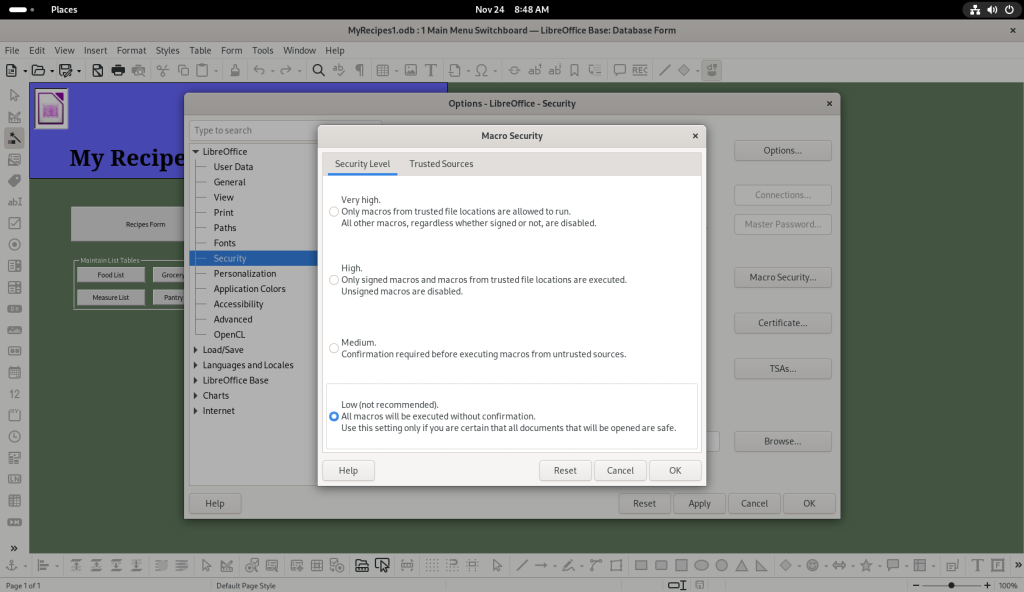
… and the “Macro Security” button was clicked. The security level was set to low, as per the author’s suggestion:
Macro security options changed
Back to the Switchboard:
Database main menu opened
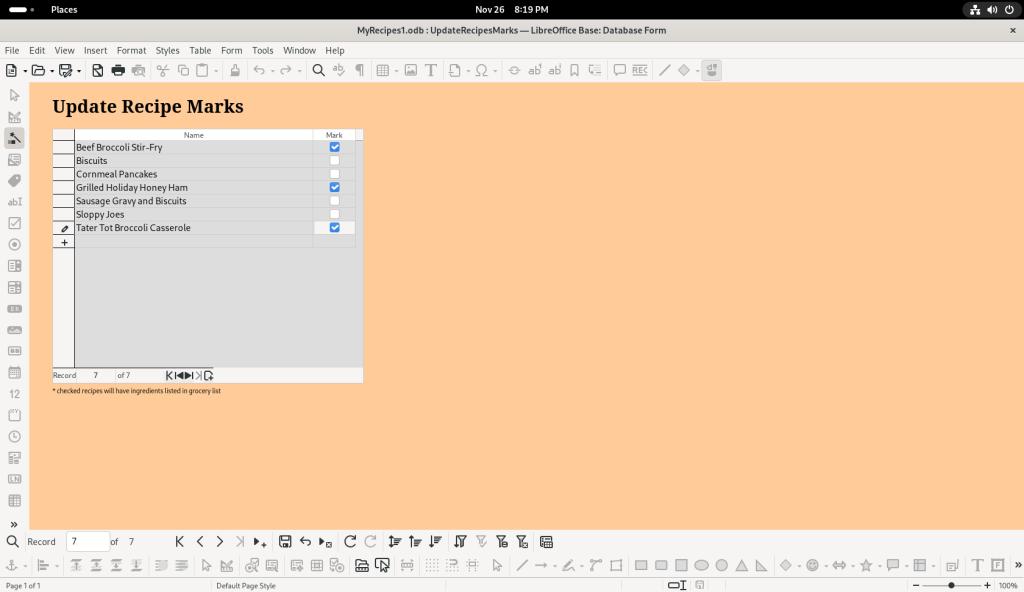
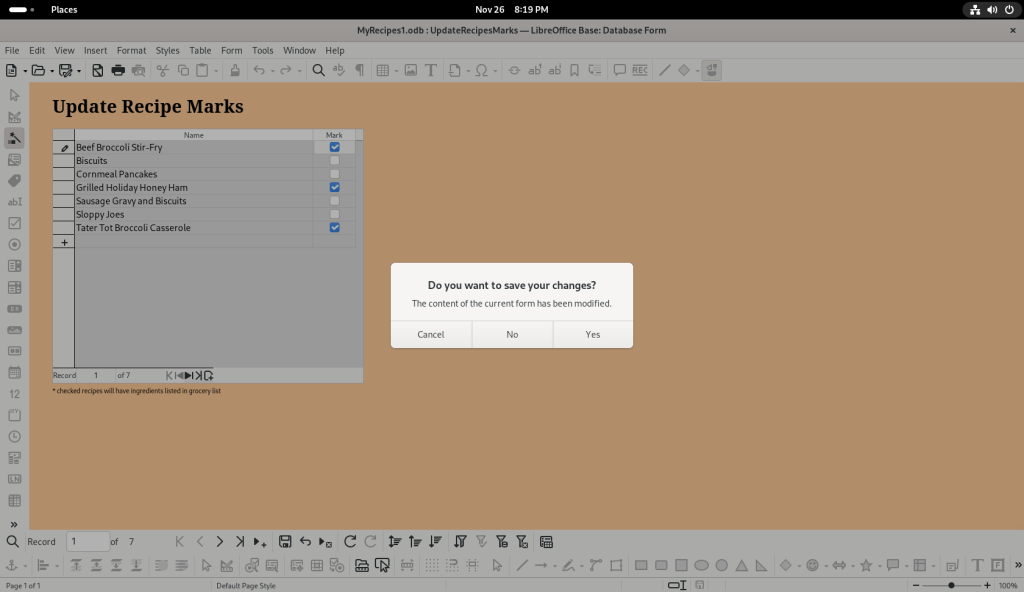
The “Mark Recipe List” button was clicked, and I decided to mark three of the recipes:
Recipes chosen
In trying to close the window, a window asked if I wanted to save my changes, to which I clicked “yes”.
Window closed and changes saved
The “Grocery List for Marked Recipes” button was clicked:
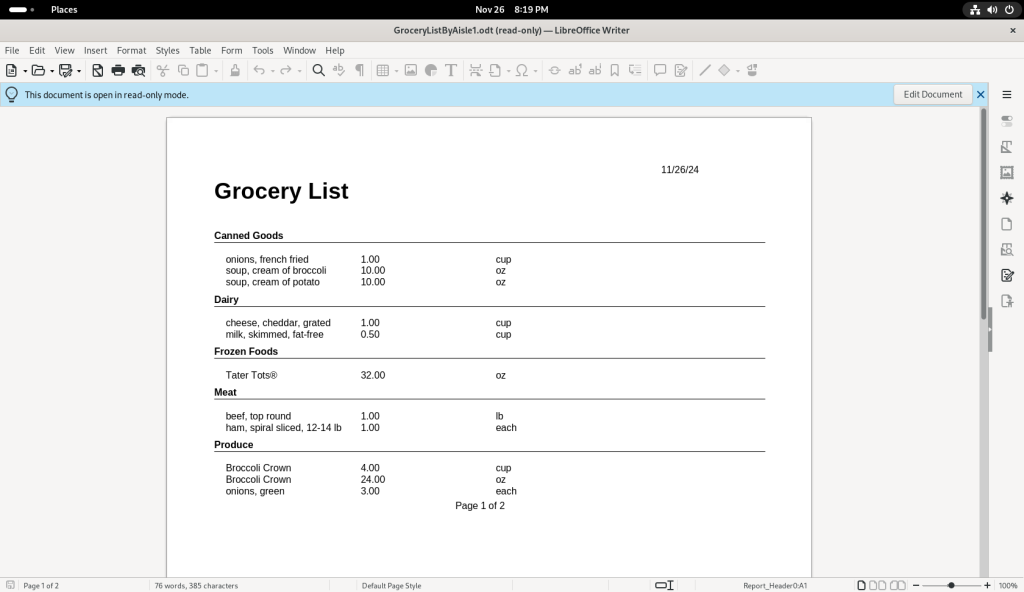
Grocery list option chosen from main menu
… producing a grocery list based on the recipes, which was automatically opened in LibreOffice Writer:
Note: Although it has been a while between posts and I had planned on another subject for what would have been this post, given the time lapse I decided to take advantage of a new version of Fedora that had been released to show how to easily upgrade the OS version, in this case, from version 39 to version 40. Note that many different versions of linux (Ubuntu, Mint, Debian, etc.) have similar functions and upgrade paths; since I began using the automatic upgrade tool in Fedora in about 2018, I have had good experiences.
Firstly, the “Activities” screen happened to open when I logged into the system, and I chose the software icon in the dock on the bottom (the white “shopping bag” with the red, black, and blue symbols):
Activities screen with dock on bottom
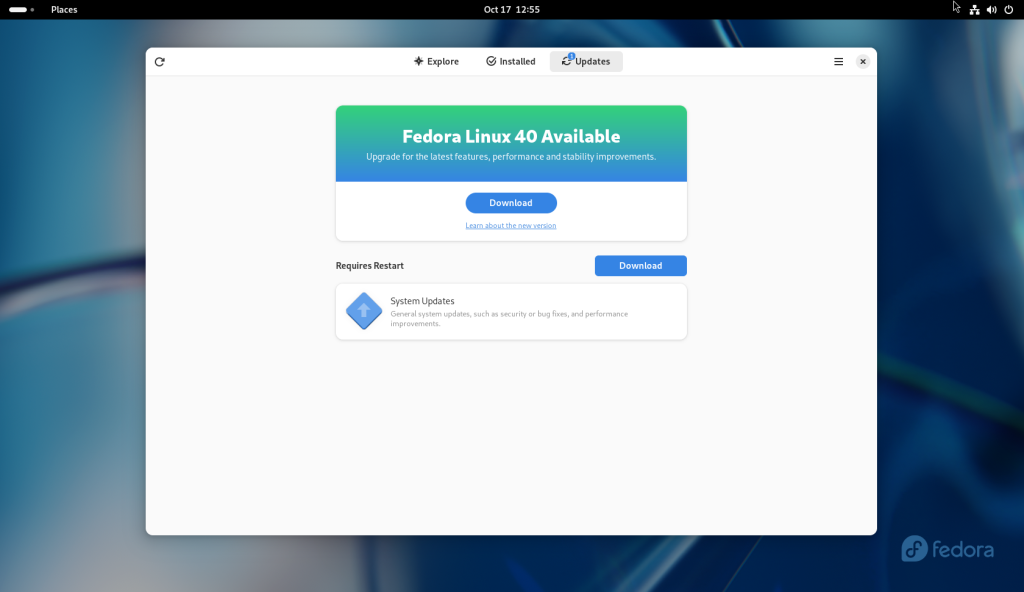
Which brought up the following screen, telling me that there were general updates, and that a new version of Fedora was available:
Software icon chosen
The system updates were first chosen and downloaded:
Updates downloaded
Once the updates were downloaded, the system was ready to be rebooted for installation:
Updates ready to be installed
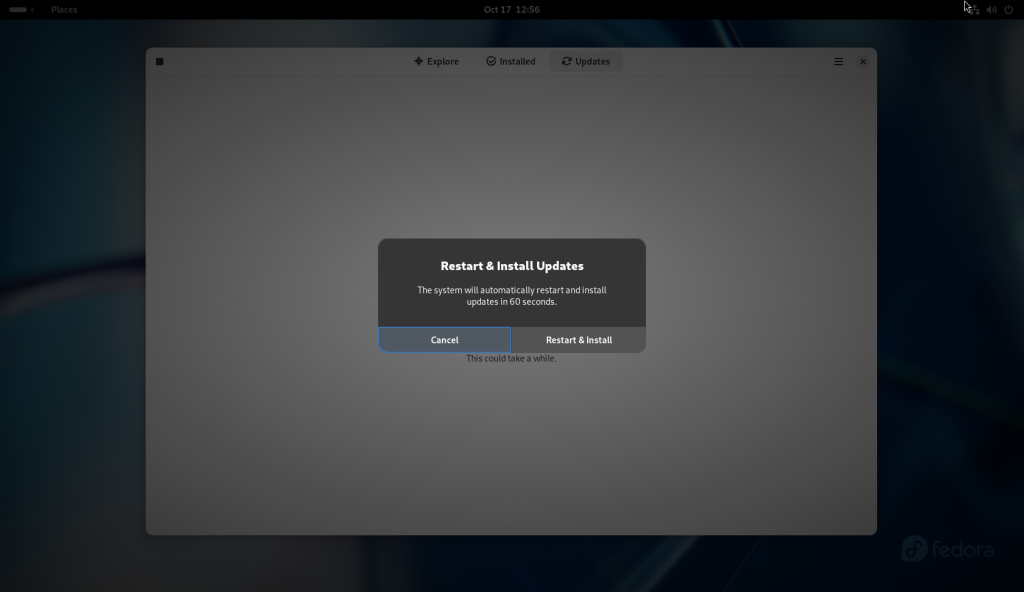
The “Restart & Install” button was chosen to confirm the reboot:
Restart and install updates dialog box opened
The system rebooted:
System rebooted
… and updates were installed:
Upddates installing
Once the updates were installed, the system rebooted:
System rebooted after installation of updates
… leading to the login screen:
System login screen
… where I entered my password:
Password challenge
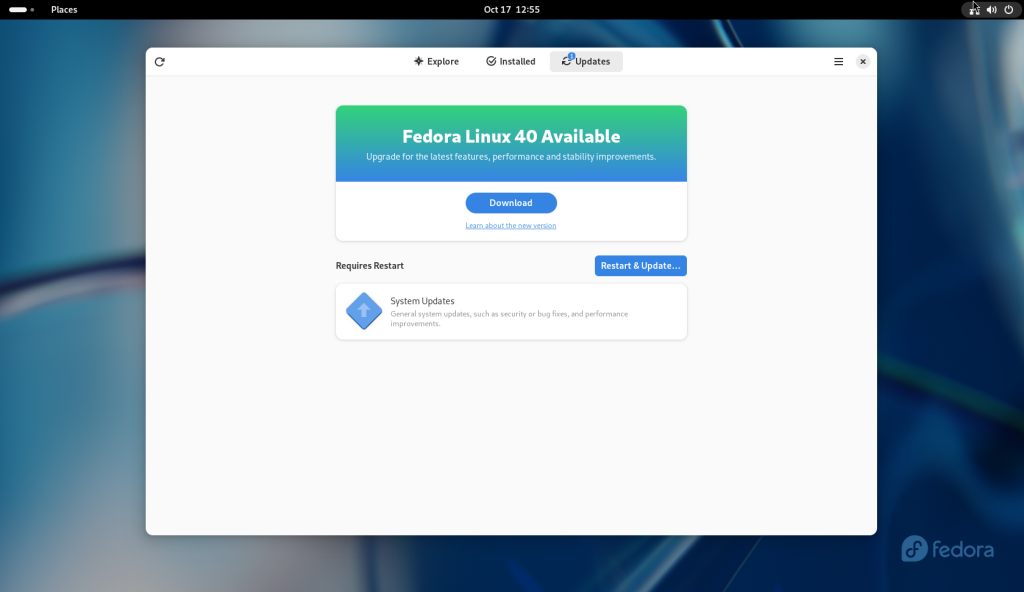
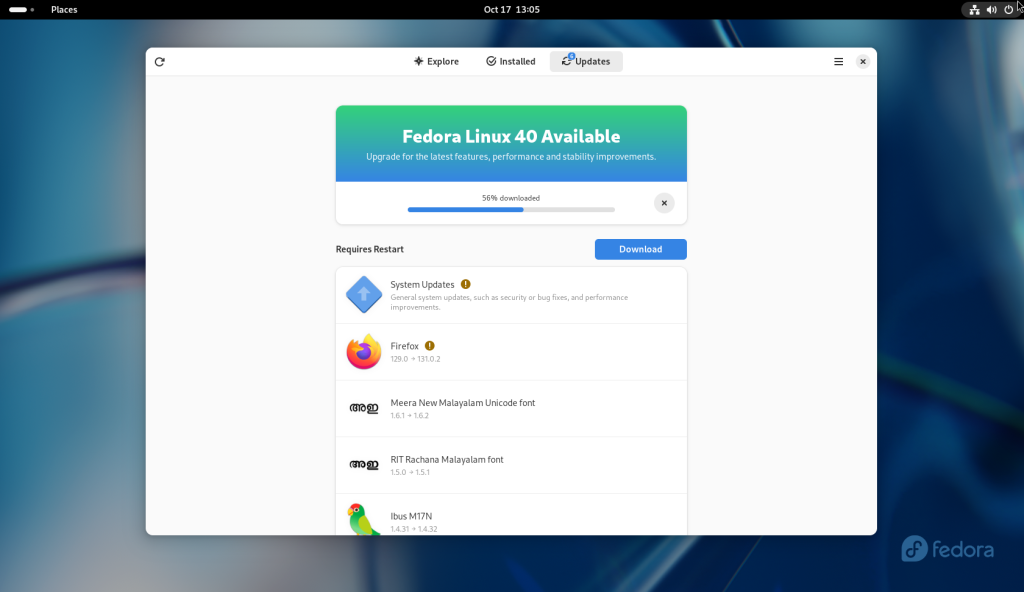
Once logged in, I clicked on the software icon again in the dock, and chose to download the upgrades for Fedora 40:
Software store opened again, and upgrade packages downloaded (2%)
Upgrade packages downloading (19%)
Upgrade packages downloading (32%)
Upgrade packages downloading (56%)
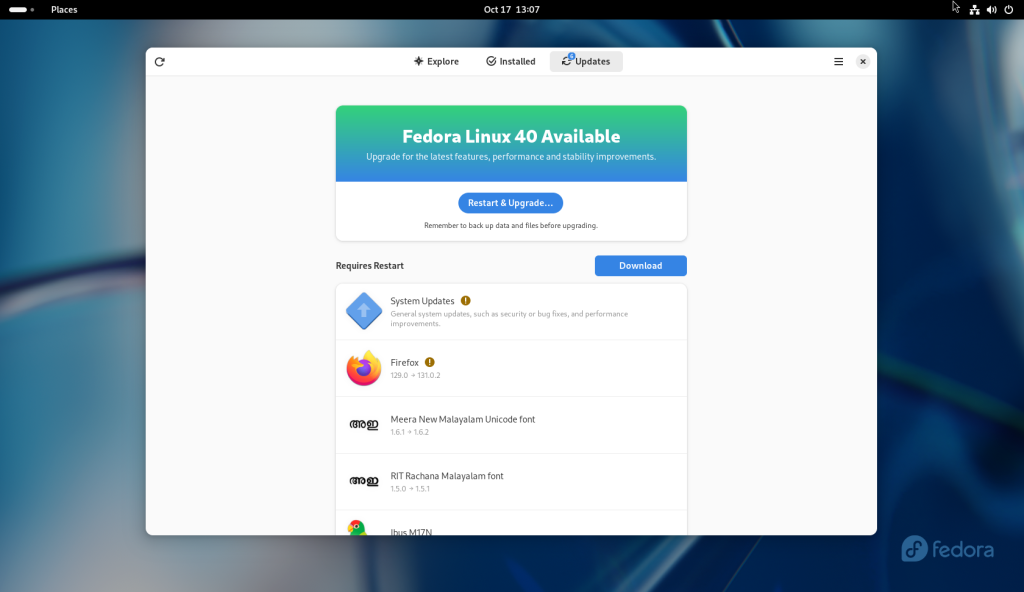
Once the upgrade packages were downloaded, the “Restart & Upgrade” button was pressed:
All packages downloaded, and Restart and Upgrade button pressed
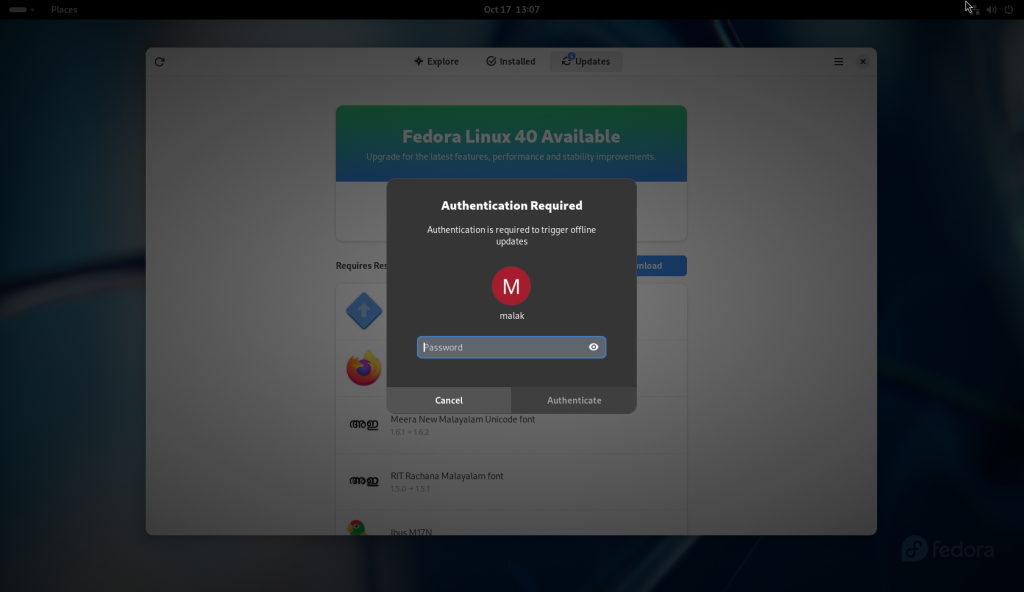
… which required authentication, so my password was entered:
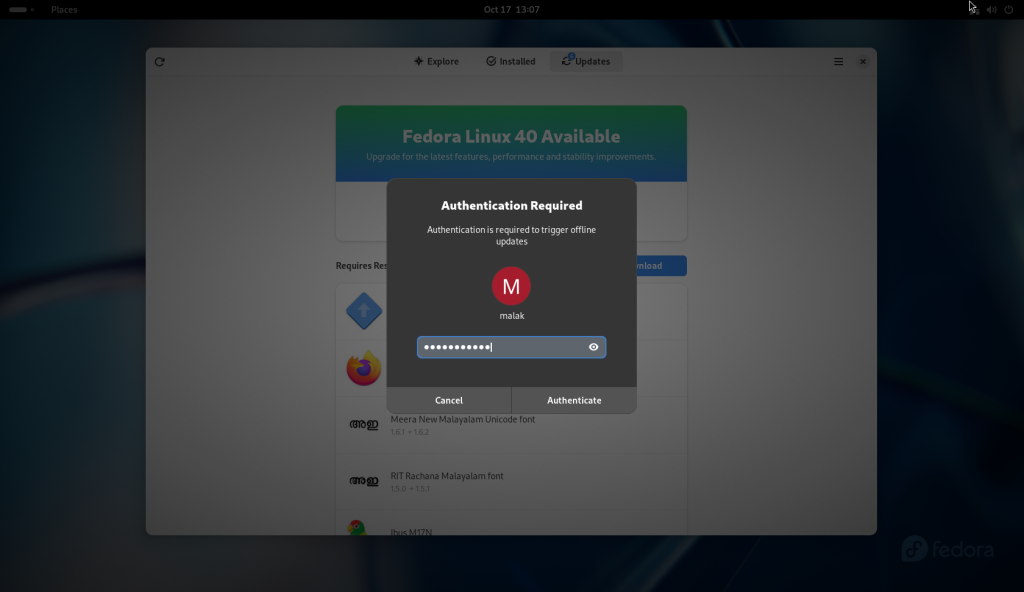
Authentication required for the major changes
Password entered
The system asked again if I wanted to restart and Install the upgrade:
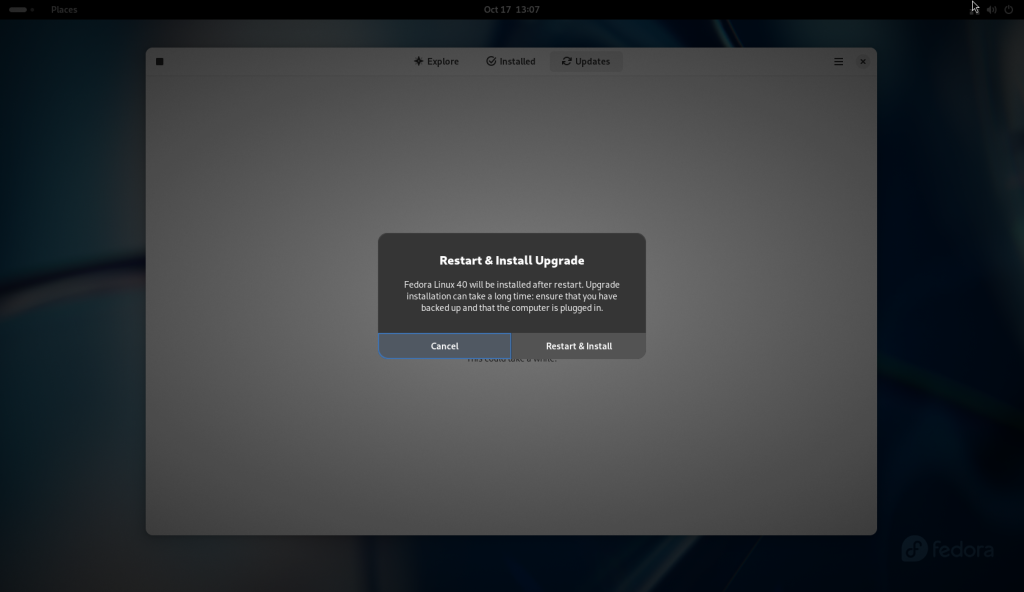
Confirmation requested to restart and upgrade the system
The “Restart & Install Upgrade” button was pressed:
System rebooted
System rebooted
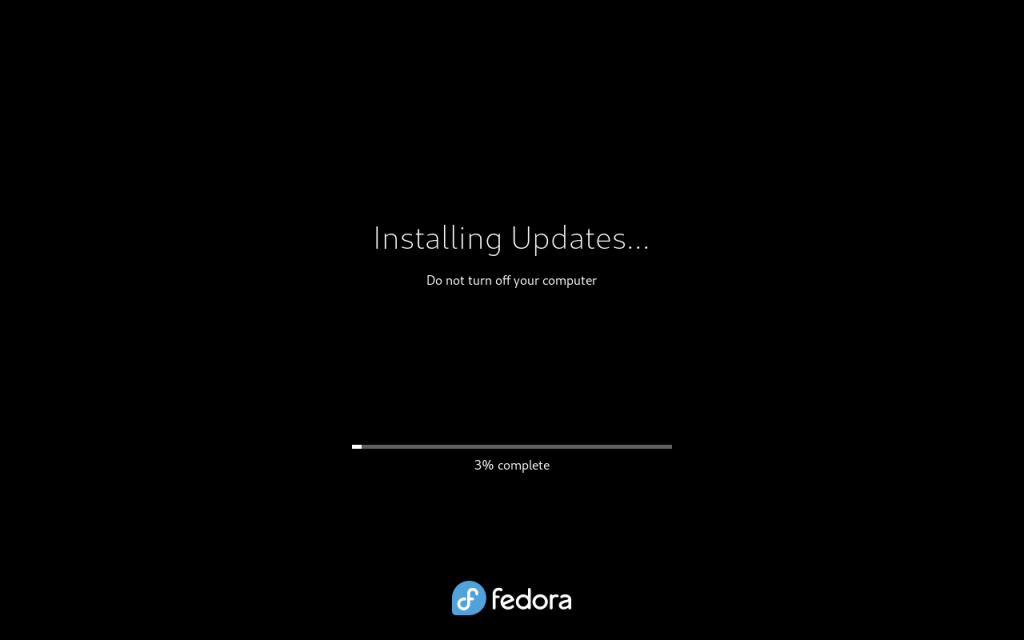
Updates installing (3%)
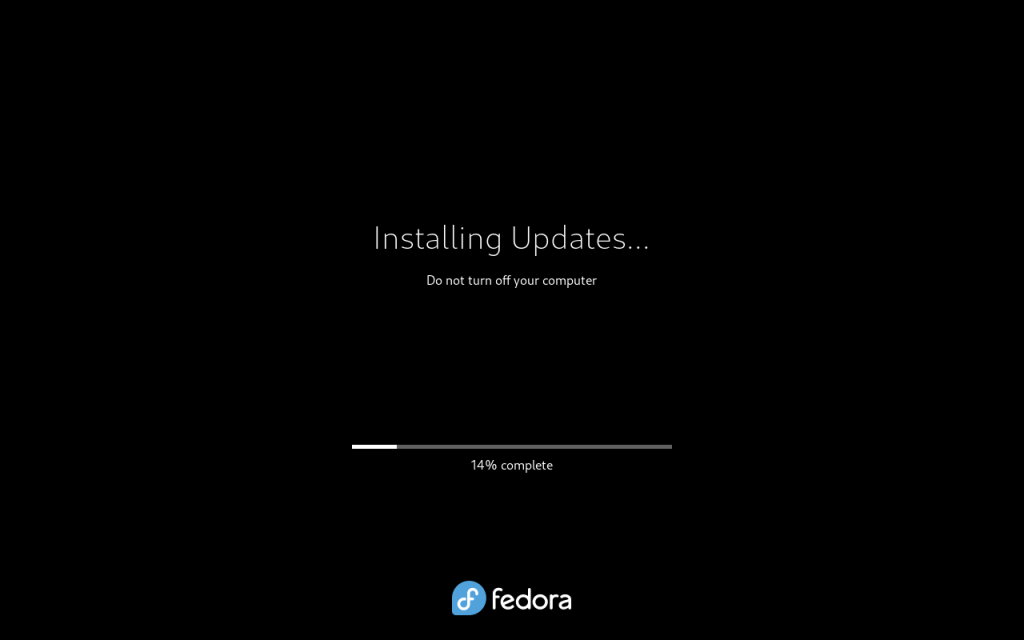
Updates installing (14%)
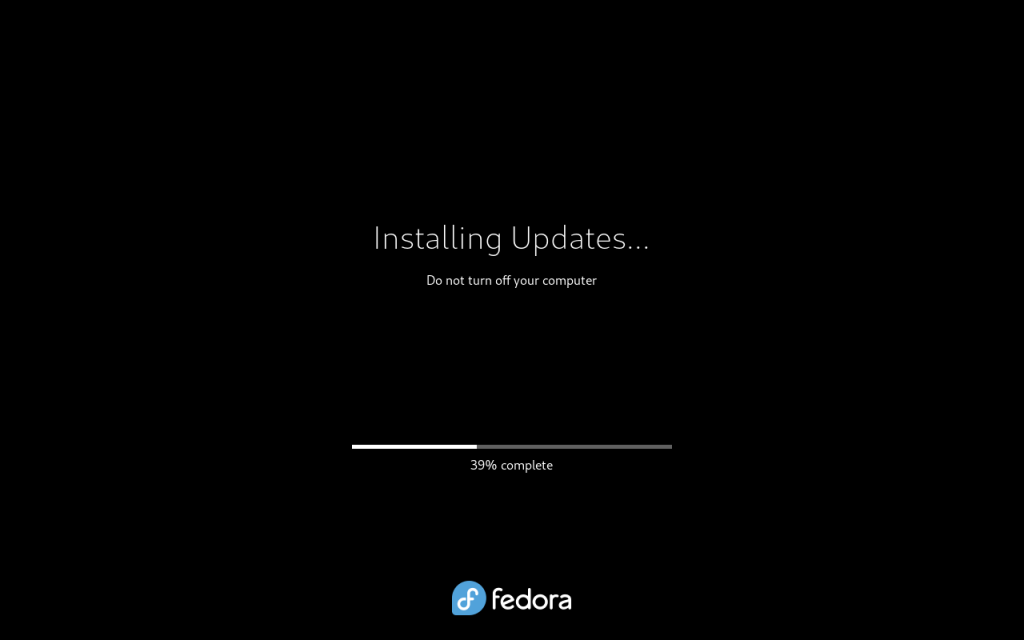
Updates installing (39%)
Updates installing (52%)
Updates installing (59%)
Updates installing (77%)
Updates installing (93%)
Updates installing (97%)
Once the upgrade was complete, the computer rebooted:
System rebooted after upgrades applied
The login screen came up again:
Login screen
And again I provided my password:
Password challenge
Password entered
Once logged in, new artwork for the new version came up, as well as a notification that the system had been upgraded to the new version (in this case, Fedora v.40):
New artwork for Fedora 40
Just to finish off some checks, the menu at the power button was opened, in order to open the settings screen, accessible from the little gear second from the left on top:
Menu for settings opened
The settings were opened:
Settings opened
I noticed that the name of my computer was curiously changed back to “Fedora” in the upgrade:
System renamed after curious change by upgrade
Then I chose the “System Details”, showing that the system had indeed been updated to version 40:
Confirmation that the system had been upgraded to Fedora 40
Next chapter: Using common pieces of desktop software
This past weekend, my brother decided to play around with the Google NotebookLM podcast generator, using my recent post about making yoghurt muffins as the podcast topic source material.
Here are the results: “Podcast 1“, the first one I listened to and chuckled at throughout (see below), and “Podcast 2“, which is longer than the first, and a slightly different approach (again, see below).
As a reference, according to Wikipedia (here’s my archive), NotebookLM is a tool by Google that has an “audio summary” feature has the “ability to condense complex documents into engaging podcasts”. As referenced in the article, some of the generated podcasts have indeed been making the rounds on at least the media local to me; the samples played on the radio had the “voices” of two artificial “hosts”, one male and one female, and appeared to greatly impress the real radio host. The real human host on the radio then proceeded to create their own samples with the tool using local news items as source material, resulting in stunningly … seemingly accurate (or at least faithful to the source material) content and banter between the two artificial “hosts”. The voices — and banter — of the artificial “hosts” that were created sounded so real that the “hosts” did not sound obviously artificial in almost any, let alone many, of the usual ways that usually betray the artificiality or synthetic nature of the voices. “They” seemed to bypass the Uncanny Valley (here’s my archive) as well, if only because they weren’t associated with artificially-created “speaking” faces or other cues that might suggest that “they” were artificial.
To wit: My brother came up with two podcasts: Podcast1, and Podcast2, based on the blog page about the yoghurt muffins: The first podcast was roughly what I would have expected, based on the samples I’d heard on the radio, in the form of “entertaining” banter from the artificial “hosts” about the overall post and subject, while the second podcast followed a play-by-play style review of the post and its pictures.
Especially while listening to the first, I was often incredulously guffawing at how “seriously” they seemed to be taking the subject, to the point of “their” calling me a perfectionist; despite, uhm, seriously having approached mounting the post with its pictures and processing the photos for presentation, as well as of course maintaining my recipe archive, and again of course being fairly serious on a hobby level about my cooking, for the overall cooking project I have always had a certain laid back, “enjoying the fun” pleasure to mounting the posts. Which, I must admit, intentionally include a lot of photos detailing usually every last step and even micro-step. I would estimate that the “hosts” got it better in the second podcast by calling me meticulous.
The end result of the two podcasts is so good that except for the knowledge that it’s totally AI generated, I would actually believe that the podcast was hosted by real people and put together by real people providing real feedback. As such, I have a few responses to some of the “comments” that the “hosts” made:
I am flattered in a giggly kind of way that the “hosts” underlined the dirty oven window, which I myself had somewhat sheepishly admitted was the case in the original post;
The “hosts” seem to enthusiastically say it’s like a scientific document with no room for error; I would challenge anyone to compare the blog post against the recipe and say that the two are identical. 🙂
For the record: I did not lick the spoon. 🙂
The “hosts” spoke of how much care I took by freezing them … well, I will go into the “easy” column and say both that baking a half batch or a double batch is roughly as easy as a standard batch, and, that I often try to make recipes that are good for the freezer!
And finally … the “hosts”, in a tongue-in-cheek fashion, pretty much suggested that I make a blog post on making the morning coffee, which I may just do sometimes in the futurewhich I actually have done. 🙂
The “hosts” asked what does “easy” mean in my claim that the muffins are easy to make, such as is it the number of ingredients, the technique, or the cleanup? “They” initially conclude “Let’s find out!” “They” then go on to point out the use of the paper liners, and the reuse of the measuring cup used to measure out the yoghurt to then measure out the oil without cleaning it in between, as examples of the “easy” part.
The “hosts” seem to insinuate at a couple of points that the amounts of sugar and oil used are “generous”, while of course continuing to state that the muffins’ crumb would no doubt be rather moist as a result; yet, when discussing the presence of the yoghurt, the “hosts” wondered whether the yoghurt muffins were just an alternative to the bran muffins I make for my mom, but ultimately seemed to decide that it was obviously a “health angle”. I perceived this as a lack of continuity in the “creation” of the podcast. And to be clear, having adopted this recipe was simply meant to be an alternative to the bran muffins I give to my mom, which is clearly stated at the beginning of the post; further, I am not trying to “match” the sweetness of bran muffins.
The “hosts” say that the kind of yoghurt I use is not identified, ie. firm yoghurt, stirred yoghurt, or greek yoghurt, etc.; “they” are correct that the tub does not say so, at least in the view in the picture. However, “they” do read into it by saying that this lack of information is part of the “easy” claim by letting people trying the recipe to use what they have on hand. Also, “they” did not pick up on the strawberry on the tub as an example of how the “relatively plain” was intentionally a loose interpretation.
The “hosts” say that the kind of oil I used was not identified; again, the photo of the jug plainly says “vegetable oil”, which should tell all bakers that it’s generic vegetable-based cooking oil.
Is this a fun tool? Sure. My brother and I have bandied about ideas — purely in the hypothetical — about using the tool to create large numbers of podcasts that could then be syndicated to AM radio stations for the overnight slot during which a lot of content is often recycled or of what we consider to be of dubious interest.
In this post, acquiring a computer on which to install Linux, as well as downloading and writing a Linux distribution on a USB stick, will be shown. Fedora Desktop Edition will be used as an example, although at this point, setting up the installation USB stick can be done with any other distribution — which is most of the common ones — that allows for such an installation.
(Note for future reference, graphical installation with other distributions will be similar, but each may have some nuances and differences between them.)
Hardware — the computer on which Linux is to be installed
First, I recommend that as a newcomer, whichever linux you decide to install, that you decide to do the installation on a separate computer, such as an old computer, on its own. By doing this, you will not reduce space on the hard drive / SSD on which your current OS is installed, especially in taking account the space for data you may to transfer over to the Linux system, nor will you have to deal with the intricacies and occasional perils of dual booting or data loss on your current computer setup, nor will you have deal with the myriad and occasionally confusing issues that may surround virtualisation. Finally, by having a separate computer to “play” with, you will be able to start over again in the event that something goes wrong, or if you decide that you’d like to try a different Linux distribution.
The current (2024) webserver for www.malak.ca
The above photo is taken from a page from a recent (February 2024) presentation the author made about their web server, which hosts https://www.malak.ca (the website hosting this blog), using an old computer with a BIOS creation date of 2008.
Acquiring a computer:
“Old” computers are not unusually difficult to acquire; you may already possess one in storage.
Use an old computer you may be wishing to replace, or already be in the process of replacing, or even a several years-disused computer of which you may not yet have disposed;
Buy, or barter for, a used computer from family or friends;
Buy a used computer from a local computer repair person, who may have a storefront and may sell refurbished computers;
Speak with your employer; depending on their policies, they may be willing to sell you older equipment of which they would like to divest themself(ves);
Check reputable online markets;
Buy a new dedicated computer (only recommended once you become convinced of the cost/benefit regime).
Check the “minimum requirements” page of the distribution you choose; my current bare minimum specs are a Core 2 Duo 64bit processor, 4GB memory, 40GB hard drive (the current, as of late 2023, Fedora Workstation recommendation), and a spare USB 2.0 port (such as after other common USB peripherals you may be using, like a mouse and keyboard), in order to use the installation USB stick (which will be shown lower down in this post). (As desired or required, don’t forget to get a used screen.)
For the purposes of introduction to, and the exploration of, Linux, the old mechanical hard drive with such an old computer is likely adequate; however, SSD cards and extra memory will dramatically increase performance of older equipment. Further, as of posting, SSD cards in the 250GB range are typically very affordable to either add on later, or purchase for immediate use including installation of the system, while memory cards appropriate to the motherboard are usually readily available and inexpensively as per the above list regarding sourcing an old computer.
Downloading and creating a USB installation stick:
A USB stick is required for this step; Fedora’s installation image as of version 39 in late 2023 is approximately 2GB; hence a 4GB USB stick would be recommended going forward.
I am recommending the use of Fedora Media Writer to create the installation media, which can be run on Windows or Mac (as well as Linux, of course!) Should you choose another distribution, you can use a downloaded image from another distribution’s download page (see Desktop Linux: Unveiled Chapter 2: Common Linux Distributions for a few suggestions of other distributions; see below regarding choosing other Fedora desktops, or creating installation media of another distribution).
(Note that the following screenshots may have been created out of order, however are presented in the order required for the narrative.)
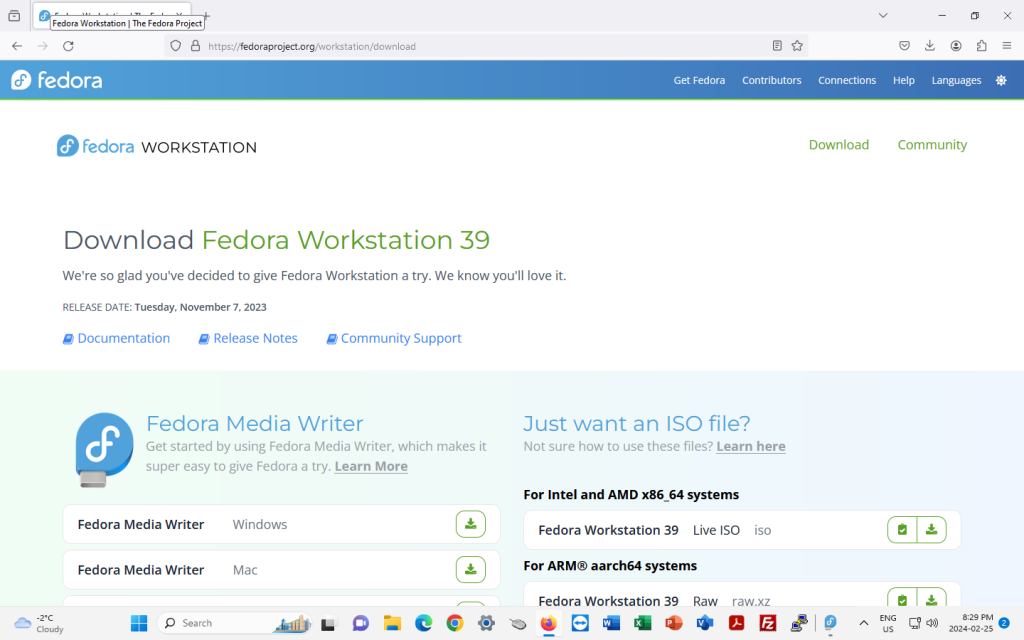
To get the Fedora Media Writer, visit https://getfedora.org (I start off using screenshots from Windows):
Click on the circle indicating the latest release (in the shot above, 39), which will bring you to the following screen.
On this screen, click on “Download Now”; don’t worry, you aren’t committing yet.
On the following page, click on the green download button for Fedora Media Writer, either for Windows or for Mac:
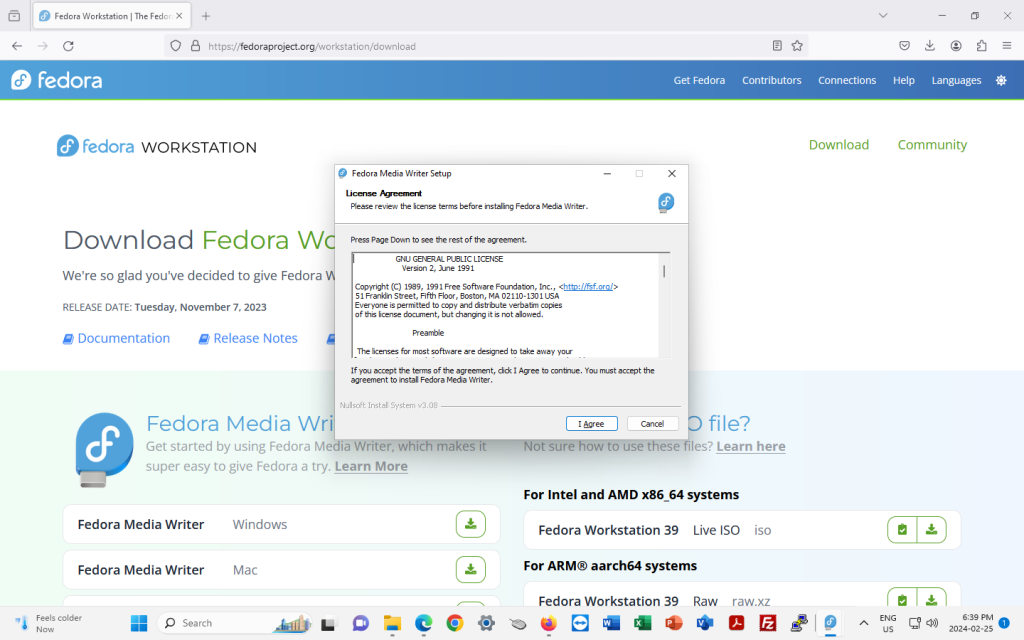
A licence agreement window will pop up. This is for the Gnu Public Licence version 2, the licence under which the Fedora Media Writer is licensed. Click on “I agree”.
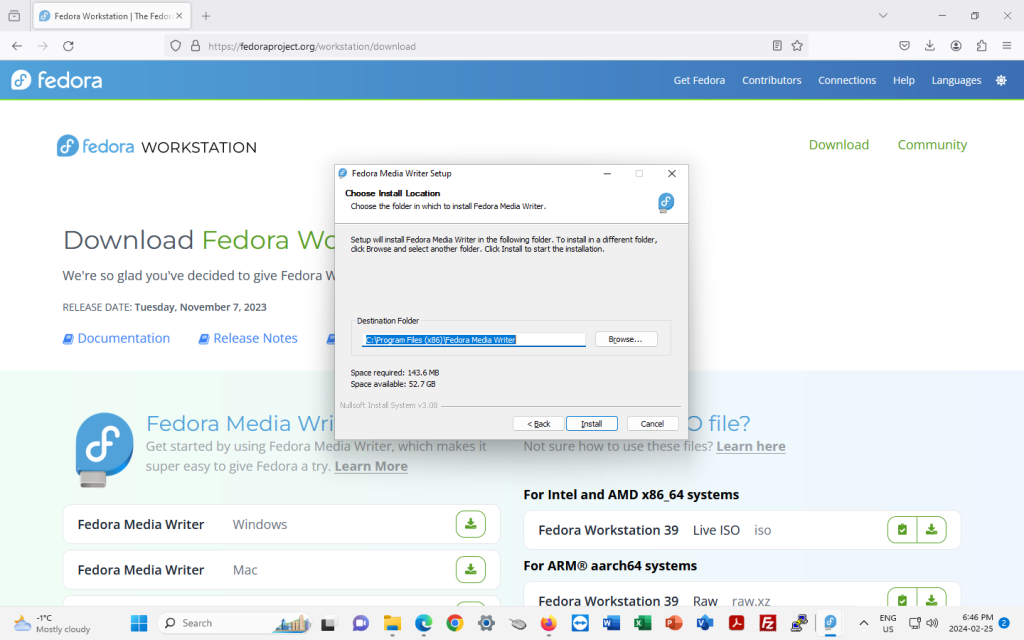
The next screen will ask where to install Fedora Media Writer on your computer, and it will suggest a location to install it on your hard drive. Click “Install”:
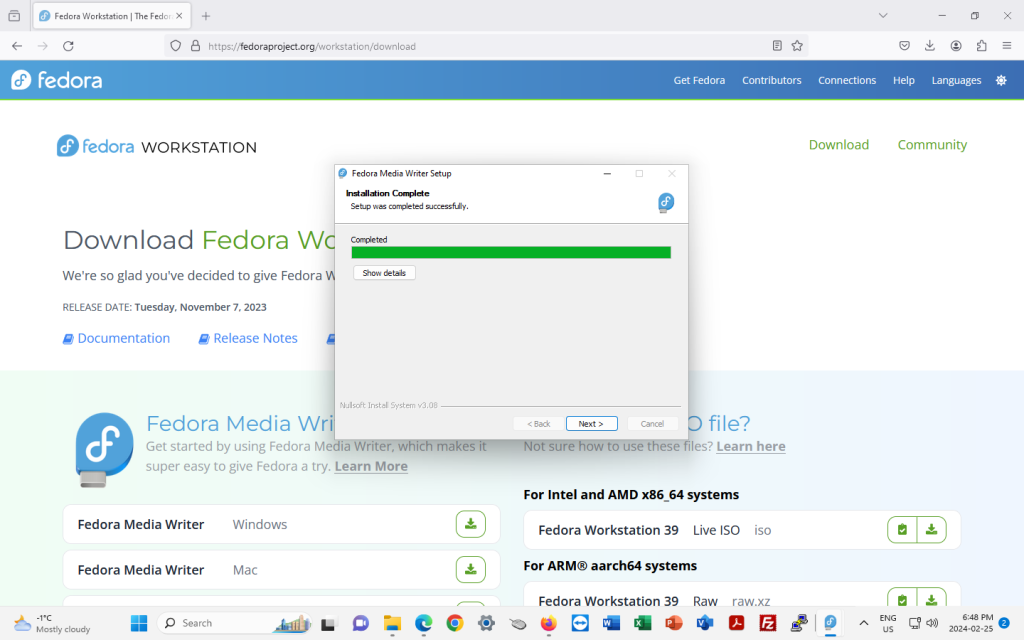
Once Fedora Media Writer is installed, click on “Next”:
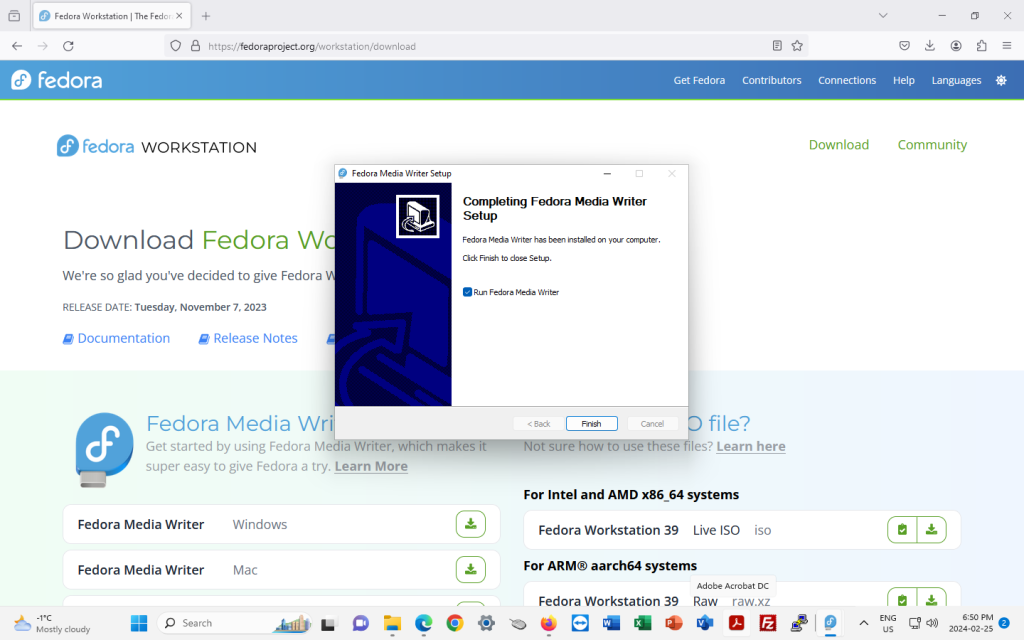
… and click on “Finish”:
Launch Fedora Media Writer:
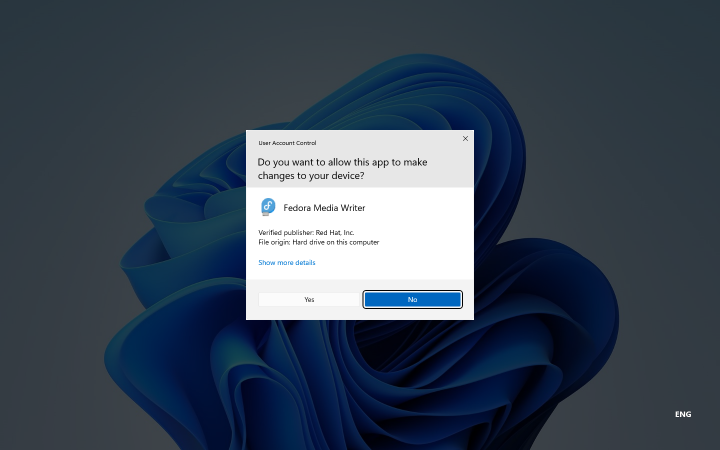
You may be asked to allow the app to make changes to your device. Click “Yes”.
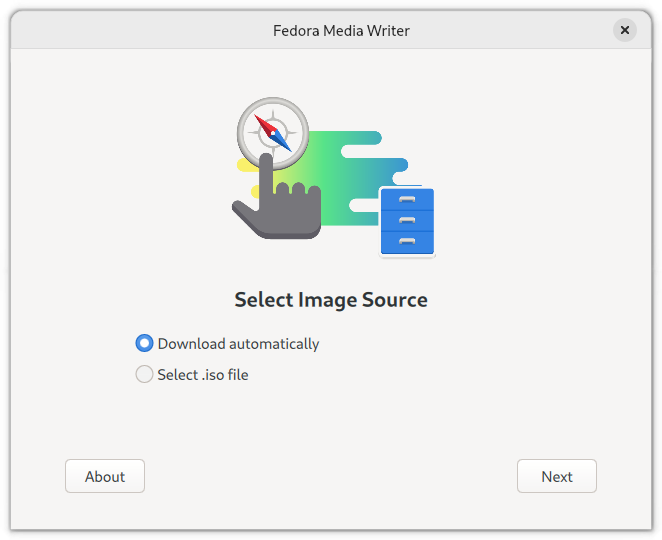
At this point, you can either choose to have the Fedora Media Writer download Fedora automatically, or, you can download a distribution of your choice, and ask Fedora Media Writer to use that distribution instead (the “Select .iso file” option):
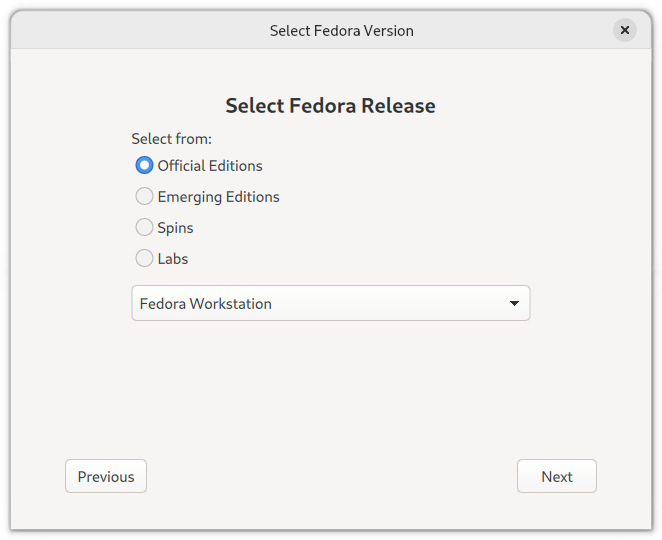
Going with the “Download automatically” option above, which by default chooses a Fedora distribution, on the next page (below), choose “Official Editions”:
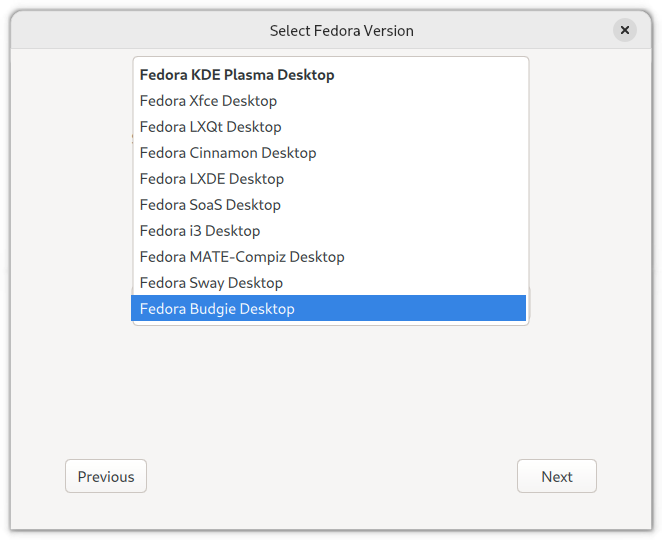
Should you wish to try another desktop instead of the standard Gnome Desktop in Fedora Workstation Edition, you can choose the “Spins” option above, which will list the following drop-down menu:
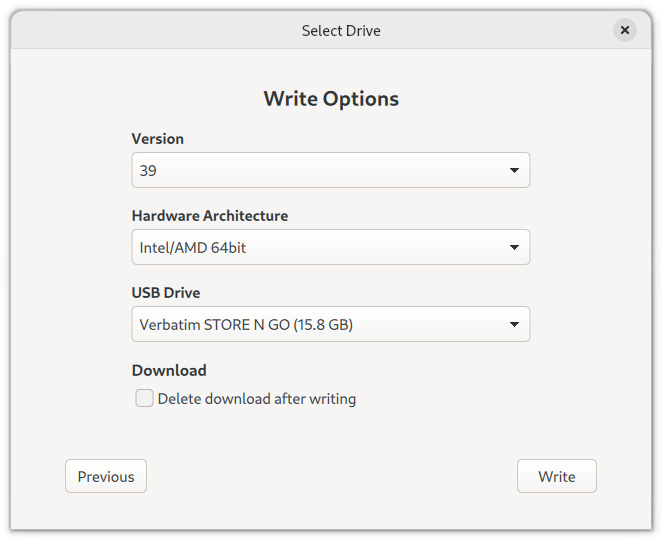
Under the choice taken, the next screen is the “Write Options” for the USB stick, which at this point should be inserted in a USB port. Choose the latest version of Fedora (in this case, 39), the hardware architecture, and the USB stick to which you wish to write the installation media:
Click “Write” in the above screen, and Fedora Media Writer will begin writing to the USB stick:
The screen will automatically change to indicate that the written data is being checked:
Once finished, you can click on “Finish”.
Should you wish to try out Fedora without installing it on your computer first, you can follow the instructions on the screen to restart the computer and try a live, temporary version of Fedora. This will not affect your hard drive in the least, unless you choose to install … which I am not recommending, since I am recommending that you install on a completely separate computer (see beginning section).
Next Chapter
Chapter 4 will show the installation of Fedora Workstation.
In this post, a few of the more well known linux distributions and desktop environments will be showcased.
Note: Clicking on the various desktops will show larger versions.
Fedora
Fedora Linux is a general-purpose linux distribution focusing on free software (ie. not containing any proprietary software) and on being on the leading edge of free software development. It can be used by all desktop users. While having many tools that developers find useful, it is can also be used as a general purpose computer desktop.
Fedora using the Gnome desktop, with the activities screen opened up
Fedora provides a variety of desktop environments; the Gnome desktop environment is the default desktop environment, although other desktop environments are available in Fedora’s various spins, which cater to varying visual aesthetics, technical requirements, and useability.
Fedora Linux can be downloaded from https://getfedora.org(note: do not add “www”, it will lead to an error page)
Debian
Debian GNU/Linux is a general purpose Linux distribution aiming to be available on a large variety of computer architectures, built on free software, and is known for its stability. The large number of software packages available under Debian and its stability are often highlighted as some of its strengths. Debian is used for a wide variety of purposes including desktops and servers, and is equally capable in both functions. Debian is often used as a base for other Linux Distributions.
Ubuntu is a popular Linux distribution based on Debian. It releases “Long Term Support versions every two years which typically are supported for at least five years, as well as intermediary releases usually every nine months. Ubuntu is often found not to be too difficult to learn to use.
Linux Mint is based on Ubuntu, and is known for its desktop named “Cinnamon”, which was originally based on the Gnome Desktop, but was branched off into its own desktop environment which focuses on a more traditional computer desktop appearance and functionality.
openSUSE is the community version of SUSE Linux, a business and server oriented version of Linux. openSUSE is known for its use of the KDE desktop, but also uses the Gnome desktop.
openSUSE Tumbleweed is a version which updates continuously and does not require reinstallation after a certain period of time; however, it may prove more challenging to newer users, who might find openSUSE Leap more stable.
Desktop Linux: Unveiled is a series of posts that show how to start using Linux.
In this post, Linux will be briefly explained and briefly compared to other common desktop computer operating systems.
First, what is an operating system?
An operating system (OS) is the software that makes a computer run, like Microsoft Windows, or MacOS. It is typically able to provide a way for users to operate the computer, and translate the instructions so the computer can run them. It also coordinates all the computer’s resources such as its CPU (central processing unit), memory, hard drive, and other components of the computer, as well as coordinate the user’s programs and data.
What is Linux?
Most people understand “Linux” to be a complete operating system like Windows or MacOS. However, strictly speaking, “Linux” is in fact just a part of the operating system, the central part called the kernel. Common usage has had “Linux” to informally refer to the whole operating system.
“Distributions”, (usually) complete and integrated collections of software built around the Linux kernel, can be legally built and distributed by anyone with the abilities and inclination because of the way the Linux kernel and the other software usually used with it are licensed, although most people choose to use an established distribution.
Distributions vs. Operating Systems
Linux distributions usually contain full linux-based operating systems, as well as extra software often not traditionally included in operating systems, such as office suites, media players, graphic design software, educational software, games, various apps, as well as other software such as server software. Although not all of the software is installed at the same time, they are typically all easily available in central locations called “repositories”, similar to app stores on MacOS and Windows; much is available free of charge, too!
Free Software vs. Proprietary Software
A lot of software available under Linux — and a growing amount under Windows and MacOS as well — is called Free Software, or sometimes Open Source Software. As a contrast, a substantial amount of Windows and MacOS software is called Proprietary Software.
Many people hear the expression “Free Software” and assume that it means that it is free of monetary charge. Some may even question its quality on the basis of such a lack of price.
Although free software is often (though not always) given away free of charge, and most common free software is of very high quality, the expression “Free Software” in fact refers to “freedom”, specifically various freedoms granted to the users of the software. These freedoms include the freedom to run the software for whatever purpose you wish, the freedom to study how the program works as well as make any changes that you wish, the freedom to share the software with others, and the freedom to share software you’ve modified with others.
Some of these freedoms require that the source code, or “recipes” that people can read and understand, be available to anyone and everyone.
The various licences used to allow this often tend to foster cooperation between various parties, often allowing groups who might sometimes be competitors to also cooperate with each other, creating common software that each group can then package together to present according to their own vision. Within this cooperation, software sometimes is developed quickly, and often many programming bugs are found and corrected quickly.
Some common free software licences are the GPL and the LGPL, which specifically give the recipient of the software the above freedoms, and require the sharing of the source code to the software, and any changes you may have made to it, when distributing the software. Other common free software licences are the BSD licence, the MIT licence, and the Apache licence, which have very few requirements but which permit users to use, modify, and distribute the software, while retaining copyright and some disclaimers notices.
In contrast, proprietary software is usually controlled by very restrictive licenses that keep the source code hidden, doesn’t allow users to distribute the software to whomever they please, doesn’t allow users to modify it or fix bugs even if they are able to were they to have access to the source code, and may even dictate how the software may or may not be used.
Next Chapter
Chapter 2 will list some popular Linux distributions that people use on their computers.
I have five active computers, all which were ready to update to Fedora 39 in November, 2023: Three were running on Fedora 37, and two were running Fedora 38. Normally, I try to keep to the same version of Fedora on my fleet of computers — although I will format with the current version of Fedora mid-stream when I format a new or a new to me computer, or a new hard drive or ssd, and try to use a version (that of the majority of computers) until end-of-life, usually roughly 12 to 13 months. I settled on odd numbered versions several years ago, on Fedora 15, by happenstance, and a desire not to be reformatting different computers every six months depending on when their end of life fell.
As such, I proceeded to upgrade my computers.
Since the recommended method of update for Fedora is by the command line DNF upgrade command (here’s my archive), or to use the graphical method in the “Software” “App Store”, I proceeded to upgrade my machines on the command line.
(Note: Some of the screenshots and photos used in this post were created during the various upgrades, while some were re-created ex post facto for the sake of mounting this narrative.)
Note that the upgrade plugin was already present on the server, hence my having omitted the step of installing the plugin. Important note, minor in my head although critical to my experience, is that my webserver uses the Workstation Edition, not the Server edition.
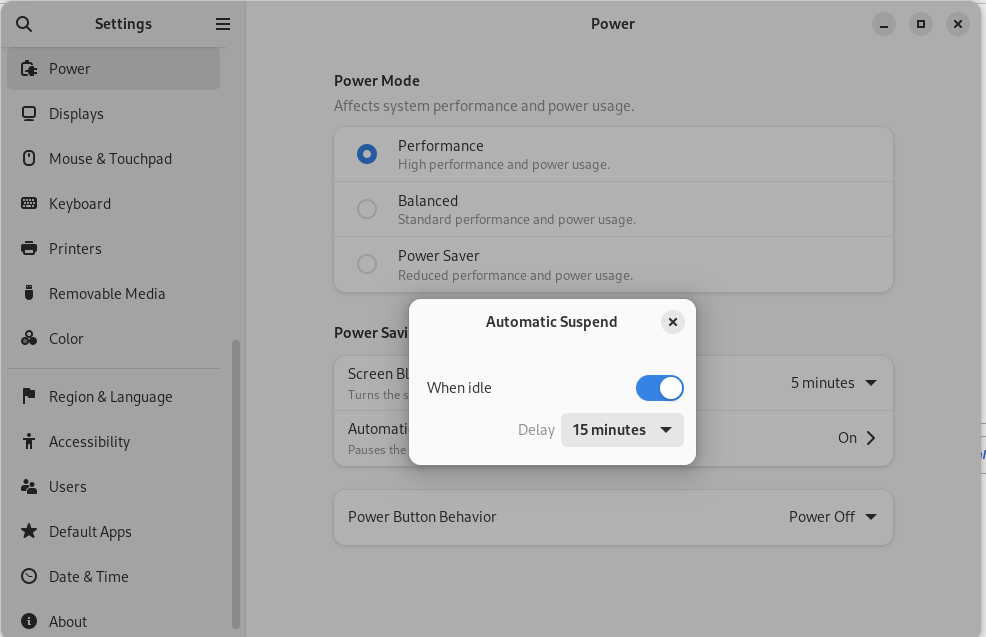
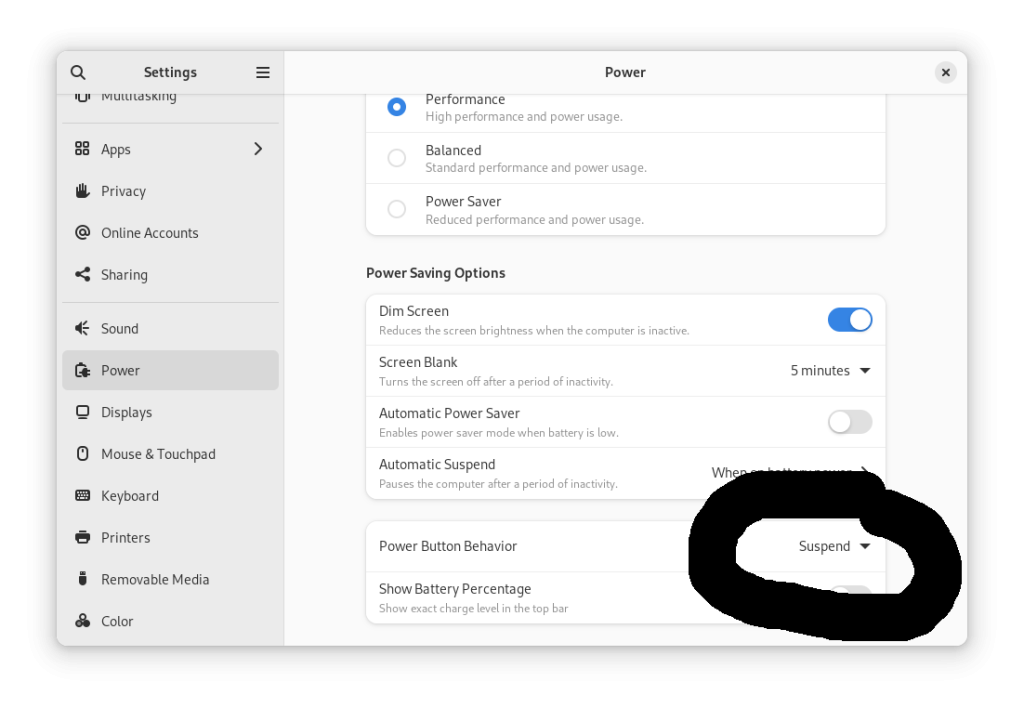
All went smoothly, with one small quirk: After the upgrade and later that evening while at a restaurant, I wanted to check my website for something, and it was down. I thought little of it beyond the frustration in the moment. When I got home, I let my brother know in the hopes he might help … but in the process, I saw that the machine’s light in the power button was amber, and I had an idea that there was a software power management issue. I pressed the button, and the machine popped to life; I then went into the power management part of the settings in the gnome settings, and found the “automatic suspend” setting had been turned on to “when idle”.
VPN Server: Fedora 38, Server Edition, Legacy BIOS (HP Compaq dc7700 Small Form Factor)
My next upgrade was also fairly simple and straightforward. It was on a machine I found in a building slated for demolition in about 2016, and is a P4-3.4GHz single core machine, which I had been using as a world community grid node for years, but which had been inactive for months, after there having been little work for it for months when WCG moved from IBM to the University of Toronto. (I also suspect that the UofT may have decided to shift most of its tasks to GPUs, which I don’t think the machine possesses, and in any case I did not properly research let alone confirm this, beyond the apparent lack of work units being sent to it.)
A problem I’d been having for years with this machine was that it would not reboot without manual intervention, apparently due to a time error; this suggested a dead bios battery. I tolerated this for years, but this summer I finally installed a new battery in the machine, resolving the issue.
I reformatted the machine with Fedora 38 Server Edition given its age and lack of memory, and I renamed the machine, having some misgivings about its former name. I offered its use to my brother, who uses it as a VPN server for the household here, particularly to simplify assisting our mother in her computer use. I generally leave the machine alone: VPNs are a nebulous thing I don’t understand very much at all; I understand SSH filesystem tunnelling, and the parts between that and VPNs are too nebulous for me to understand.
But to wit: Up to this point I was neglecting the machine, letting my brother deal with it, but as a result the machine would often go unupdated for weeks at a time. In mentioning that I’d embarked upon the process of upgrading my computers all to Fedora 39, I mentioned that I liked to keep my fleet of computers all aligned on the same version of Fedora; I mentioned that at that time, due to new installs, I had two out of five computers on Fedora 38, while the rest were still on Fedora 37. With the comment that I wanted to keep my fleet on the same version, my brother encouraged me to maintain responsibilities for updates and yes indeed to upgrade this machine in particular, to keep it in line with the rest of my computers.
Which, of course, I did. (There were indeed some firmware updates to be installed.)
Here’s what the process looks like on my XPS13 (Screenshots and photos taken after the fact, on a subsequent series of firmware updates):
Firmware updates a few weeks after upgradeFirmware updates a few weeks after upgradeFirmware updates a few weeks after upgrade
At this point, I was invigorated by being able to perform firmware updates on my XPS 13 laptop (which admittedly had not been the first time I had done so under linux, but no matter.)
However, a couple of weeks later, I noticed that an extension wasn’t working: My XP13 has a touchscreen display, and Gnome has an onscreen keyboard that pops up contextually when text is to be entered, occupying a major amount of screen space; I had been using the “disable-touch-osk” extension by sulincix, which stopped working with the upgrade to Fedora 39.
On screen keyboard disabling extension not working
This leads to a gripe I have for the Gnome developers: Stop breaking extensions with each new version of Gnome, or provide *some* kind of stable API or environment or whatever is needed so that the extension developers don’t decide to abandon their extensions because Gnome keeps on shifting so much that they have to work excessively hard every six months just to maintain their extension.
This led to the next two computers I have, which are a 2015 Acer laptop, and a 2014 Dell Inspiron desktop.
Acer Laptop: Fedora 37, Workstation Edition, UEFI — but using Legacy BIOS
I have been having problems using UEFI in my Acer laptop since I received it new in 2015; the Fedora live media would boot up, and I could install Fedora under UEFI; however, it would never boot up afterwards. My only solution seemed to be to use legacy bios. Nonetheless, hope springs eternal, this was the time to try again to install under UEFI.
I should note at this point, as mentioned above, that my home server (2008) and my VPN server (2007) are both rather old computers and pre-date UEFI and use legacy BIOS, while my XPS 13, Acer laptop, and Dell Inspiron desktop, are all UEFI machines. I make these distinctions because of conversations I had in which on the one hand, it was suggested that I perform a baremetal reformat of the Acer laptop in order to sidestep a problem I had been experiencing when I’d allowed the battery to drain completely, forcing a reset to defaults in the BIOS and hence to UEFI boot, making my setup with legacy-BIOS unbootable; on the other hand, I concluded “It’s 2023; it’s absurd not to be using UEFI on UEFI machines.” (Of course, the use of older, legacy machines predating UEFI are a different issue altogether, and for them, said point is moot.)
In addition to this comment about using UEFI, and the potential to have any UEFI firmware upgrades as discussed above, I decided that my Acer laptop needed to receive a baremetal format, given the accumulation of a lot of software on the system that I didn’t use (many though hardly all installed because of a presentation I gave in 2021); I decided that instead of package hunting and manually uninstalling them all — including dependencies that decide not to uninstall — it seemed more efficient and effective to do a clean install.
Fast forward to this round of upgrades, I upgraded the installation using a downloaded Fedora 39 image, and I went through various upgrades and setups, such as Gnome extensions, and some software installations. Suddenly I remembered that I had not changed the boot sequence from legacy bios to UEFI, so … I started over.
Several installation attempts later, including trying Fedora 36 (with an intention of upgrading through to version 39) based on some advice playing around with the various BIOS settings trying to get just “the right” settings, none worked, and I finally resigned to reinstalling yet again under, and continuing to use, legacy BIOS. Sigh.
Setting the Boot sequence to Legacy BIOS
Before setting up in legacy mode, I had a flash of inspiration: Since I was nonetheless able to boot the live media under UEFI (which I knew wouldn’t otherwise be used afterwards), I attempted a firmware update as per the above. To my mild disappointment, there weren’t any firmware updates for my Acer Laptop:
I continued with the installation under Legacy BIOS mode, and set up the desktop with the various Gnome Extensions, installing software not in the base installation, and customizing settings and the like.
I once again faced a few pet peeves I have about how Fedora is set up (incidentally through Anaconda, but by itself not Anaconda issues, best I can tell):
Fedora uses sudo by default, which I don’t like: I go by the notion of “Don’t be afraid of root; respect it, but don’t be afraid of it” — when you have to do root-y stuff, log into root, do what you have to do as root, and then sign out of root. (Yes, I am aware of the advantages of sudo, even beyond its convenience and short term elevations of privileges, such as logging of *who* elevated their privileges to do *what*; I just wasn’t taught that way, and on a single user system, I don’t see much value to it; hey maybe that’s just me.) As such, with each new install I perform, I have to, ironically using sudo under my default user account, assign a password to the root account, and then, remove my default account from the wheel group.
… by removing my user account from the wheel group (highlighted):
The next thing that irked me was that in Fedora Workstation Edition, it seems that Anaconda no longer has an option (read, without the qualifier “it seems”) to set the hostname during the installation. While I understand that it is a trivial enough thing to set as per the following, under the default régime of the default primary user having sudo privileges … it seems to me that this is the kind of thing that should still be in the system installation part. (As in, I wonder how many new users have “fedora” as their machine name for a significant amount of time if not forever, being unaware that it is (only) a default placeholder name, unaware that it can be changed, and unaware of how to change it.)
Fortunately, this is easily set in the Settings / About menu, *if* you don’t remove your default user from the wheel group, or at least haven’t yet, and therefore still have sudo privileges:
Note that in the above screenshot, the option appears shaded out because since I had already removed the primary user from the wheel group, effectively disabling sudo, my (default user) account did not possess the requisite permissions to edit the hostname.
Changing the hostname on the command line is also not particularly difficult, using the command “hostnamectl set-hostname new-name”
… or, editing the /etc/hostname file, by entering the command “nano /etc/hostname” as the at the command line and as the root user:
Then, once in the /etc/hostname file, enter the host name you want (in the case of my Acer laptop, “reliant”, as in the USS Reliant from Star Trek: The Wrath of Khan movie.)
And on this install, I noticed that the extension Vertical Overview by Ralthuis, which among other things, allowed for the dock on the Activities page to remain vertical and on the left edge of the screen, instead of on the bottom of the screen, was broken, something I hadn’t noticed when upgrading my XPS13. Note: Check lower down in the section for my desktop.
Dock moved to the bottom of the activities screen due to a broken extension (note screenshot recreated after the fact)
On this point, I installed a number of Gnome extensions that I like, unfortunately not the one mentioned above, as well as adding apps to the dock, and other optimizations I commonly perform.
After these items, I installed Gnome Evolution, modified the installation’s setup such as pinning apps to the dock, and checked the power management issue listed above. During the install process, I was able to specify that third party repositories could be enabled; after install, I installed the free and non-free repositories from rpmfusion, as well as Rémi’s RPM repository. I transferred my data from the backup I had created earlier onto my laptop. (See next section on my Desktop).
Finally, I had to activate the flathub repository (here’s my archive) in order to be able to install software that I use that is distributed as flatpaks, such as Signal (a secure texting app):
… and then Signal was installed from the Software App:
Minor note: I don’t recall having to enable the flatpak.org repositories before, although I may be wrong.
This leads to my final computer to upgrade, my desktop:
In the summer of 2023, I upgraded the mechanical drive to an SSD, and I had installed Fedora 38 the SSD; the Dell Inspiron had difficulty recognizing Fedora 38 media, so I took an old pre-UEFI computer, inserted the SSD, and installed Fedora on the SSD. I don’t recall if I knew to change to legacy BIOS once I transferred the SSD to the Dell, or after an error or two, I realized the error, and made the change in the setup. The installation worked, although I was slightly irked.
Come time to upgrade to Fedora 39, I performed the command line DNF upgrade covered earlier, dealing with some of the consequences like the power management and idling issue above. Additionnaly, I noticed something else that irked me regarding the power button (changing it from “Suspend” to “Power Off”:
“Power Button Behavior” setting changed from “Suspend” to “Power Off”. Call me old school …
However, in the intervening time I had experienced the UEFI crisis above, so I first performed a backup of my data to my backup folders on my web server, mildly surprised by how much I was behind in my manual backups.
Unfortunately from this point on, my desktop proved to be the most challenging to upgrade properly.
Having downloaded a copy of the install media for Fedora 39 and burned it onto a usb stick, as well as still having the Fedora 38 Server Edition DVD (which I had forgotten was the F38 Server Edition, instead erroneously assuming that I had gone to the trouble of burning the F39 Workstation Edition onto the DVD), and I tried to install Fedora 39 from both media. I tried several settings in the setup menu, to no avail: The motherboard categorically refused to recognize either, simply displaying an error message vaguely communicating a sense that it didn’t like the media. In looking through the internet for pages on the subject, including the Dell website, I was mildly piqued that solutions commonly referenced burning the usb stick using particular software under Windows (to which strictly speaking I have access, but not on the computer in question), and often just assuming that there would be a Windows partition on the computer. Putting aside knee-jerk reactions, I assumed that this would not address the issue since the solutions appeared to assume a conflict with Windows which could not exist on my machine, or that the Fedora media-writing tools were inherently unable to operate correctly.
I gave up for the moment, changed the boot settings back to Legacy BIOS, and used the untouched Legacy BIOS install for roughly a week while dealing with other upgrades and life in general.
After roughly up to a week, I remembered something I’d read a week or two earlier that said that the UEFI shim for Fedora versions 37 and 38 (and I presume, given my experience, Fedora 39 as well), was not working for some motherboards “due to a difficult certification process for this component“, (here’s my archive) and that a workaround was to install Fedora 36, whose shim was known to work, then proceed through the command line upgrades to Fedora 39.
Fedora 36 was downloaded and burned on a usb stick, and the settings in the boot menu were changed back to UEFI. Fedora 36 was installed — successfully! …
… and the updates were performed, after which the command for the version upgrade was performed, to bring it to Fedora 38. However, the system would not reboot on its own; a quick fsck command corrected some “dirty code”, which it corrected, and I changed some boot settings about booting and automatic on at certain dates. Once this was done, the upgrade to Fedora 38 continued:
DNF upgrade command working; yes, my screen is dusty!
I again performed a dnf upgrade to Fedora 39, and had to repeat the fsck command in order for the system to properly reboot.
To correct this rebooting issue, an empty file named “fsck” was created in my home directory.
Backups were restored, and work similar to what I’d performed on my Acer laptop were performed regarding sudo, root, renaming of the box, evolution, extensions, pinning apps to the dock, and the like were performed.
After yet another week or so, I noticed that my backups had not fully been transferred, and began transferring the balance. In the process, my computer indicated that it did not have enough space on the hard drive; I suspected that during the previous install that I had not correctly removed the previous install, so I reformatted yet again.
So I repeated the installation and upgrade process, this time ensuring that all space on the drive was reclaimed, and repeated the above processes, both specific to the computer as well as other things generally required as part of the upgrade.
During the initial setup, I discovered an extension that brings back the vertical view: V-Shell (vertical workspaces) by GdH, and it seems to do what I want, although on the desktop there is a setting that brings up the (vertical) dock, workspaces, and app search space over the workspace; comparison with another setup allowed me to find the setting I wanted.
And, to repeat myself: Gnome, do you hear me? Stop breaking extensions!
Now — so far — the computer seems to be working, but as this whole process over a month has shown, I should give it at least a week to find out if there are any other issues.
Final Thoughts
I don’t read the upcoming changes for new versions, nor do I research in advance problems that people have been having. I discover the problems, changes, and challenges along the way, and as such for me Fedora reveals itself as per my usage and discoveries — no doubt leaving a lot hidden to me — not only over its roughly 13 month lifespan, but also over the first few weeks of using it, and, interestingly, over the installation process itself, especially when it’s over several machines of different eras and manufacturers and technologies.
As this round of upgrades in particular has shown, as well as years of using Fedora Linux, using Fedora Linux is an exercise in bleeding edge.
Now, barring unforeseen changes, additions, and the like, I’m looking forward to roughly a year of Fedora 39 goodness!


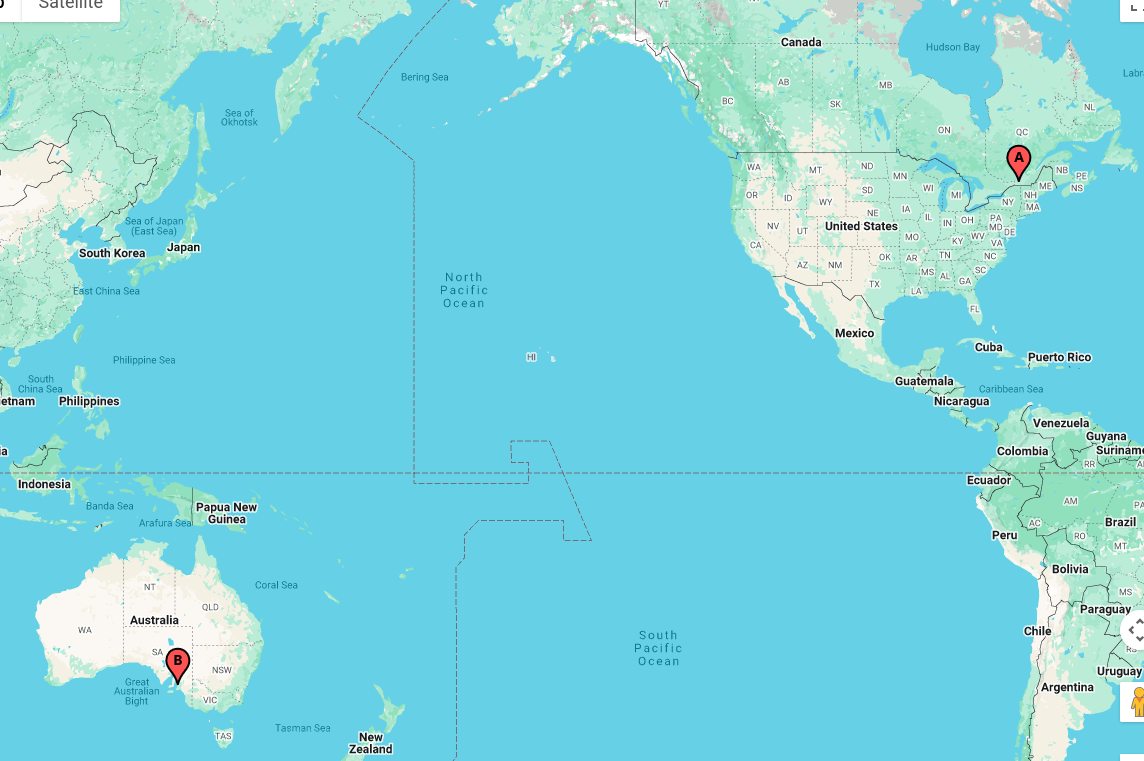
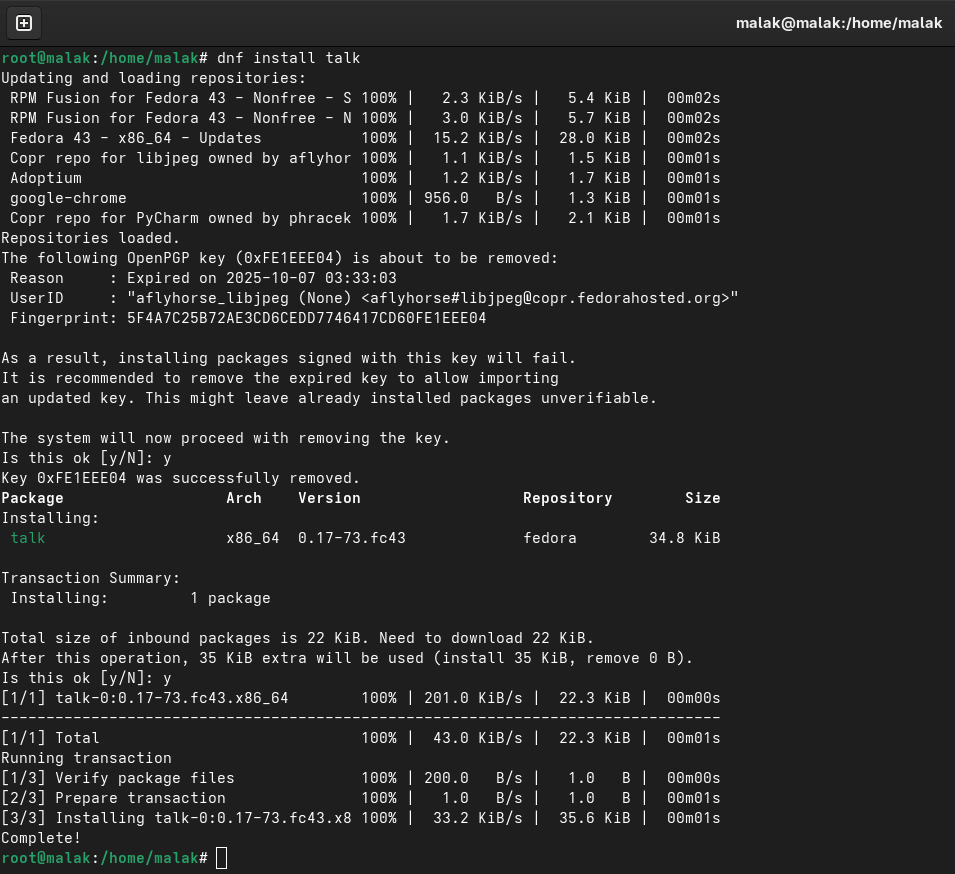
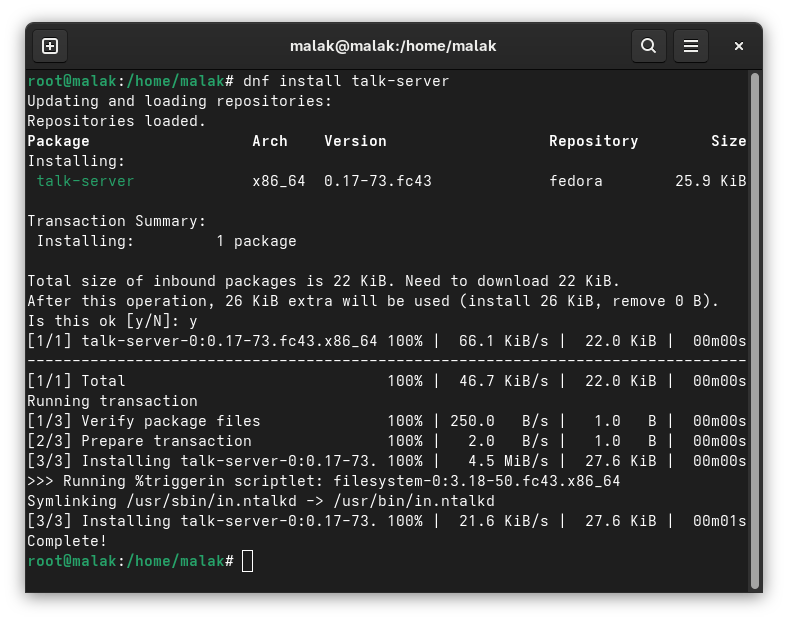
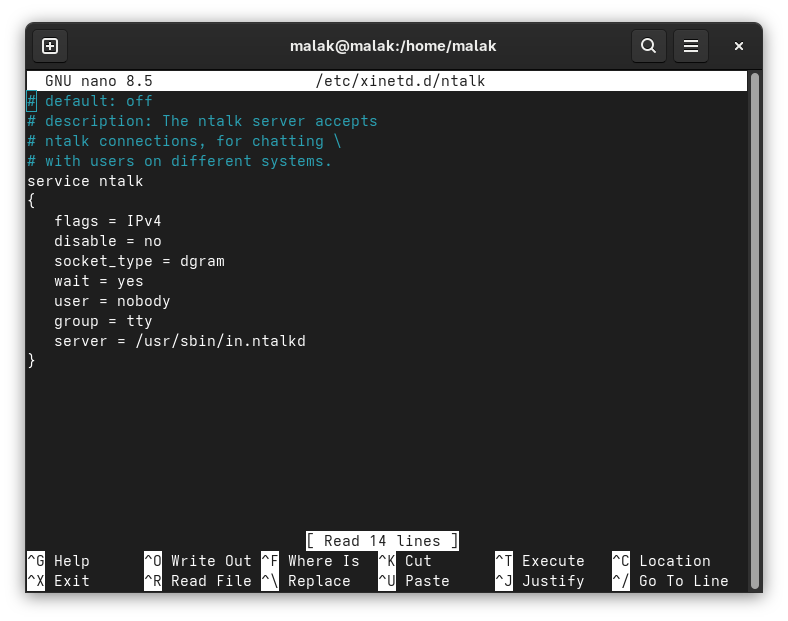
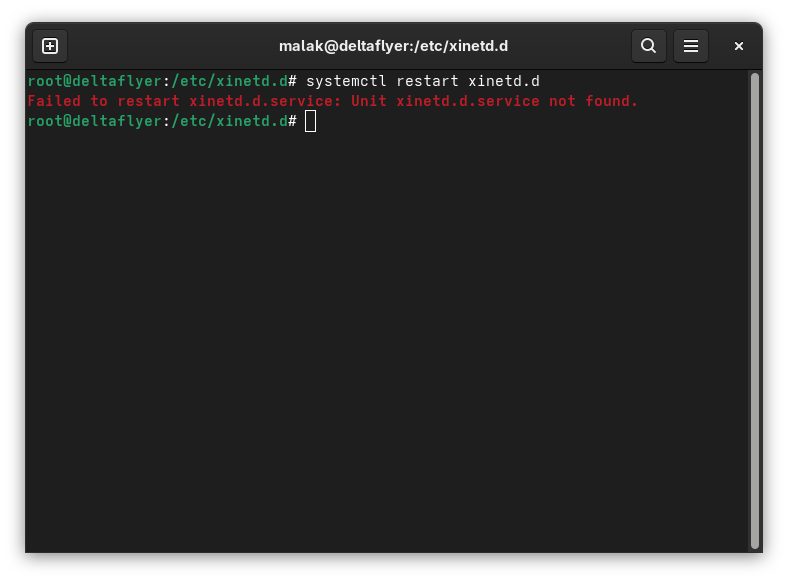
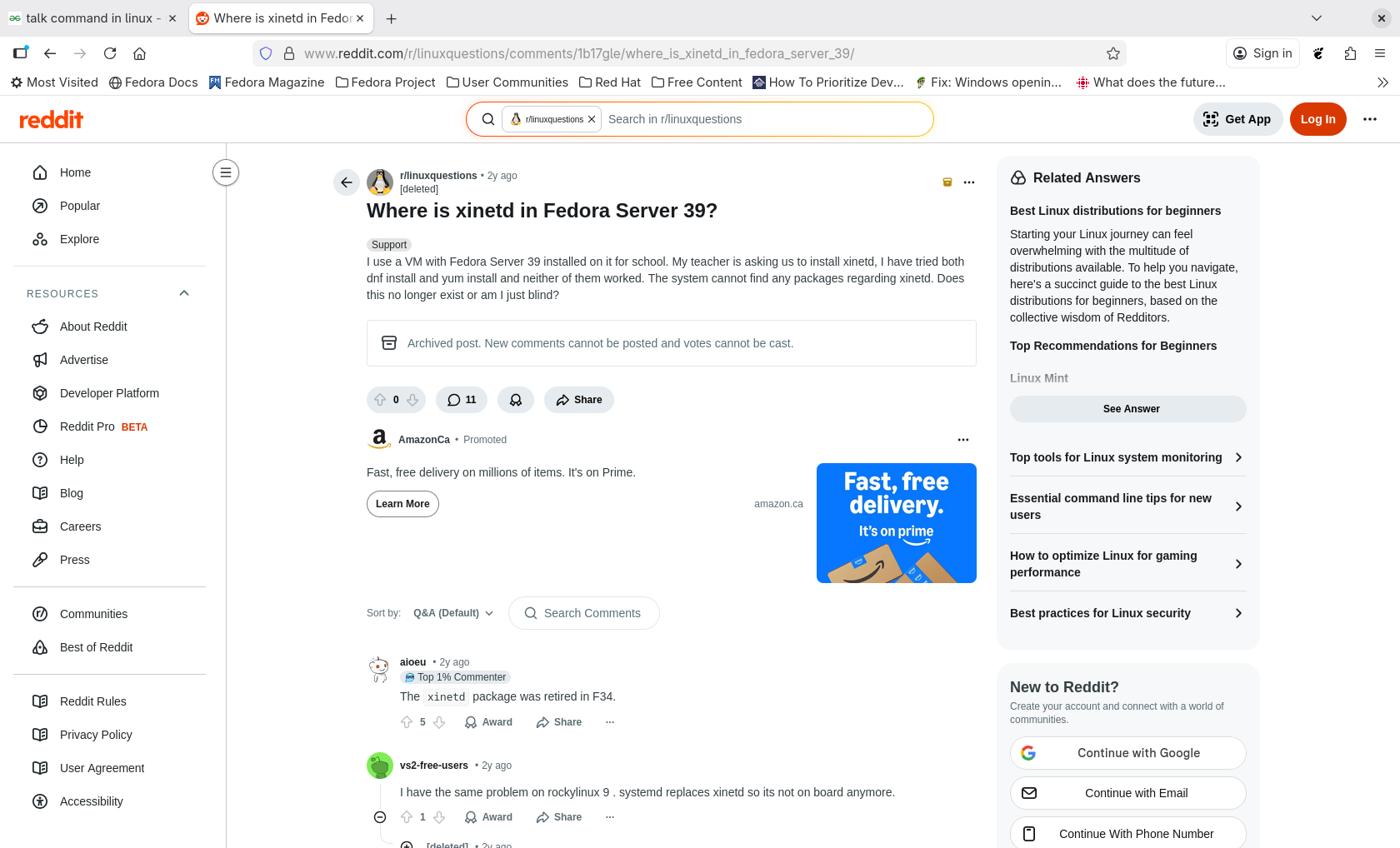
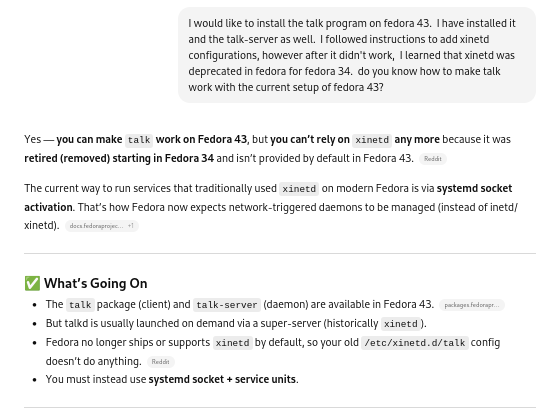
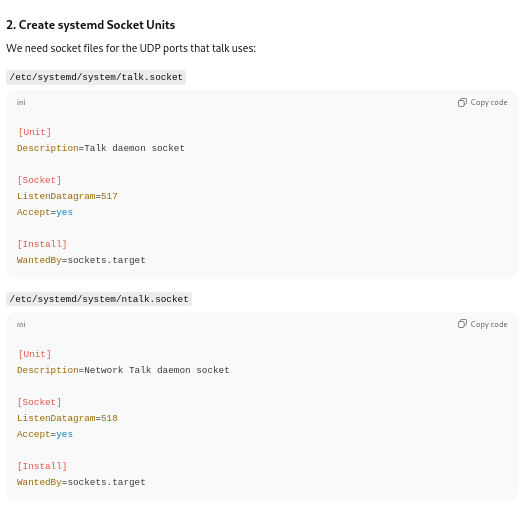
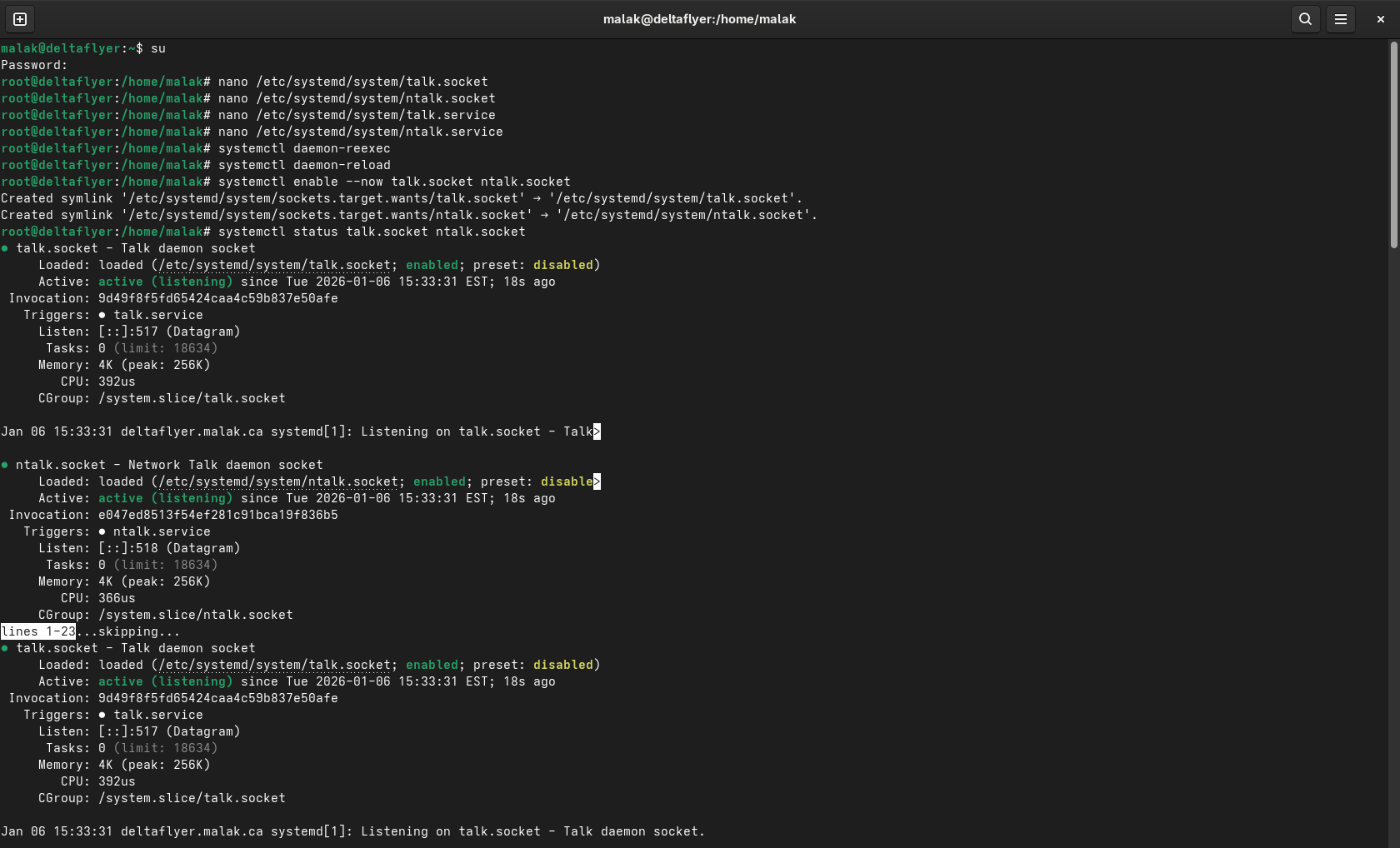
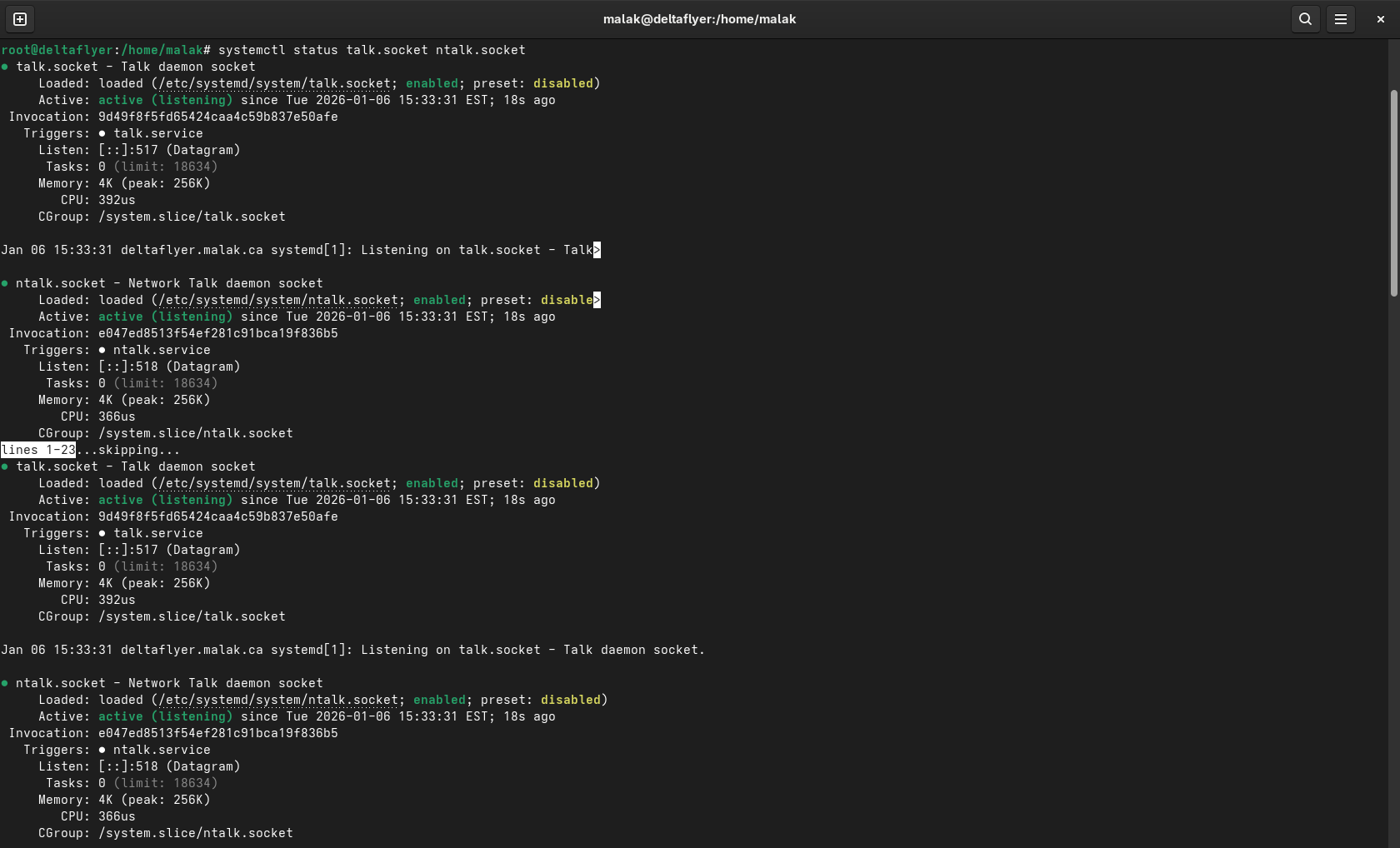
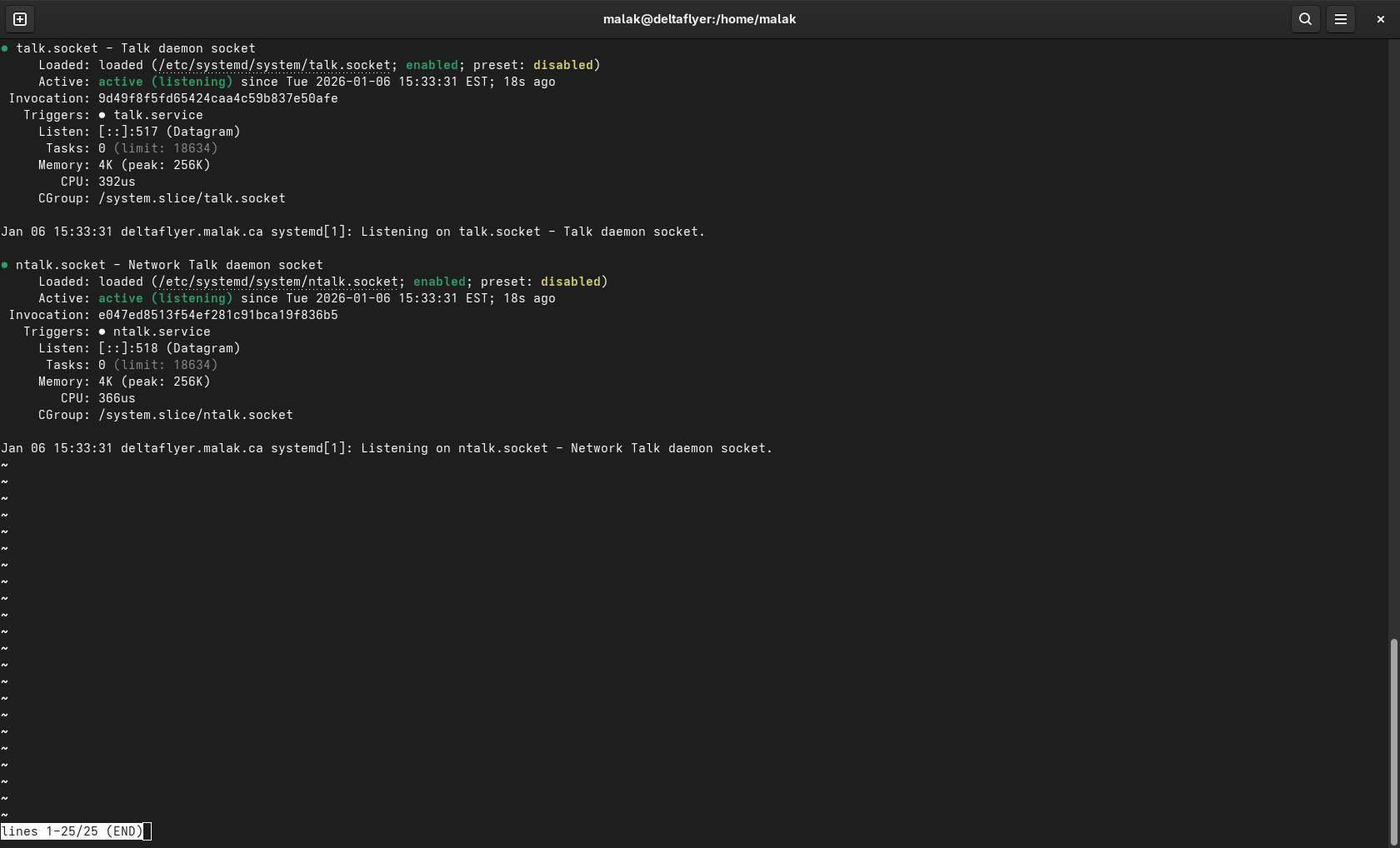
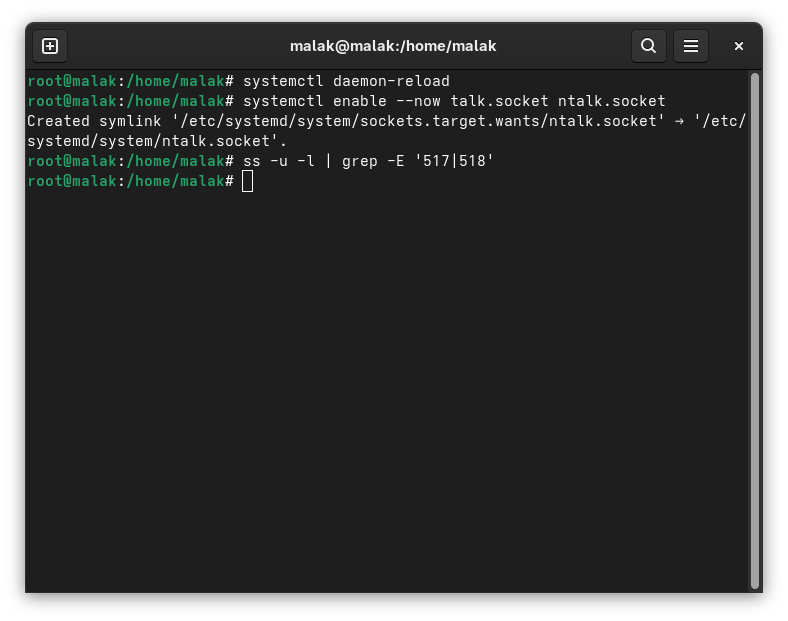
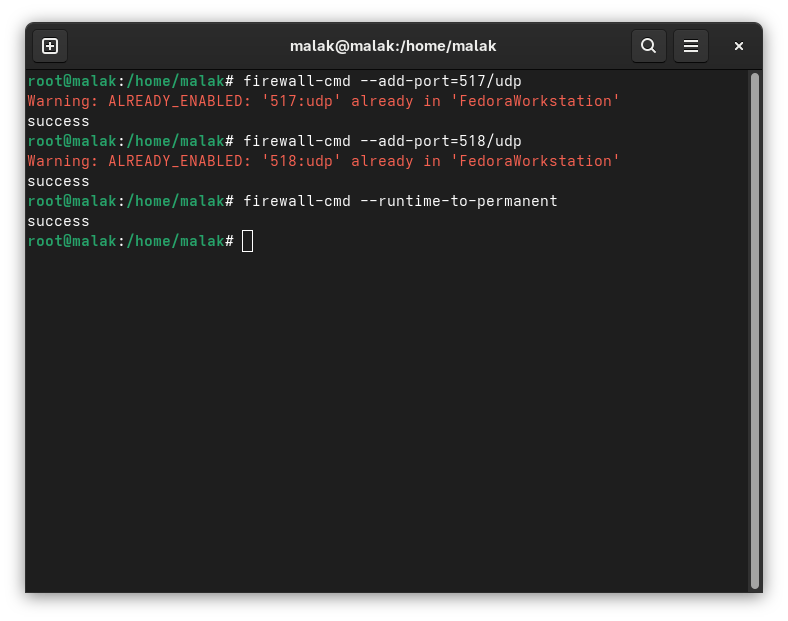
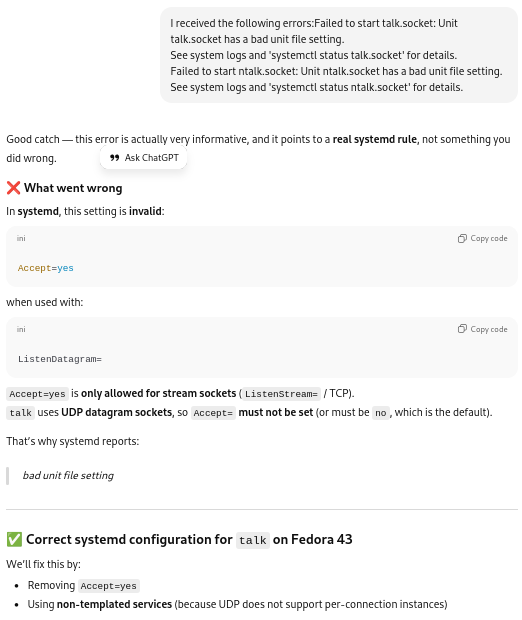
.png)
.png)
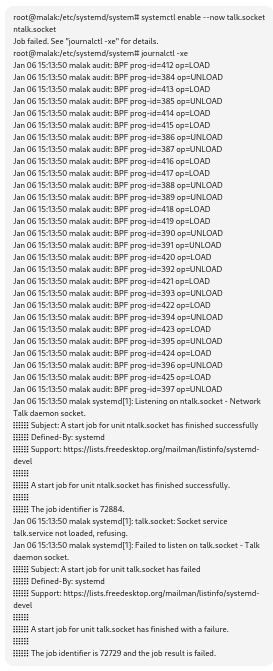
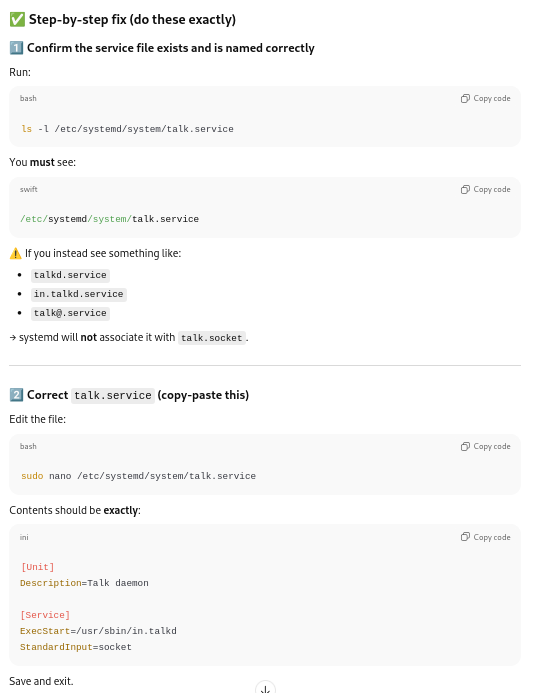
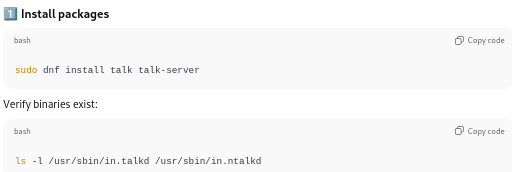
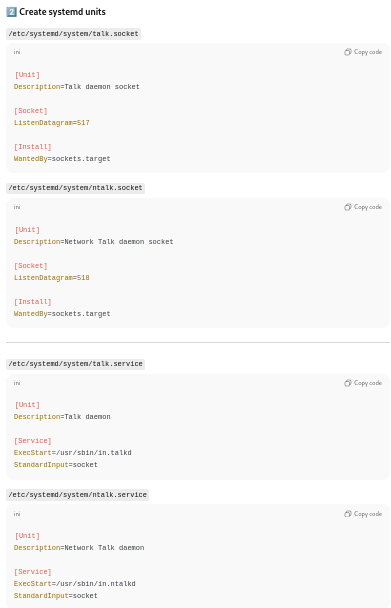
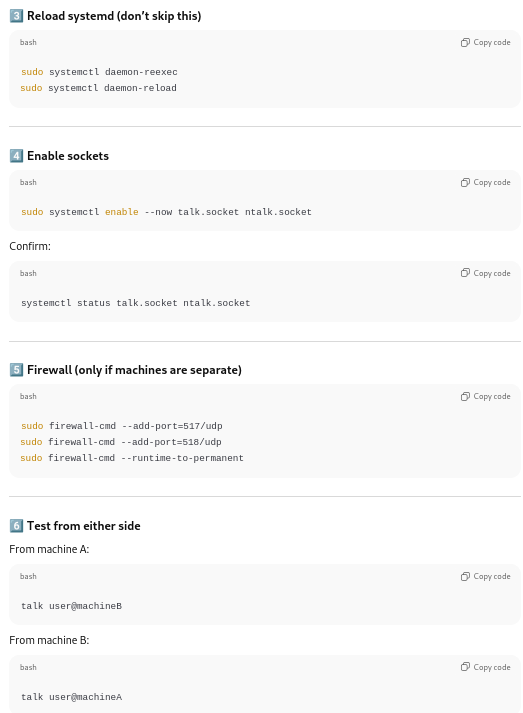
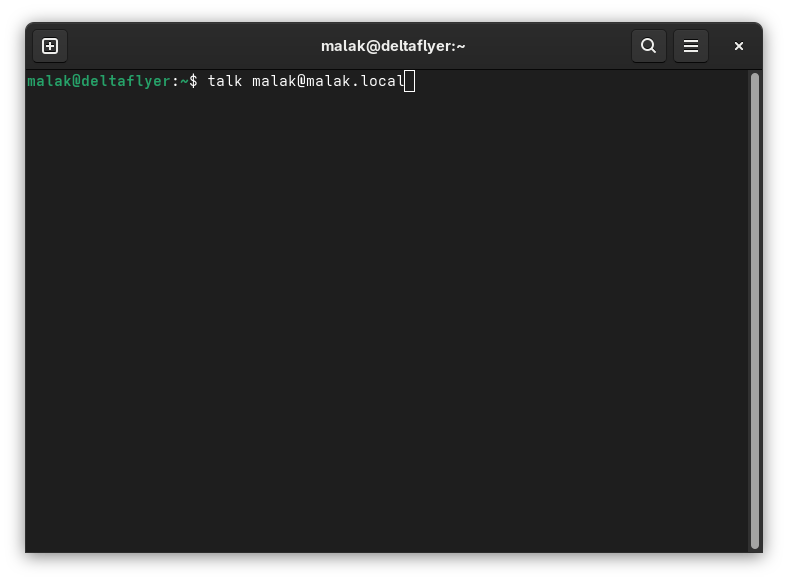
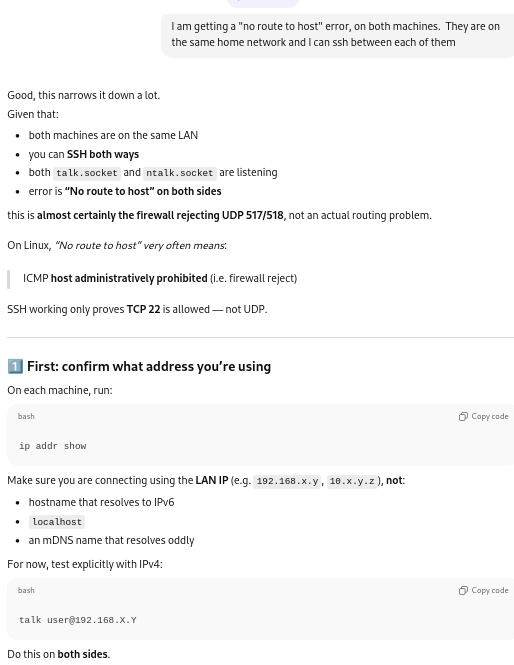
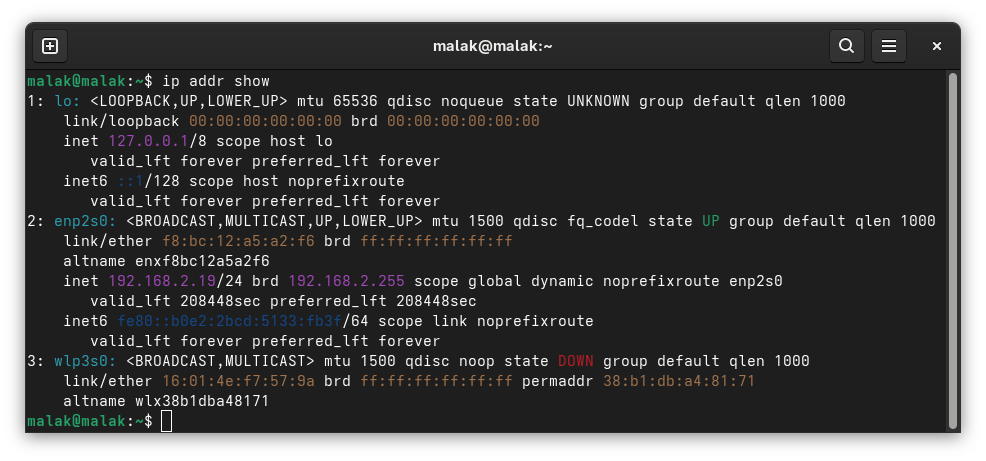
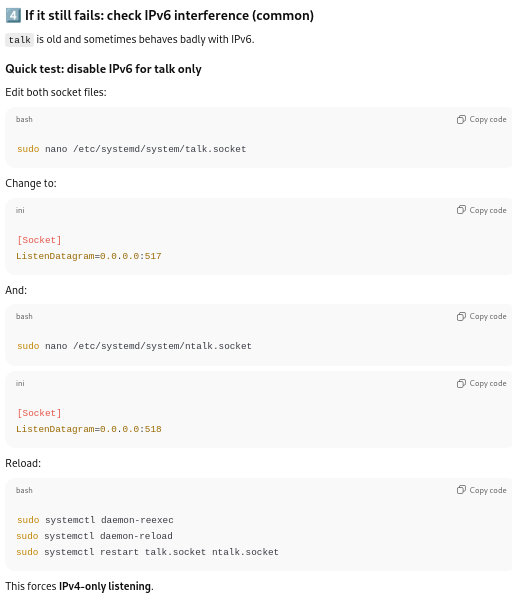
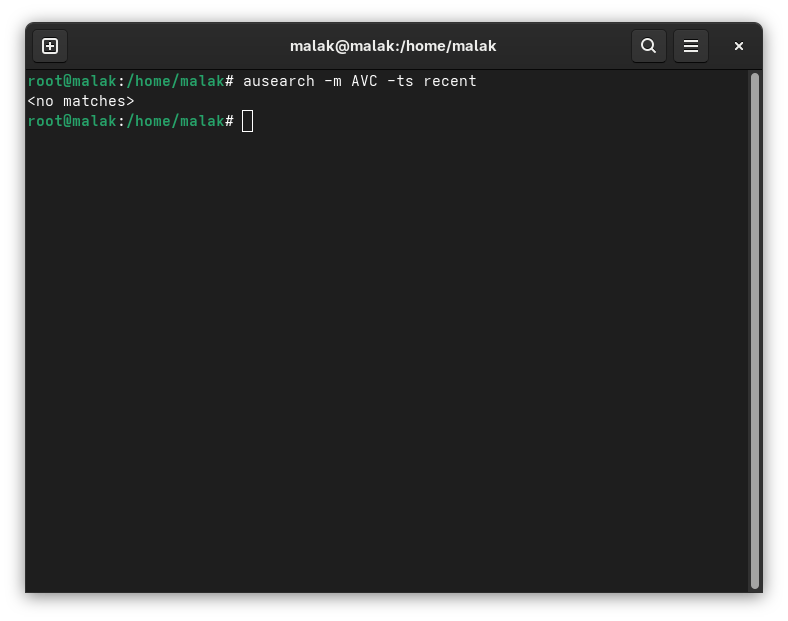
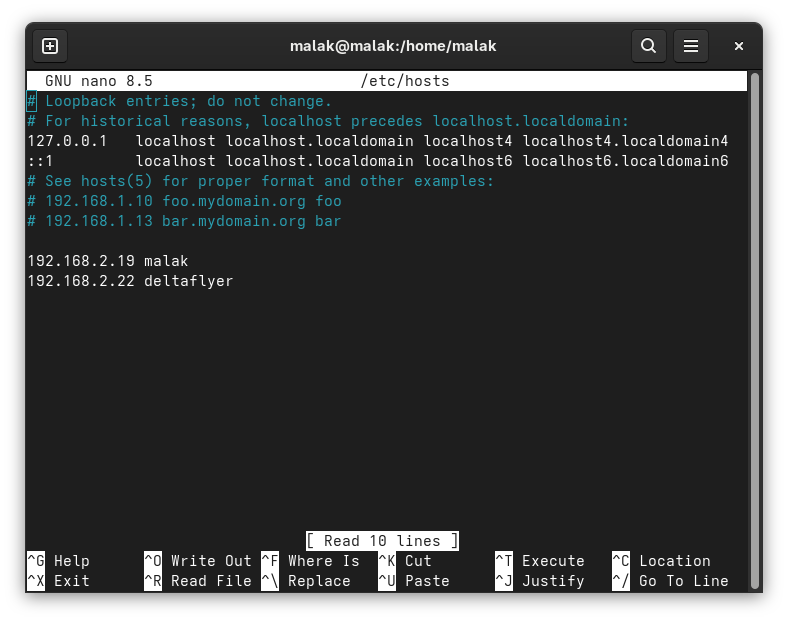
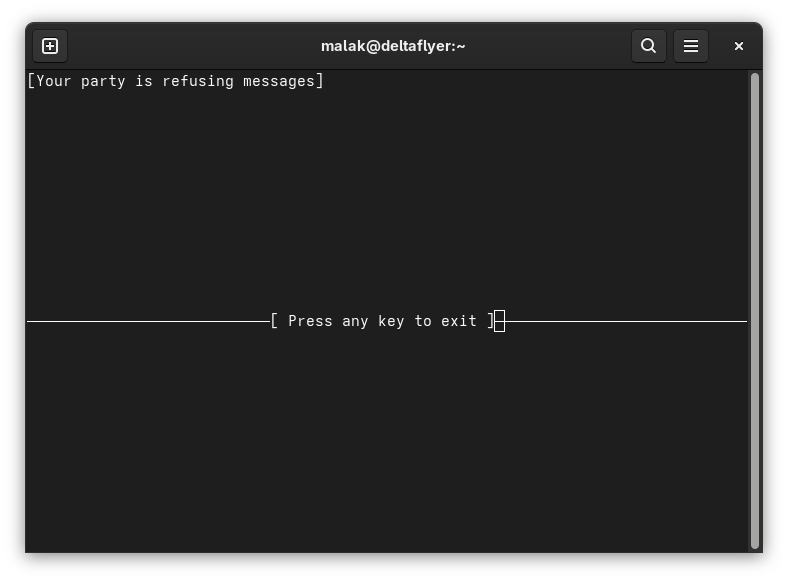

.png)
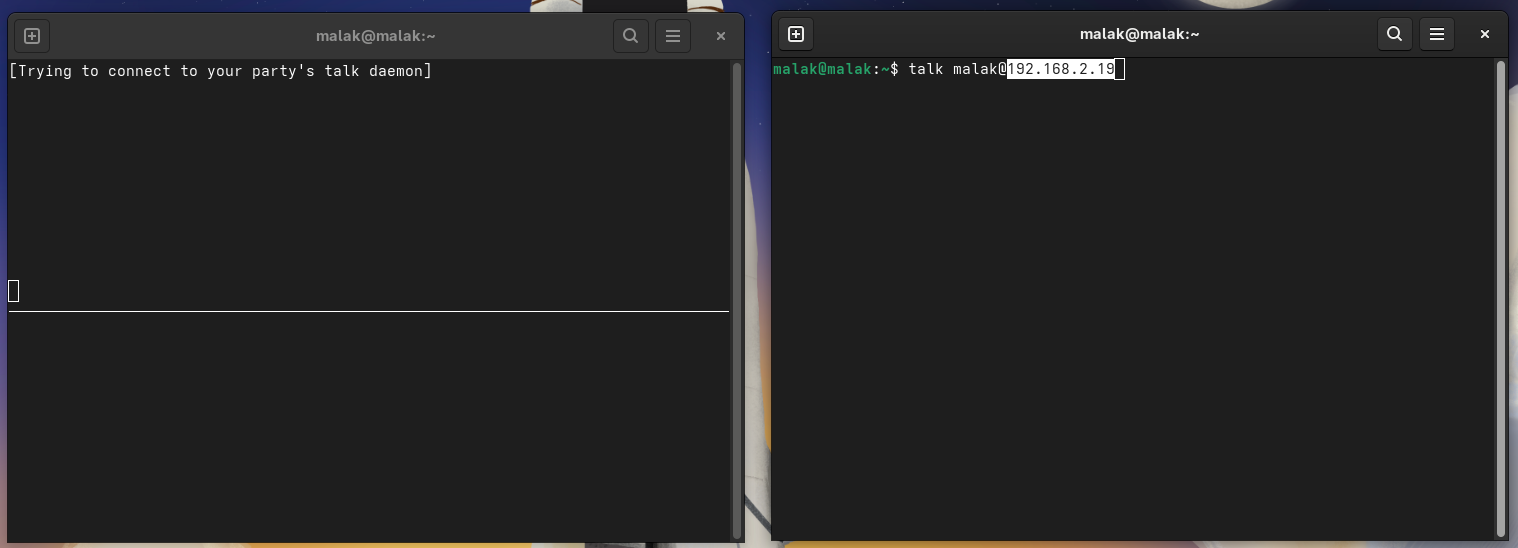
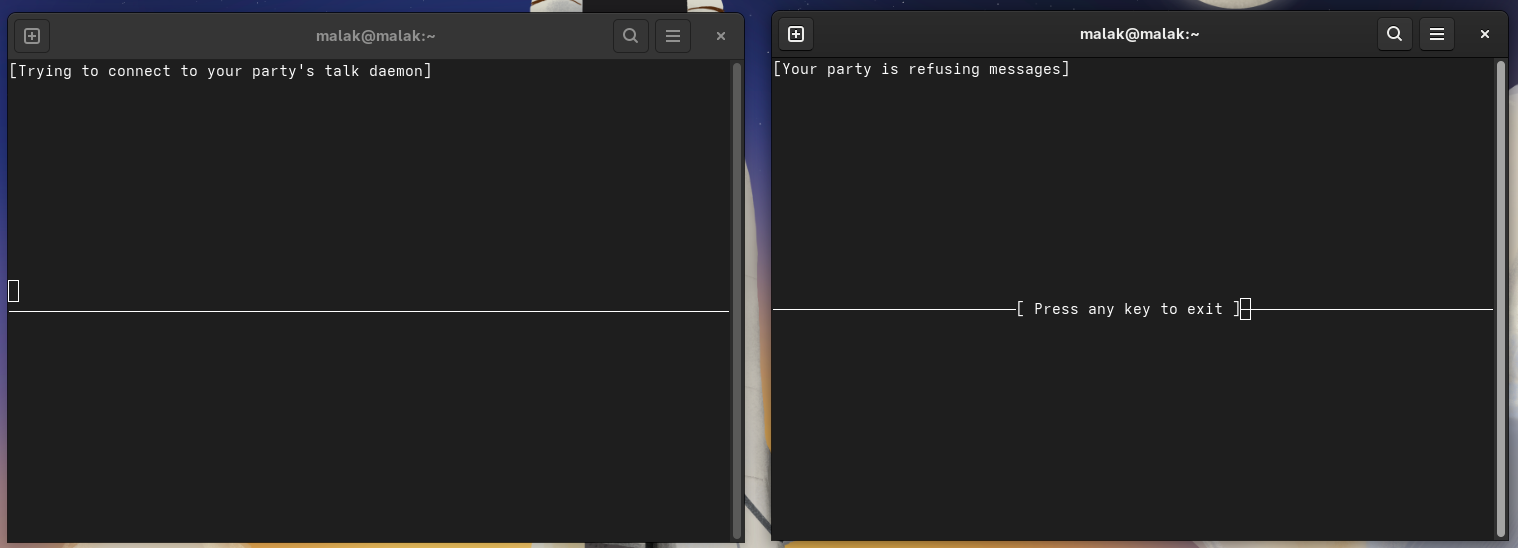
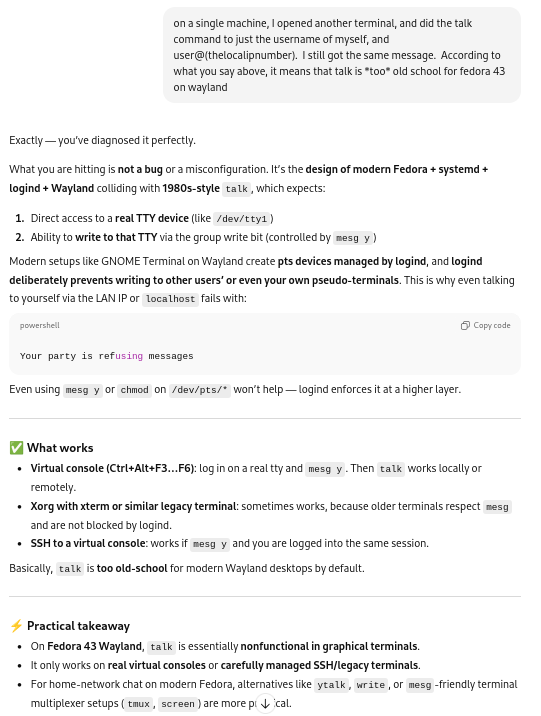
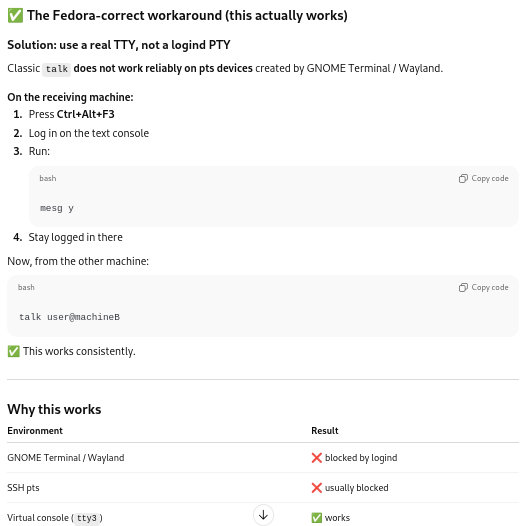
resized.png)
resized.png)
resized.png)
resized.png)
resized.png)
resized.png)